




当我们讨论AGI时,Agent的工作方式无疑占据了技术前沿的中心舞台。随着大模型的快速进步,我们见证了各种新模式的涌现,这些模式不仅提升了llm的效能,更在根本上改变了它们与人类互动的方式。
最近一个月时间,吴恩达在社交媒体上分享了关于AI代理四种工作方式的见解,这些内容不仅洞察深刻,还为AI的应用开辟了新的可能性。他的讨论不仅令人兴奋,更是对所有关注人工智能发展的人士的一次宝贵启示。
接下来,让我们一起探索这些工作方式,并思考它们如何使得AI代理在执行复杂任务时更为高效和智能。
以下是吴恩达的原文:
引言:Agent的四种工作方式
我认为人工智能代理工作流程将在今年推动人工智能的巨大进步——甚至可能超过下一代基础模型。这是一个重要的趋势,我呼吁所有从事人工智能工作的人都关注它。
如今,我们主要在零样本模式下使用 LLM,促使模型逐个生成最终输出token,而无需修改其工作。这类似于要求某人从头到尾写一篇文章,直接打字,不允许退格,并期望得到高质量的结果。尽管有困难,llm在这项任务上表现得非常好!
然而,通过代理工作流程,我们可以要求llm多次迭代文档。例如,它可能需要执行一系列步骤,例如:
- 规划一个大纲。
- 决定需要进行哪些网络搜索(如果需要)来收集更多信息。
- 写初稿。
- 通读初稿,找出不合理的论点或无关的信息。
- 修改草案,考虑到发现的任何弱点。
- 等等。
这个迭代过程对于大多数人类作家写出好的文本至关重要。借助人工智能,这种迭代工作流程比单次编写产生更好的结果。
德文引人注目的演示最近在社交媒体上引起了广泛关注。我的团队一直密切关注编写代码的人工智能的发展。我们分析了多个研究团队的结果,重点关注算法在广泛使用的 HumanEval 编码基准上表现良好的能力。您可以在下图中看到我们的发现。
GPT-3.5(零样本)的正确率为 48.1%。GPT-4(零样本)的表现更好,为 67.0%。然而,从 GPT-3.5 到 GPT-4 的改进与迭代代理工作流程的结合相形见绌。事实上,在代理循环中,GPT-3.5 的成功率高达 95.1%。
开源代理工具和有关代理的学术文献正在激增,这使得这是一个令人兴奋的时刻,但也是一个令人困惑的时刻。为了帮助人们正确看待这项工作,我想分享一个用于对构建代理的设计模式进行分类的框架。我的团队 AI Fund 已在许多应用程序中成功使用这些模式,我希望您发现它们很有用。
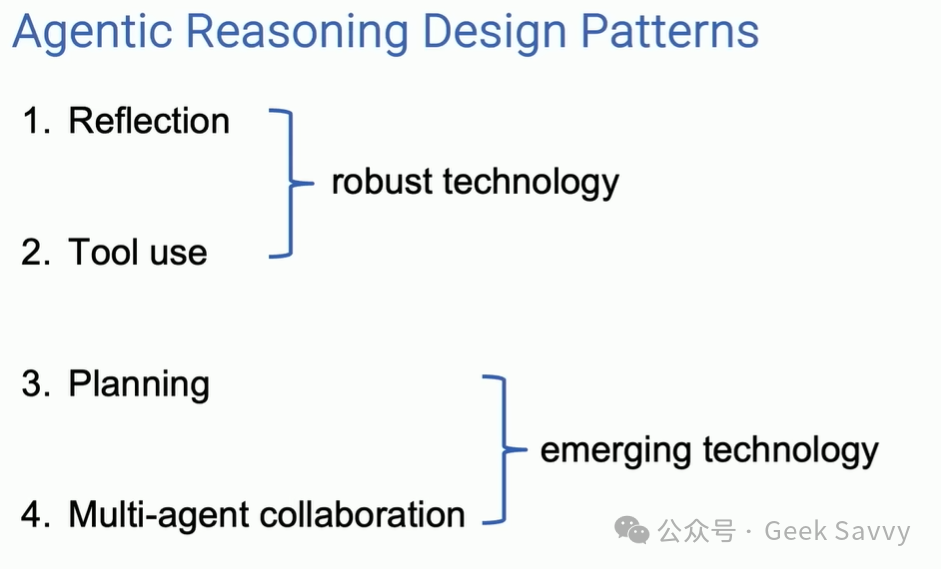
- 反思:llm检查自己的工作,以提出改进的方法。
- 工具使用:法学硕士拥有网络搜索、代码执行或任何其他功能等工具来帮助其收集信息、采取行动或处理数据。
- 规划:法学硕士提出并执行一个多步骤计划来实现目标(例如,撰写论文大纲,然后进行在线研究,然后撰写草稿,等等)。
- 多智能体协作:多个人工智能智能体一起工作,分配任务并讨论和辩论想法,以提出比单个智能体更好的解决方案。
我将详细阐述这些设计模式,并为下周的每一周提供建议的读物。
[原文:https://www.deeplearning.ai/the-batch/issue-241/ ]
一、反思
上周,我描述了人工智能代理工作流程的四种设计模式,我相信这些模式将在今年推动重大进展:反思、工具使用、规划和多代理协作。代理工作流程不是让法学硕士直接生成最终输出,而是多次提示法学硕士,使其有机会逐步构建更高质量的输出。在这里,我想讨论一下React。对于实现相对较快的设计模式,我已经看到它带来了令人惊讶的性能提升。
您可能有过提示 ChatGPT/Claude/Gemini、收到不满意的输出、提供关键反馈以帮助 LLM 改进其响应,然后获得更好响应的经历。如果您自动执行提供关键反馈的步骤,以便模型自动批评自己的输出并改进其响应,会怎么样?这就是反思的关键。
接受要求法学硕士编写代码的任务。我们可以提示它直接生成所需的代码来执行某些任务X。之后,我们可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3225
3225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









