




1、什么是 Agent
Agent是一种能够在一定程度上模拟人类智能行为的软件实体,它具有感知环境、做出决策和执行动作的能力。Agent可以在预定的规则和目标下自主操作,与用户或其他Agent进行交互,完成特定的任务。
Agent 的火爆起源于一个开源的 AI Agent 实践——AutoGPT的出圈,顾名思义,AutoGPT 就是一个能够基于用户输入的目标需求,自主拆解成多个子目标并自动化运行解决这些问题实现目标需求的“代理机器人”。
2、Agent 的技术原理
2.1 Agent 的架构组成
Agent 架构由如下几个模块组成:
- 分析模块 Profiling Module
- 记忆模块 Memory Module
- 规划模块 Planning Module
- 执行模块 Action Module
这些模块共同构成了基于 LLM 的Agent的基本架构,使Agent能够在各种环境中执行复杂的任务,并以更接近人类的方式进行决策和行动。
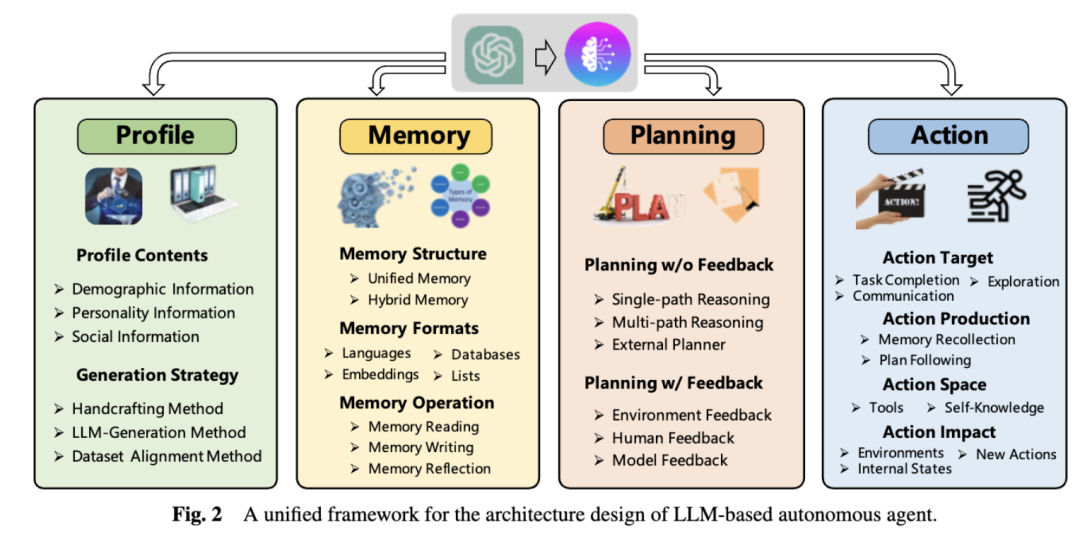
四者之间紧密相关,分析模块的目的是识别代理的角色,记忆和规划模块将代理置于动态环境中,使其能够召回过去的的行为并规划未来的动作。动作模块负责将代理的决策转化为具体的输出。在这些模块中,分析模块影响记忆和规划模块,而这三个模块共同影响动作模块。
- 分析模块(Profiling Module)
Agent通常通过承担特定角色来执行任务,例如编码员、教师和领域专家。分析模块旨在指示Agent角色的特征,这些特征通常被写入提示中以影响大模型的行为。Agent特征通常包括年龄、性别和职业等基本信息,以及反映Agent个性的心理信息和详细说明代理之间关系的社会信息。分析Agent的信息选择在很大程度上取决于具体的应用场景。例如,如果这一 Agent 应用旨在研究人类认知过程,那么心理信息就至关重要。
那么如何为Agent创建指定特征呢,通常,有如下两种策略。
1. 手动输出
手动输出的原理和给LLM提示以指定一个角色同理,可以理解为自己撰写这段角色的Prompt,由此指定 LLM 的角色身份,让它能够基于这一角色领域的内容来回答你的问题,让其参考资料更为精确具体和垂直。如,指定一个身份,eg.政治家、记者、专业一流的程序员、产品经理、战略咨询专家,同时可以更细化的指明他擅长的技能,eg.深喑企业战略咨询知识,能够从第一性原理出发解析用户提出的需求本质指向,由此提出全方位的解决方案建议等等。
2. 借助LLM生成
这一方法适用于多Agent场景,借助 LLM 帮助生成能极大程度的提高效率。当有多个 Agent 需要指定角色信息时,我们可以先从指示个人资料生成规则开始,阐明目标人群中代理个人资料的构成和属性,随后指定一些种子信息,如年龄、性别、个人特质和电影偏好,随后借助 LLM 帮助我们生成多个种子信息差异化的角色,由此进一步拓展生成更多的信息。但这一方法取决于我们指示 LLM 生成的 Prompt 质量和 LLM 本身的能力,鉴于当前 LLM 的幻觉等缺陷,可能无法对生成的内容进行精确控制。
- 记忆模块(Memory Module)
通常,LLM 是记录用户自然语言沟通状态的,就类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2454
2454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









