



引言
为什么需要本地知识库? 在当今信息爆炸的时代,高效获取和管理网站内容成为许多研究者、开发者和内容创作者的迫切需求。无论是进行 竞品分析、构建 文档库,还是创建 私有问答系统,都需要一套高效的工具来完成从网页爬取到知识库构建的全流程。本文将详细介绍如何利用 FireCrawl 的Playground功能爬取网站内容,并使用 CherryStudio构建本地知识库,整个过程 无需编写一行代码,适合各类用户快速上手。我们将以流行的开源AI编程智能体 Cline的文档网站为例,展示从爬取到构建知识库的完整流程。
工具介绍与优势分析:FireCrawl与CherryStudio的强大组合
FireCrawl:智能网页爬取工具的首选
FireCrawl是一款强大的AI网页爬虫工具,专为处理动态网页内容而设计。与传统爬虫工具相比,FireCrawl具有以下显著优势:
- 零代码操作:通过Playground界面,只需输入网址即可启动爬取
- 智能内容识别:自动识别网页主体内容,过滤导航栏、广告等无关元素
- 多格式输出:支持Markdown、HTML等多种格式导出,便于后续处理
- 递归爬取:自动发现并爬取网站内的所有链接页面
- 动态内容支持:能够处理JavaScript渲染的动态内容
CherryStudio:打造个人专属知识库的理想工具
CherryStudio是一款具备本地知识库构建功能的全能AI助手平台,支持多种数据源导入和向量化处理:
- 多种文件格式:支持PDF、DOCX、TXT、MD等多种文件格式
- 本地部署:数据存储在本地,保障隐私安全
- 向量化检索:基于语义的智能检索,而非简单的关键词匹配
- 多模型支持:支持接入多种大语言模型,如DeepSeek等
- 可视化操作:拖拽式界面,无需编程经验
工具组合的优势:完整的网站内容知识化解决方案
FireCrawl与CherryStudio的组合使用,形成了一套完整的"网站内容→本地知识库"解决方案:
- 全流程无代码:从爬取到知识库构建,全程图形界面操作
- 数据格式兼容:FireCrawl输出的Markdown文件可直接导入CherryStudio
- 私有化部署:全流程可在本地完成,无需担心数据泄露
- 定制化程度高:可根据需求调整爬取范围和知识库配置
使用FireCrawl Playground爬取Cline文档网站:详细步骤指南
FireCrawl Playground介绍:无代码爬虫的理想选择
FireCrawl Playground是FireCrawl提供的可视化操作界面,无需编写代码即可完成网站爬取。它提供了两种主要模式:
- Map模式:快速获取网站的链接地图,了解网站结构
- Crawl模式:深度爬取网站内容,并转换为结构化数据
Map模式:获取Cline文档网站结构的第一步
- 访问FireCrawl Playground:首先在Firecrawl网站注册登陆,然后打开 FireCrawl Playground,网址为 https://www.firecrawl.dev/app/playground ,如下图所示,选择Map模式。
 FireCrawl Playground界面
FireCrawl Playground界面
- 输入目标网址,启动Map任务:如下图所示,在URL输入框中输入Cline文档网站地址
https://docs.cline.bot/,点击"Run"按钮开始获取网站链接地图
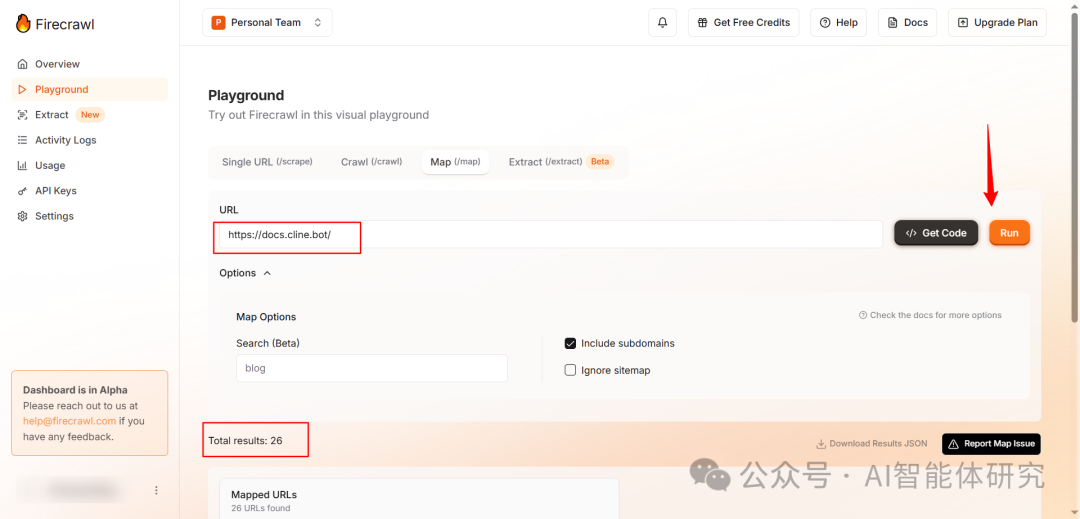 输入目标网址
输入目标网址
- 查看结果:系统将显示网站的所有链接和总计数,如上图显示的26个,这个就是我们下一步需要批量爬取的最大网页链接数。
Crawl模式:深度爬取Cline文档内容的核心步骤
- 切换到Crawl模式:在模式菜单中选择"Crawl",如下图所示
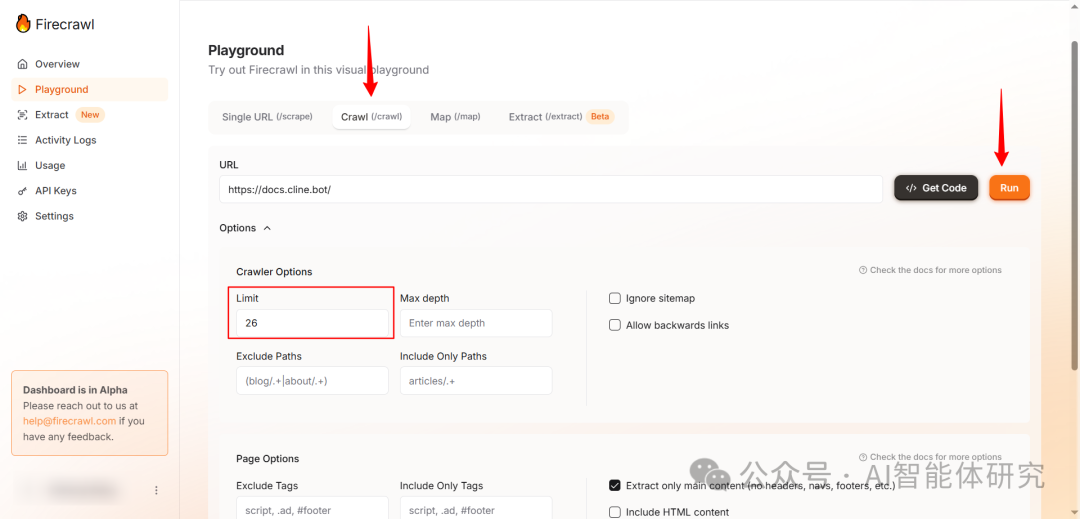 切换到Crawl模式
切换到Crawl模式
-
配置Crawl参数,启动Crawl任务:
-
- URL:保持
https://docs.cline.bot/不变 - 页面限制(Limit):根据Map结果设置适当的数值,如26
- 输出格式(Formats):默认输出markdown格式,方便后续导入CherryStudio
- 仅主要内容(Extract Only Main Content):建议勾选,以过滤导航栏等无关内容
- 包含/排除路径:默认为空,表示爬取所有路径
- 点击"Run"按钮开始爬取
- URL:保持
-
下载爬取结果:爬取完成后,点击"Download"按钮下载所有Markdown文件的压缩包
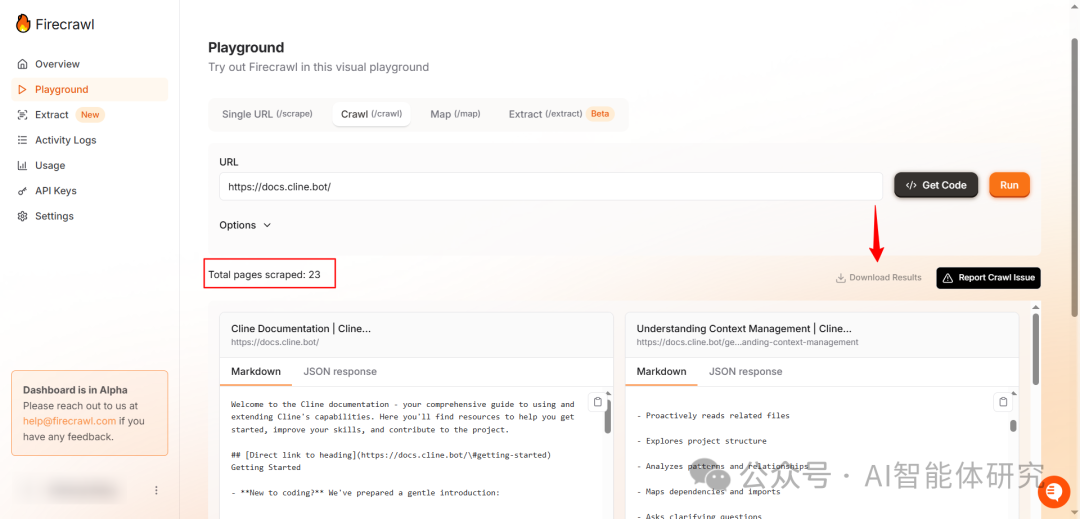 下载爬取结果
下载爬取结果
爬取结果分析:FireCrawl的高质量输出
成功爬取后,您将获得一个包含多个Markdown文件的压缩包,解压后的文件列表如下图所示:
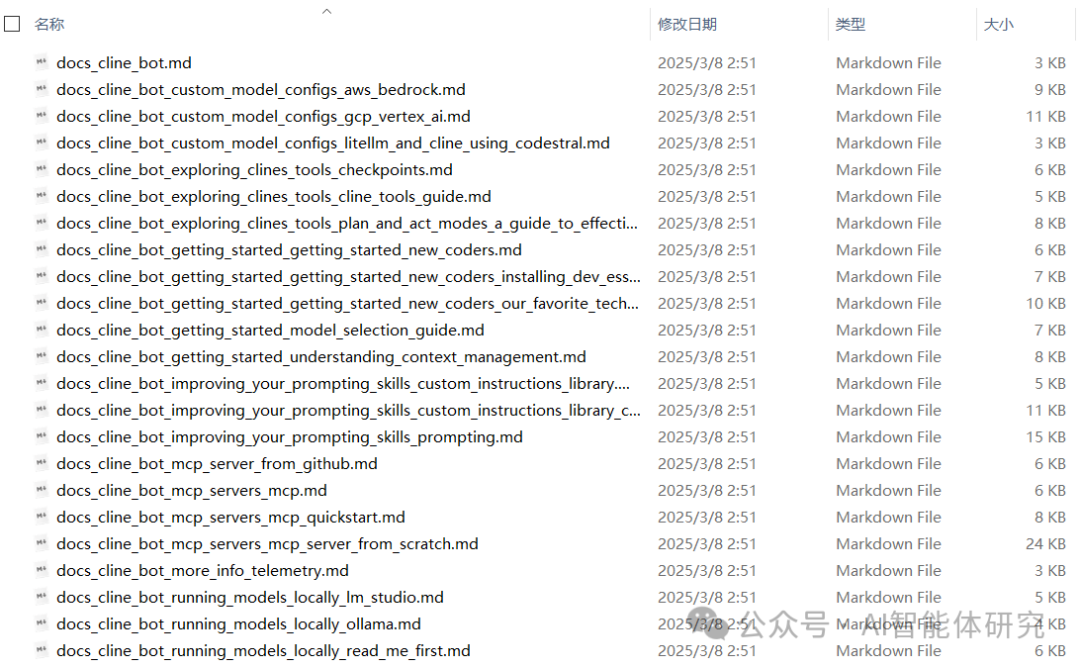 爬取结果文件列表
爬取结果文件列表
每个文件对应Cline文档网站的一个页面。文件内容保留了原网页的结构和格式,包括:
- 标题层级:保持原网页的标题结构
- 文本段落:完整保留原文内容
- 代码块:保持代码格式和语法高亮
- 列表:保留有序和无序列表格式
- 表格:保持表格结构和内容
这些Markdown文件是构建知识库的理想素材,保留了原始内容的结构化特性,同时去除了网页中的干扰元素。
使用CherryStudio构建Cline文档知识库:从文件到智能问答系统
CherryStudio安装与配置:快速上手指南
-
下载安装CherryStudio:访问CherryStudio官网,网址为:https://cherry-ai.com/ ,下载适合您操作系统的版本
-
首次启动配置:
-
- 添加模型服务:如下图所示,点击左下角设置图标,选择"模型服务"
- 添加嵌入模型:以硅基流动为例,点击下方的"管理"按钮,如下图所示,在设置中选择"嵌入模型",添加如"BAAI/bge-m3"等嵌入模型
- 验证模型连接:在硅基流动的设置页面,输入API密钥,点击"检查"按钮,确保模型连接状态正常
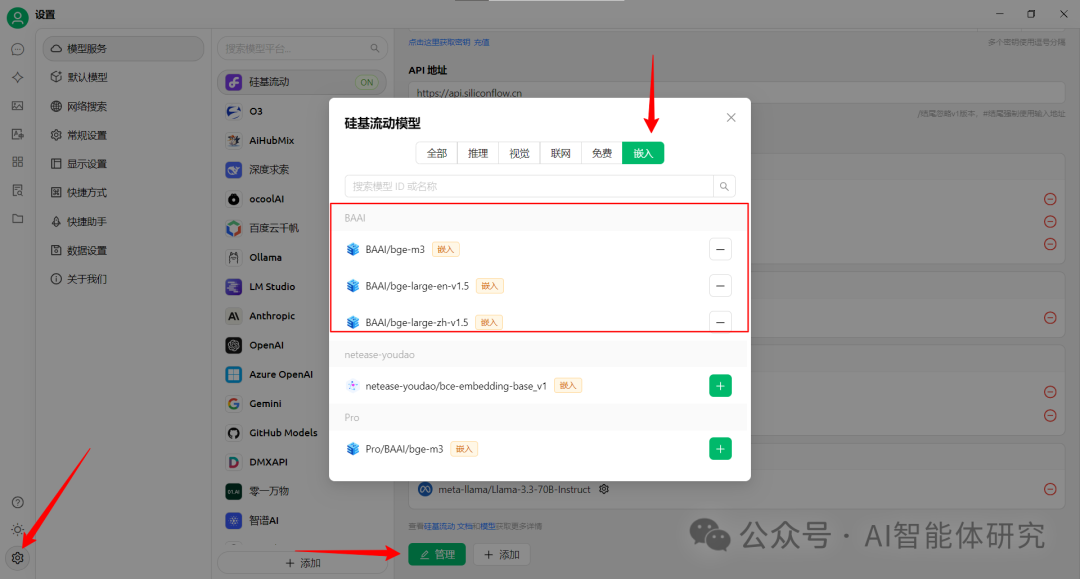 CherryStudio模型设置界面
CherryStudio模型设置界面
创建知识库:打造专属Cline文档库
-
进入知识库界面:如下图所示,点击CherryStudio左侧工具栏的"知识库"图标
-
创建新知识库:
-
- 点击"添加知识库"按钮
- 输入知识库名称,如"Cline使用手册"
- 选择嵌入模型,如"BAAI/bge-m3",点击"确定"完成创建
- 注意知识库设置有个"请求文档分段数量"的设置,默认为6条,如果需要访问知识库的是否返回更多条目数,可以调整这个参数
 创建新知识库
创建新知识库
导入FireCrawl爬取的Markdown文件:数据入库
-
添加文件到知识库:
-
- 如下图所示,在知识库界面,点击"添加文件"
- 选择解压后的Markdown文件,可多选或全选
- 或直接将整个文件夹拖拽到添加区域
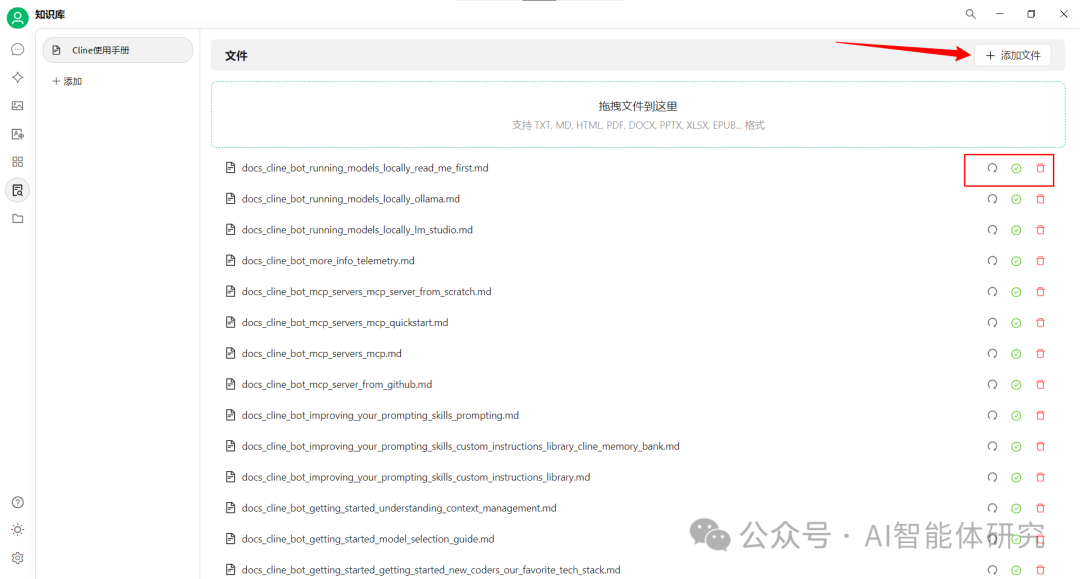 添加文件到知识库
添加文件到知识库
-
等待向量化处理:
-
- 系统会自动进行文件向量化
- 如上图所示,文件旁显示进度条,完成后会出现绿色勾号
- 大型文档可能需要几分钟处理时间
知识库使用与测试:体验智能问答的魅力
-
创建新对话:点击左侧"+"创建新对话
-
启用知识库:
-
- 点击对话工具栏中的"知识库"图标
- 选择刚创建的"Cline文档知识库"
-
测试知识检索:
-
- 在对话框中输入与Cline相关的问题,如"如何安装Cline?"
- 发送问题,系统会基于知识库内容生成回答
- 如下图所示,回答下方会显示引用的数据来源,可点击查看原文
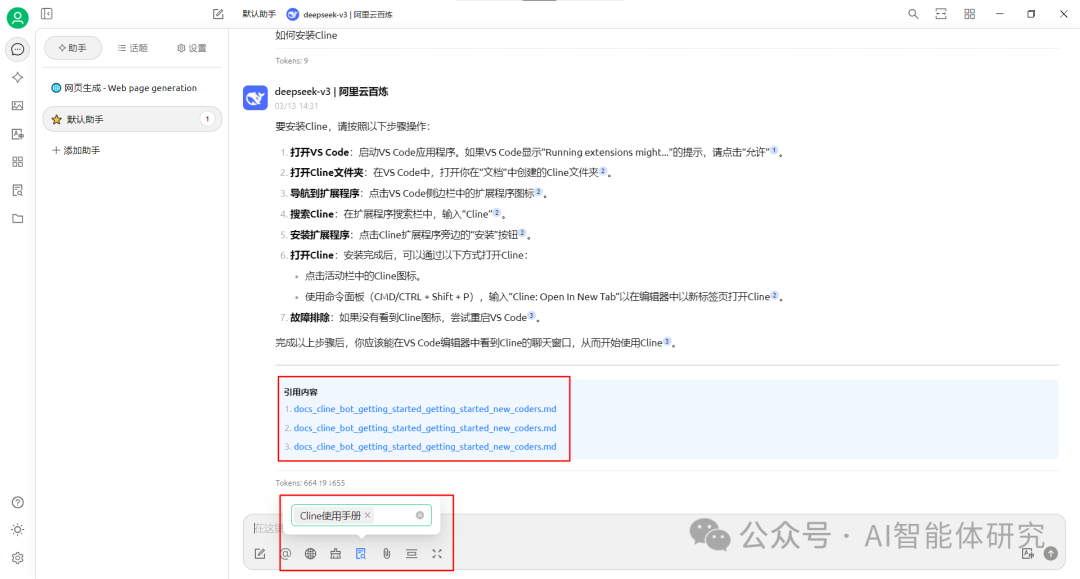 知识库问答效果
知识库问答效果
-
评估知识库效果:
-
- 测试多种问题类型,评估知识库的覆盖范围
- 检查回答准确性,必要时调整知识库内容
优化与进阶应用:提升知识库质量的专业技巧
FireCrawl爬取优化:精准获取目标内容
-
精细化爬取范围:
-
- 使用includes参数限定特定路径,如仅爬取"/api/"下的文档
- 使用excludes参数排除不需要的内容,如"/blog/"
-
内容过滤优化:
-
- 使用includeTags参数保留特定HTML标签内容
- 使用excludeTags参数排除特定HTML标签内容
CherryStudio知识库优化:提升检索质量
-
文件预处理:
-
- 对爬取的Markdown文件进行必要的清理和格式化
- 合并相关内容,提高检索效率
-
多知识库组合:
-
- 创建多个主题知识库,如"API文档"、"入门指南"等
- 根据问题类型灵活切换不同知识库
实际应用场景:知识库的多元价值
- 技术支持系统:将产品文档构建为知识库,快速回答用户问题
- 研究资料库:爬取行业网站,构建专业领域知识库
- 竞品分析:爬取竞争对手网站,构建竞品信息库
- 学习辅助工具:将教程网站转化为个人学习知识库
结论
通过本文的详细指南,我们展示了如何利用FireCrawl Playground和CherryStudio这两款强大工具,实现从网站内容爬取到本地知识库构建的全流程。整个过程无需编写代码,通过简单的图形界面操作即可完成,大大降低了技术门槛。以Cline的文档网站为例,我们成功将其转化为结构化的本地知识库,实现了高效的内容管理和智能检索。
这种方法不仅适用于技术文档,还可以应用于各种网站内容的采集和知识化管理。随着AI技术的发展,这类工具将变得更加智能和易用,为知识管理和信息获取带来更多可能性。无论是个人学习、团队协作还是企业应用,这套工具组合都能显著提升信息处理效率,助力用户在信息海洋中精准获取所需知识。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 9562
9562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









