



摘 要: 针对传统RAG 在关联分析、信息整合与逻辑推理能力等方面存在的局限性,以知识图谱与RAG为研究对象,分析国内外研究进展与应用案例。ChatLaw 引入领域专家精准定义法律实体、关系与案例,通过高质量知识图谱提升法律咨询的准确性。GraphRAG 采用知识图谱表示非结构文本中实体与关系,通过层次聚类、摘要生成等技术提升RAG 在大规模数据集上全局搜索能力。HippoRAG 在查询阶段利用知识图谱进行概念扩展和检索,提升RAG 知识整合与多跳推理能力。归纳RAG 与知识图谱融合方法,在数据分块、数据存储、查询优化、检索召回、重排、提示词构建、答案生成等阶段引入知识图谱,可以提升RAG 准确率、关联分析能力、推理能力与可解释性。基于Lucene、LangChain 等开源框架设计全文检索、向量检索、图谱检索3 套方案,将其应用于油气知识问答场景,验证知识图谱对增强RAG 的有效性。
关键词: 大语言模型;检索增强生成;知识图谱;向量数据库;图数据库
大语言模型(Large Language Model,LLM) 从海量训练数据中学习世界知识,并将其存储到模型参数中,具有强大的自然语言理解能力与文本生成能力。然而,纯参数化的LLM 在准确性、答案透明度、数据可控性、知识更新速度等方面仍面临诸多挑战。检索增强生成(Retrieval-Augmented Generation,RAG)将非参数化知识库与参数化语言模型相集成,为LLM 提供可动态更新的外部知识源信息,增强其文本生成能力。RAG 在一定程度上缓解了大模型“幻觉”、知识“时效性”、数据隐私等问题,受到了学术界和工业界的广泛关注,成为当前大模型应用落地最普遍、最有效的模式。
RAG 技术发展主要包括Naive RAG、AdvancedRAG、Modular RAG 3 个阶段。Naive RAG 是最早的研究范式, 包括索引、检索和生成3 个步骤。Advanced RAG 对Naive RAG 进行改进,在检索阶段使用滑动窗口、细粒度分割、元数据等优化策略提高检索效率,在生成阶段使用信息压缩、重排序等方法提升生成质量。Modular RAG 改变了Naive RAG 固有的检索与生成流程,采用模块化方法对RAG 流程进行设计和编排,具有更强的灵活性与多样性,已经成为RAG 领域的主流。无论RAG 范式如何演变,对外部知识的存储、索引与检索始终是RAG 的重要组成部分。
在大模型时代,向量是数据的主要表现形式,例如文本向量、图像向量、语音向量等。传统数据库采用文本匹配、TF-IDF、BM25 等算法实现搜索功能,无法对大规模、高维度、多模态的向量数据进行高效存储和检索。为此,向量数据库应运而生,成为RAG 系统中非参数化知识存储与检索的首选方案。当处理用户请求时,RAG 系统首先从向量数据库中检索与用户问题高度相关的数据片段,然后将这些附加上下文填充到提示模板中以增强大模型输入,最后经由LLM 生成符合事实性的回答。但是,向量检索具有模糊性,仅仅通过语义相似性搜索很难捕获数据之间的复杂关系与属性,在知识密集型行业应用效果并不理想。知识图谱(Knowledge Graph,KG) 是一种基于图的数据结构,采用实体、属性和关系对领域知识进行建模,能够进行精准匹配与多步推理,是实现知识共享、融合和挖掘的重要手段。因此,利用知识图谱提升RAG 性能已经成为很多科研机构的研究热点,为知识图谱与大模型的融合提供了可参考的集成方案。
本文以知识图谱与RAG 为研究对象,分析国内外相关研究成果与应用案例,给出了知识图谱在RAG 不同阶段的应用方案。最后以油气领域知识问答为例,验证知识图谱对提升RAG 性能的有效性。
1 知识图谱与RAG 技术概述
数据、算法和算力是人工智能技术的关键要素,数据即是基础性资源,也是战略性资源。中国石油天然气集团有限公司(简称中国石油) 经过数十年的勘探开发,积累了海量的业务数据与成果报告。在这些数据资源中,80% 以上为非结构化数据,质量参差不齐、处理难度大、隐藏在数据中的信息与知识尚未得到有效挖掘和利用,数据利用率低、知识共享程度低。虽然部分企业建立了知识库系统,提供文档查询和全文检索功能,但是无法将分散在各个文档中的知识点进行关联与整合,智能化程度低。
知识图谱构建包括本体建模、知识映射、文档解析、知识抽取、知识融合、图数据库存储等步骤,为语义检索、智能问答、方案推荐等应用场景提供支持。图1 给出了基于知识图谱的问答流程,当接收到用户问题时,首先对问题进行解析,提取出实体和关系,然后从图数据库中召回子图,通过计算子图与问题相关性,获取问题答案。
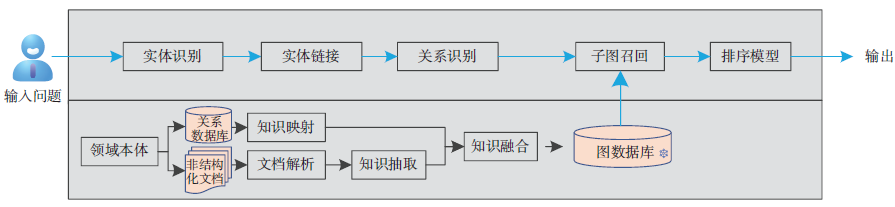
图1 基于知识图谱的问答流程
知识图谱一般面向特定领域,通用性和泛化能力弱,当用户问题表述不清或者超出知识库范围时,容易出现无法回答现象。大语言模型通过大规模的预训练和微调,从海量语料库中学习丰富的语义知识和语言表达能力, 与用户实现自由对话(图2)。

图2 基于大模型的问答流程
训练数据质量差、错误信息、过时信息、偏见,以及推理过程的不确定性等问题都可能导致大模型产生“幻觉”,输出错误答案。RAG 技术是一种结合检索和生成的知识增强方案,利用外部知识库辅助大模型生成过程, 确保生成内容的准确性和鲁棒性(图3)。
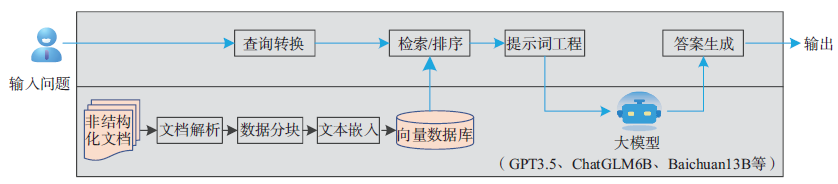
图3 基于RAG 的问答流程
2 知识图谱增强RAG 案例分析
石油工业是多学科交叉的知识密集型行业,对RAG 系统性能的要求相对较高。传统RAG 技术虽然可以实现对大规模非结构化数据的高效存储与检索,但是在精准预测、关联分析、信息整合、逻辑推理方面无法满足油气行业需求。为此以知识图谱提升RAG性能为研究对象,调研国内外相关案例,分析其技术方案,为油气行业大模型应用提供参考。
2.1 提升准确率
法律领域问题通常涉及法律的解释和适用,大模型必须正确理解法律规范,才能为用户提供正确的法律引导,否则可能对当事人的人身财产权益造成重大影响。法律语言的复杂性、法律条规的严谨性、条款之间的细微差别,以及立法的动态变化都为法律大模型的落地应用带来挑战。ChatLaw是由北京大学团队发布的开源法律大模型,通过结合法律领域特定的数据集和外部知识库,提高法律咨询服务的准确性和效率。ChatLaw 技术架构包括法律数据集与知识图谱构建、MoE (Mixture of Experts) 大模型构建、多智能体协作框架3 个部分(图4)。
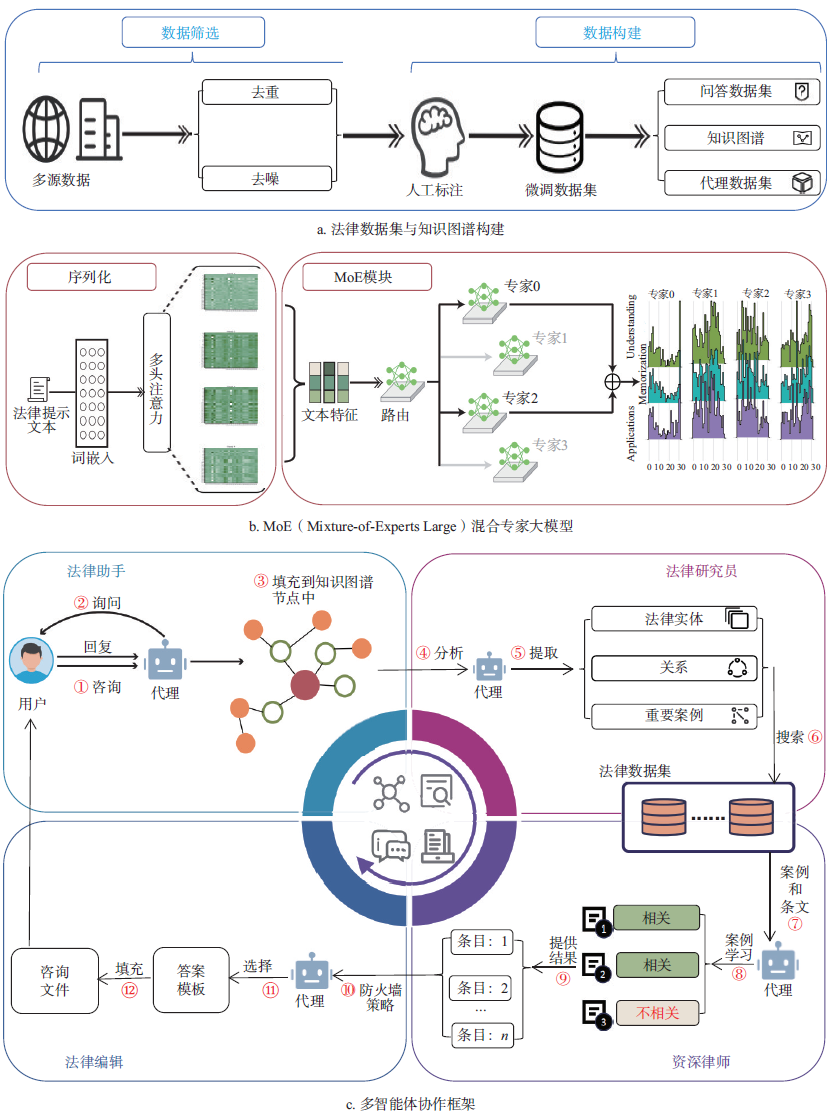
图4 ChatLaw 技术架构
首先使用自动化工具对收集的多源数据(法律法规、司法解释、法律新闻、法律论坛、法律咨询等)进行去重和降噪,并安排法律专业的学生对案件进行分类,引入领域专家精准定义问题关系与节点关系,从而产生面向特定场景的知识图谱和智能代理任务数据集。
然后基于InternLM 架构建立了MoE 大模型,能够根据输入特征的差异性动态选择合适的专家模型,将每个专家模型的输出结果加权融合后作为最终结果,提升大模型在各个细分领域的专业能力。
最后建立多智能体协作框架,包括法律助手、法律研究员、资深律师和法律编辑4 类代理。法律助手与用户进行交互,从用户查询中提取关键信息,并与知识图谱进行链接,分析缺失信息,提示用户提供完整信息。法律研究员从交互信息中提取出法律实体、关系和重要案例,从知识库中检索相关案例与条文。资深律师对检索结果进行案例学习,经过相关性评估后输出综合分析结果。法律编辑根据分析结果选择答案模板,并将填充后生成的咨询文件反馈给用户。
2.2 提升关联分析能力
针对传统RAG 中数据分块导致的信息断裂与关联丢失问题,LinkedIn 研究团队提出了一种融合知识图谱与RAG 的客服自动问答架构(图5)。首先使用知识图谱对工单数据进行结构化表示,每个工单被解析为一棵树状图,不同层级的节点分别对应问题的标题、描述、复现步骤等内容,通过挖掘不同工单之间的关系形成语义连通图。然后利用BERT、E5 等预训练模型将知识图谱中的节点映射为高维语义向量,并存储到向量数据库中。在检索问答过程中,通过实体识别和意图检测,从知识图谱中提取相关信息后反馈给大模型生成答案。
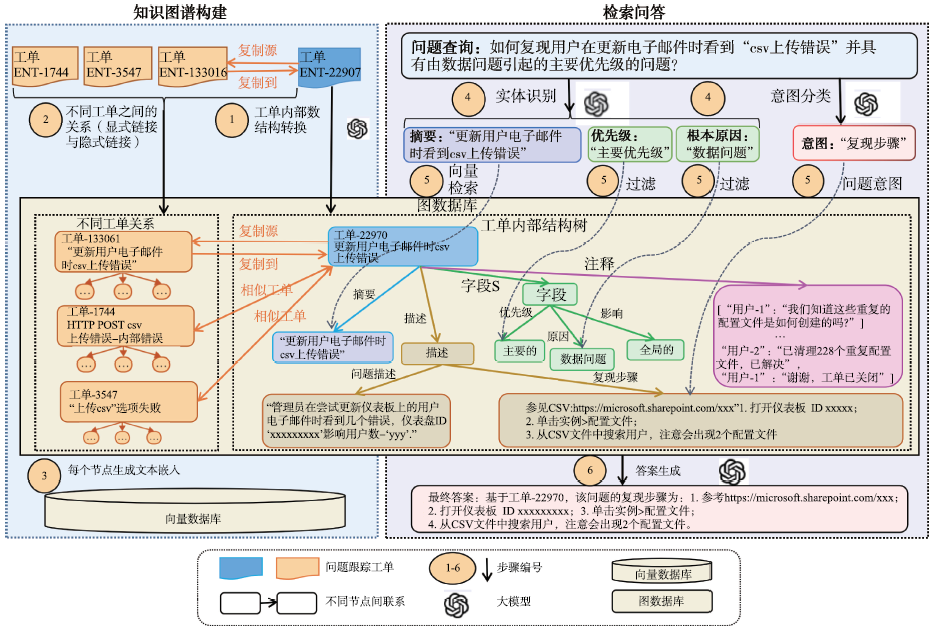
图5 融合知识图谱与RAG 的客服自动问答架构
2.3 提升全局总结能力
传统RAG 在处理大规模外部数据源时,过度依赖局部文本片段检索,无法捕捉到整个数据集信息,为此微软研究院提出了一种基于全局摘要的GraphRAG方法(图6)。首先从源文档派生出实体知识图谱,然后采用图机器学习等技术将图谱聚类成不同粒度级别的实体社区,并为每个社区创建摘要。当接收到问题后,GraphRAG通过社区摘要生成部分答案,将这些答案汇总后作为最终答案反馈给用户。作者设计了相关实验,从准确性、多样性、全面性、直接性等方面评估GraphRAG在全局理解任务上的有效性。结果显示,相较于Naive RAG基线,GraphRAG实现了在复杂问答任务上的可扩展性,回答问题的全面性和多样性都有显著提升,同时节省了大量上下文信息,提高了查询性能。
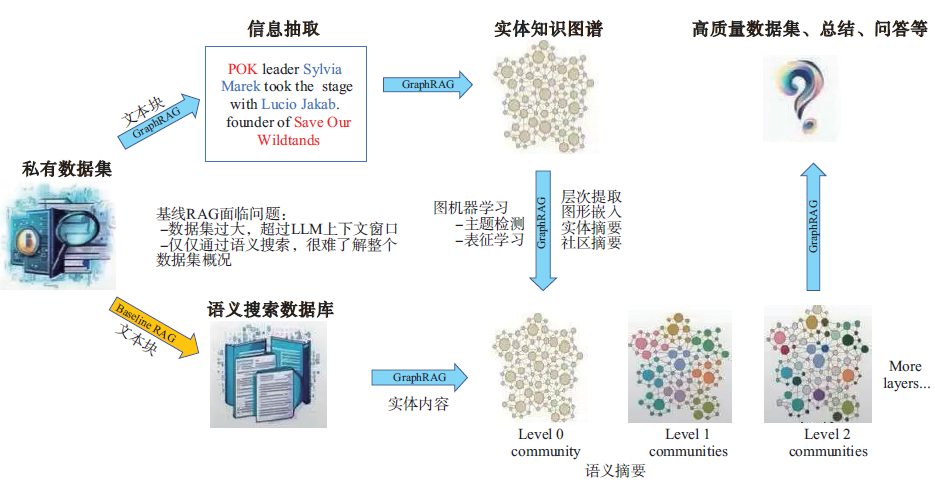
图6 GraphRAG 预处理流水线
2.4 提升推理能力与可解释性
为了提高大型语言模型的准确性和可解释性,北京大学计算机学院提出了一种基于知识图谱的RAG 方法HyKGE (图7),包括假设输出、实体识别、知识图谱检索、重排、生成等模块。假设输出模块利用LLM 零样本能力获得探索性和假设性输出(Hypothesis Output,HO),补偿用户查询的不完整性,实体识别模块利用知识图谱中的推理链。HO片段粒度感知重排模块以更细粒度重新排列和整合检索到的知识,通过分而治之的思想增强用户查询与外部知识推理路径之间的对齐。生成模块将用户查询作为问题、推理链作为上下文输入到大模型中生成最终答案。HyKGE 利用结构化知识图谱对用户查询进行验证和修正,不仅显著提升回答的精确度,而且减少模型在处理复杂医疗问题时的不确定性。
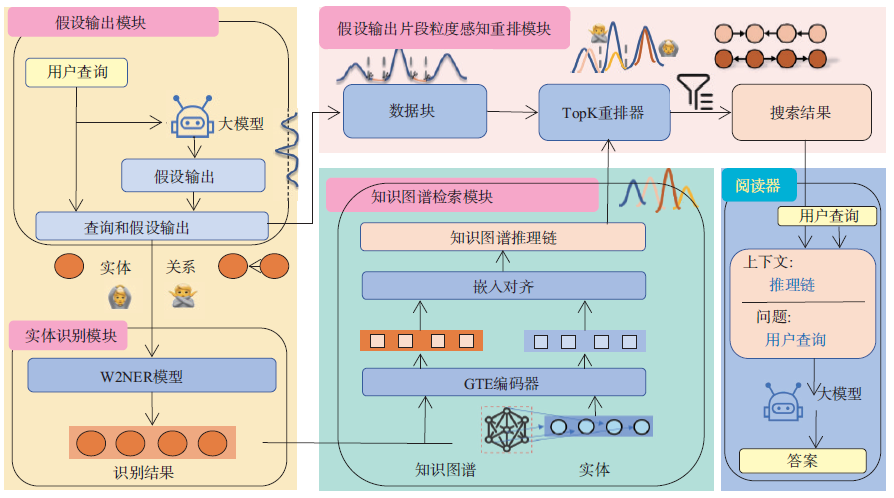
图7 HyKGE 架构图
俄亥俄州立大学和斯坦福大学的研究人员设计了新型检索增强模型HippoRAG,以提升RAG 的知识整合与多跳推理能力(图8)。HippoRAG 使用大语言模型处理信息,知识图谱充当“记忆索引”,通过检索模型连接语言模型和知识图谱,并引入“节点特异性”概念,权衡概念重要性。当模型接收到一个新的查询时,首先从查询中提取关键概念,然后在知识图谱上应用个性化PageRank 算法进行概念扩展和检索,模拟联想记忆能力。最后模型根据节点的重要性对passage 进行排序和检索。
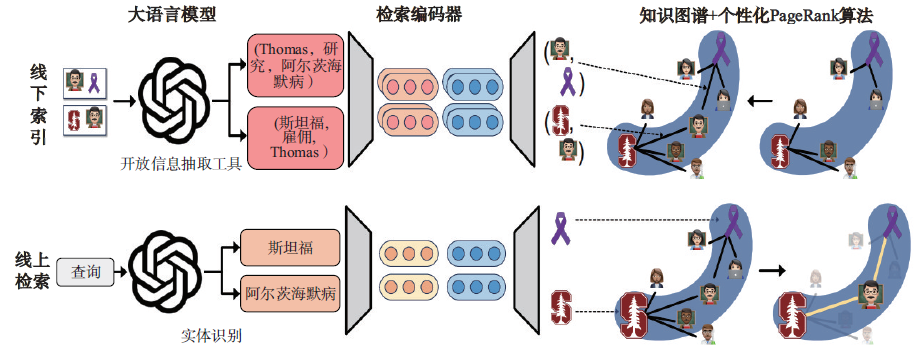
图8 HippoRAG 技术路线
3 知识图谱与RAG 结合方案探讨
综上所述,在RAG 的不同阶段都可以引入知识图谱增强系统性能,具体表现如下。
(1)数据分块阶段:数据分块较大会引入无关信息和冗余信息,影响准确率;数据分块较小容易导致信息断裂、关联丢失。在数据分块过程中,使用知识图谱将实体相关度较高的段落放到一个片段中,以获取合适的切片粒度;或者使用知识图谱存储文档布局信息,快速获取与查询相关片段。
(2)知识存储阶段:向量数据库通过高维向量处理非结构化数据,很难捕获不同数据类型之间的复杂关系和属性。图数据库以结构化方式表示和存储异构和互连的信息,能够进行复杂推理。将两者结合,可以提升现有RAG 系统的推理能力。
(3)查询优化阶段:使用知识图谱对用户查询进行扩展和改写,提高检索结果的相关性与质量。
(4)检索召回阶段:集成图谱检索、全文检索、向量检索等技术构建混合检索器,以适应不同的查询需求,在保证搜索效率的同时,提高搜索的准确性和全面性。
(5)重新排序阶段:根据知识图谱中实体重要性对检索结果进行排序,提升候选段落中包含最优答案概率。
(6)提示词工程阶段:从知识图谱中获取背景知识和推理链作为上下文,添加到提示模板中,提升RAG 系统的推理能力。
(7)答案生成阶段:用知识图谱对答案进行知识修正和知识溯源,提升答案的可靠性与可解释性。
4 基于知识图谱与向量数据库的RAG对比实验
随着RAG 技术的快速发展, LangChain、LlamaIndex 等开源框架中也集成了知识图谱、图数据库等组件与接口,方便企业快速实施RAG 项目。笔者选择油气领域知识问答场景进行实验, 并基于Lucene、LangChain 设计了3 套方案,对比分析全文检索、向量搜索、图谱搜索的应用效果。
4.1 实验准备
在LangChain 框架中,使用ChatGLM2-6b-chat 作为问答大模型,使用M3E 模型来生成嵌入,使用Faiss 向量数据库来储存知识库信息。
实验中使用的知识图谱系统为自主研发,具有百万节点的油气领域知识图谱数据,且有针对油气勘探领域的实体识别、关系抽取、知识融合和知识推理算法,相对有较好的数据基础和技术支持能力。该知识图谱存储于图数据库中,在智能问答实验中,采用如下提示模板(图9)。

图9 提示模板
4.2 实验方案
(1)基于Lucene 的检索问答方案。
图10 给出了基于Lucene 的检索问答流程(Lucene-QA),主要包括索引构建和检索匹配两个步骤。
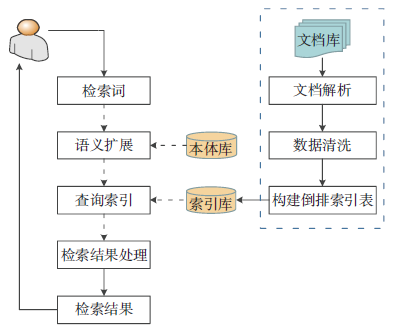
图10 基于Lucene 检索的问答流程
①索引库构建。对非结构化文档进行解析,提取文本内容,经过特殊符号处理、停用词过滤、大小写字母转换等数据清洗流程后,结合领域词典与专业术语进行分词,构建倒排索引表,写入索引库。
②检索匹配。对用户问题进行语法分析和分词处理,获取检索词,并结合本体库进行语义扩展,以提高查全率;在索引库中进行搜索,获取相关文档列表,根据文档与查询的相关性,对检索结果进行排序,将满足阈值要求的k 个文档作为查询结果反馈给用户。
(2)基于知识图谱的RAG 方案。
图11 给出了基于知识图谱的RAG 方案(KGRAG),以问题“管道检测技术是什么?”为例,问答流程如下:
①用户提出问题;②经过实体抽取算法,抽取出实体,在此问题中,实体为“管道检测技术”;③使用实体“管道检测技术”检索存放在图数据库中的知识图谱;④获得与被检索实体“管道检测技术”相关的子表信息;⑤将子表信息数据转化为结构化的JSON 格式;⑥作为上下文加入提示词向语言大模型提问并得出答案“管道检测技术是……”。
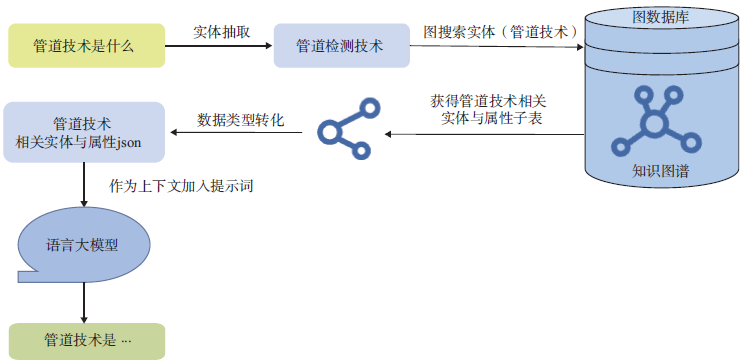
图11 基于知识图谱的RAG 系统问答流程
(3)基于向量数据库的RAG 方案。
图12 给出了基于向量数据库的RAG 方案(Vector-RAG),主要包括向量数据库构建与用户查询两个阶段。
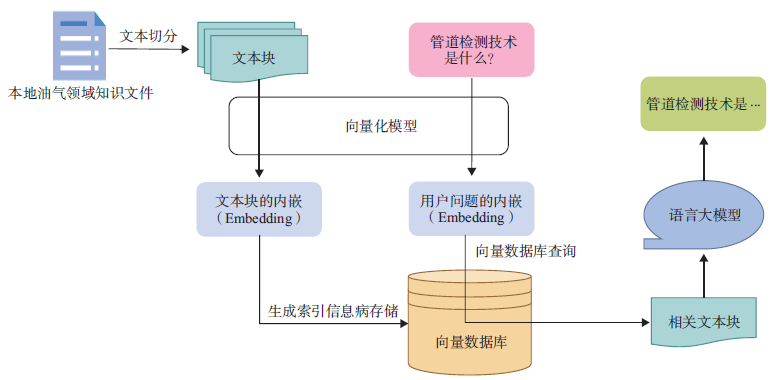
图12 利用向量数据库的RAG 系统问答流程
向量数据库构建包括以下步骤:
①将本地的油气领域知识文件进行文本切分生成文本块;②使用向量化模型生成文本块的内嵌;③构建向量数据库的索引并将文本块内嵌至向量数据库。
以问题“管道检测技术是什么?”为例,用户查询流程如下:
①使用向量化模型将用户问题转化为内嵌;②在向量数据库中查询与用户问题相关的文本块;③将相关文本块加入提示词向大模型提问并得出答案“管道检测技术是……”。
4.3 实例分析
基于上述方案,设计了多个油气领域内的专业问题,并对问答结果进行分析,部分实例如表1 所示。
表1 KG RAG 与Vector RAG 问答实例对比分析
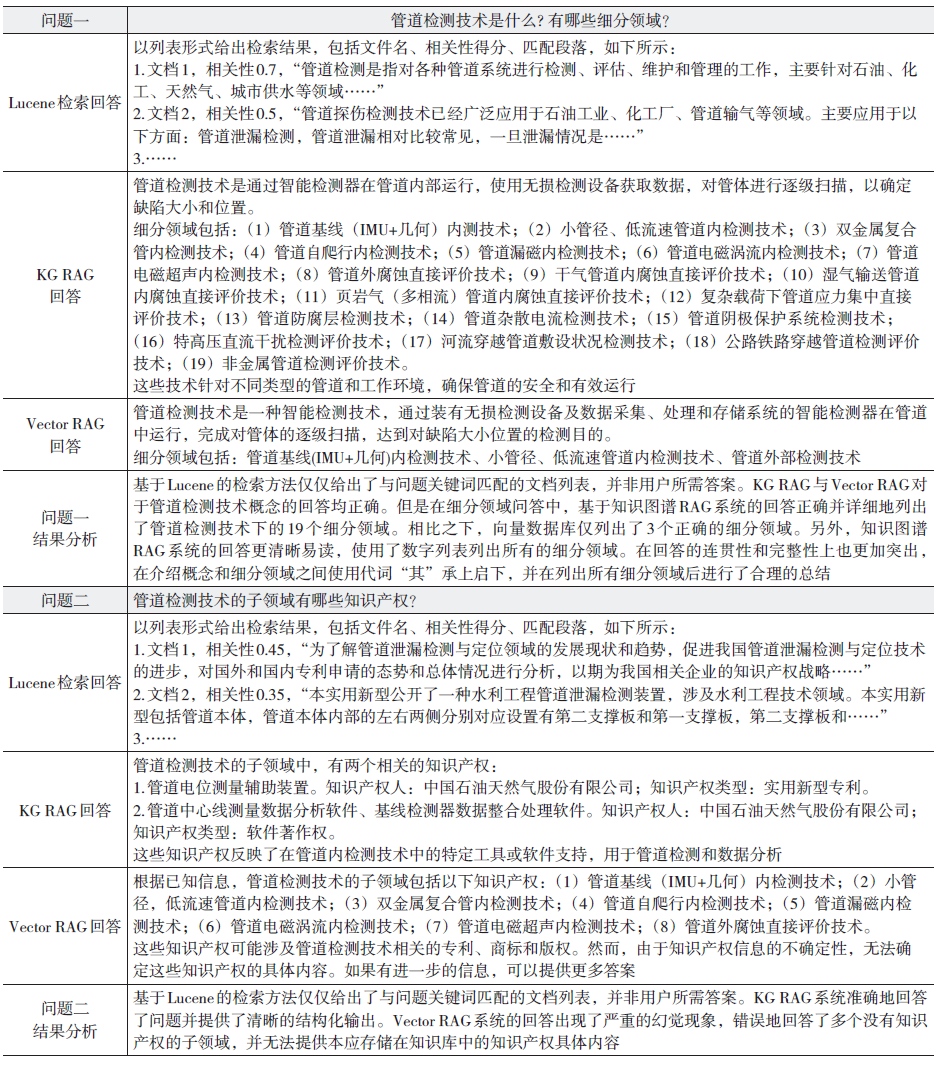
4.4 实验结论
通过实验对比,可以得出:
(1)基于Lucene 的检索问答主要根据关键词匹配获取相关文档,用户需要对检索结果进行归纳整理后得到最优结果。KG RAG 与Vecetor RAG 集成了大模型强大的自然语言理解能力与生成能力,能够对检索结果进行归纳总结后生成答案。
(2)基于相同知识文档建立的知识图谱和向量数据库,在领域知识问答任务中的应用效果存在明显差距。对于同一个问题,KG RAG 给出的答案比VectorRAG 给出的答案更加准确、直观,减轻了大模型的“幻觉”。
(3)如果没有高质量的知识图谱,Vector RAG 无疑成为相对经济便捷的选择。对于高度结构化的细分领域(如油气领域) 智能问答,高质量的知识图谱能够给大模型的回答质量带来巨大提升,包括但不限于:幻觉更少、更准确、更完整、更结构化、逻辑更严谨的回复。
5 结束语
油气行业业务流程复杂,数据类型多样,非结构化数据治理、多尺度数据融合、跨部门数据共享等问题使得人工智能数据集构建面临严峻挑战,加大了人工智能应用落地的成本与难度。知识图谱技术可以解决油气知识表征、知识抽取、知识融合与知识推理等问题,但是需要领域专家深度参与,投入成本大、建设周期长。RAG 技术可以对大规模非结构化数据进行高效存储与检索,成本低、见效快,但是无法进行精准匹配和复杂推理。将知识图谱与RAG 系统进行结合无疑是最佳选择,可以实现优势互补。以知识图谱与RAG 为研究对象,分析了国内外相关案例与其技术方案,探讨了知识图谱在RAG 不同阶段的结合方案,并以油气领域知识问答为例,验证了知识图谱对提升RAG 系统性能的有效性,为油气行业实施大模型项目提供参考。
随着大模型技术的快速发展,斯伦贝谢、哈里伯顿、沙特阿美等全球知名油公司正加速向“硅谷”靠拢,期望在数据、算力、算法的加持下,寻求更多的领先数智化技术,以提升自身数智化水平。中国石油、中国海洋石油集团有限公司、中国石油化工集团有限公司等企业也启动了相关研究,积极探索大模型技术在地质建模、储层预测、智能解释、风险识别、数值模拟等场景下的应用模式与技术路径,为油气行业的智能化发展注入新质生产力。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 7078
7078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









