



1.1 信息抽取 常见面试篇
1.1.1 命名实体识别 常见面试篇
-
隐马尔科夫算法 HMM 常见面试篇
-
- 3.1 隐马尔科夫算法 介绍篇
- 3.2 隐马尔科夫算法 模型计算过程篇
- 3.3 隐马尔科夫算法 问题篇
- 3.1.1 隐马尔科夫算法 是什么?
- 3.1.2 隐马尔科夫算法 中 两个序列 是什么?
- 3.1.3 隐马尔科夫算法 中 三个矩阵 是什么?
- 3.1.4 隐马尔科夫算法 中 两个假设 是什么?
- 3.1.5 隐马尔科夫算法 中 工作流程 是什么?
- 3.2.1 隐马尔科夫算法 学习训练过程 是什么样的?
- 3.2.2 隐马尔科夫算法 序列标注(解码)过程 是什么样的?
- 3.2.3 隐马尔科夫算法 序列概率过程 是什么样的?
- 2.1 什么是 马尔可夫过程?
- 2.2 马尔可夫过程 的核心思想 是什么?
- 1.1 什么是概率图模型?
- 1.2 什么是 随机场?
- 一、基础信息 介绍篇
- 二、马尔可夫过程 介绍篇
- 三、隐马尔科夫算法 篇
-
最大熵马尔科夫模型 MEMM 常见面试篇
-
- 4.1 最大熵马尔科夫模型(MEMM)动机篇
- 4.2 最大熵马尔科夫模型(MEMM)介绍篇
- 4.3 最大熵马尔科夫模型(MEMM)问题篇
- 4.1.1 HMM 存在 什么问题?
- 4.2.1 最大熵马尔科夫模型(MEMM) 是什么样?
- 4.2.2 最大熵马尔科夫模型(MEMM) 如何解决 HMM 问题?
- 四、最大熵马尔科夫模型(MEMM)篇
条件随机场(CRF) 常见面试篇
-
五、条件随机场(CRF)篇
-
- 5.3.1 CRF 的 优点在哪里?
- 5.3.2 CRF 的 缺点在哪里?
- 5.2.1 什么是 CRF?
- 5.2.2 CRF 的 主要思想是什么?
- 5.2.3 CRF 的定义是什么?
- 5.2.4 CRF 的 流程是什么?
- 5.1.1 HMM 和 MEMM 存在什么问题?
- 5.1 CRF 动机篇
- 5.2 CRF 介绍篇
- 5.3 CRF 优缺点篇
- 5.4 CRF 复现?
-
六、对比篇
-
- 6.1 CRF 模型 和 HMM 和 MEMM 模型 区别?
-
DNN-CRF 常见面试篇
-
- 4.1 CNN-CRF vs BiLSTM-CRF vs IDCNN-CRF?
- 4.2 为什么 DNN 后面要加 CRF?
- 4.3 CRF in TensorFlow V.S. CRF in discrete toolkit?
- 3.1 基于深度学习的命名实体识别方法 相比于 基于机器学习的命名实体识别方法的优点?
- 3.2 基于深度学习的命名实体识别方法 的 结构是怎么样?
- 3.3 分布式输入层 是什么,有哪些方法?
- 3.4 文本编码器篇
- 3.5 标签解码器篇
- 3.4.2.1 什么是 Dilated CNN?
- 3.4.2.2 为什么会有 Dilated CNN?
- 3.4.2.3 Dilated CNN 的优点?
- 3.4.2.4 IDCNN-CRF 介绍
- 3.4.1.1 什么是 BiLSTM-CRF?
- 3.4.1.2 为什么要用 BiLSTM?
- 3.4.1 BiLSTM-CRF 篇
- 3.4.2 IDCNN-CRF 篇
- 3.5.1 标签解码器是什么?
- 3.5.2 MLP+softmax 层 介绍?
- 3.5.3 条件随机场 CRF 层 介绍?
- 3.5.4 循环神经网络 RNN 层 介绍?
- 3.5.3 指针网路层 介绍?
- 2.1 基于规则的命名实体识别方法是什么?
- 2.2 基于无监督学习的命名实体识别方法是什么?
- 2.3 基于特征的监督学习的命名实体识别方法是什么?
- 1.1 命名实体识别 评价指标 是什么?
- 一、基本信息
- 二、传统的命名实体识别方法
- 三、基于深度学习的命名实体识别方法
- 四、对比 篇
-
中文领域 NER 常见面试篇
-
- 3.1 什么是 词汇 / 实体类型信息增强?
- 3.2 为什么说 「词汇 / 实体类型信息增强」 方法对于中文 NER 任务有效呢?
- 3.3 词汇 / 实体类型信息增强 方法有哪些?
- 3.4 什么是 LEX-BERT ?
- 2.1 什么是 词汇增强?
- 2.2 为什么说 「词汇增强」 方法对于中文 NER 任务有效呢?
- 2.3 词汇增强 方法有哪些?
- 2.4 Dynamic Architecture
- 2.5 Adaptive Embedding 范式
- 2.4.1 什么是 Dynamic Architecture?
- 2.4.2 常用方法有哪些?
- 2.4.3 什么是 Lattice LSTM ,存在什么问题?
- 2.4.4 什么是 FLAT ,存在什么问题?
- 2.5.1 什么是 Adaptive Embedding 范式?
- 2.5.2 常用方法有哪些?
- 2.5.3 什么是 WC-LSTM ,存在什么问题?
- 1.1 中文命名实体识别 与 英文命名实体识别的区别?
- 一、动机篇
- 二、词汇增强篇
- 三、词汇 / 实体类型信息增强篇
-
命名实体识别 trick 常见面试篇
-
- 7.1 什么是实体嵌套?
- 7.2 与 传统命名实体识别任务的区别
- 7.3 解决方法:
- 7.3.1 方法一:序列标注
- 7.3.2 方法二:指针标注
- 7.3.3 方法三:多头标注
- 7.3.4 方法四:片段排列
- trick 1:领域词典匹配
- trick 2:规则抽取
- trick 3:词向量选取:词向量 or 字向量?
- trick 4:特征提取器 如何选择?
- trick 5:专有名称 怎么 处理?
- trick 6:标注数据 不足怎么处理?
- trick 7:嵌套命名实体识别怎么处理
- trick 8:为什么说 「词汇增强」 方法对于中文 NER 任务有效?
- trick 9:NER 实体 span 过长怎么办?
- trick 10: NER 标注数据噪声问题?
- trick 11: 给定两个命名实体识别任务,一个任务数据量足够,另外一个数据量很少,可以怎么做?
- trick 12: NER 标注数据不均衡问题?
1.1.2 关系抽取 常见面试篇
-
关系抽取 常见面试篇
-
- 3.1 文档级关系抽取与经典关系抽取有何区别?
- 3.2 文档级别关系抽取中面临什么样的问题?
- 3.3 文档级关系抽取的方法有哪些?
- 3.4 文档级关系抽取常见数据集有哪些以及其评估方法?
- 3.3.1 基于 BERT-like 的文档关系抽取是怎么做的?
- 3.3.2 基于 graph 的文档关系抽取是怎么做的?
- 2.1 模板匹配方法是指什么?有什么优缺点?
- 2.2 远监督关系抽取是指什么?它有什么优缺点?
- 2.3 什么是关系重叠?复杂关系问题?
- 2.4 联合抽取是什么?难点在哪里?
- 2.5 联合抽取总体上有哪些方法?各有哪些缺点?
- 2.6 介绍基于共享参数的联合抽取方法?
- 2.7 介绍基于联合解码的联合抽取方法?
- 2.8 实体关系抽取的前沿技术和挑战有哪些?如何解决低资源和复杂样本下的实体关系抽取?
- 1.1 什么是关系抽取?
- 1.2 关系抽取技术有哪些类型?
- 1.3 常见的关系抽取流程是怎么做的?
- 一、动机篇
- 二、经典关系抽取篇
- 三、文档级关系抽取篇
1.1.3 事件抽取 常见面试篇
-
事件抽取 常见面试篇
-
- 7.1 事件抽取论文综述
- 7.2 事件抽取常见问题
- 5.1 事件抽取和命名实体识别(即实体抽取)有什么异同?
- 5.2 事件抽取和关系抽取有什么异同?
- 5.3 什么是事理图谱?有哪些事件关系类型?事理图谱怎么构建?主要技术领域及当前发展热点是什么?
- 4.1 事件抽取中常见的英文数据集有哪些?
- 4.2 事件抽取中常见的中文数据集有哪些?
- 4.3 事件抽取的评价指标是什么?怎么计算的?
- 3.1 模式匹配方法怎么用在事件抽取中?
- 3.2 统计机器学习方法怎么用在事件抽取中?
- 3.3 深度学习方法怎么用在事件抽取中?
- 2.1 触发词检测
- 2.2 类型识别
- 2.3 角色识别
- 2.4 论元检测
- 2.1.1 什么是触发词检测?
- 2.1.2 触发词检测有哪些方法?
- 2.2.1 什么是类型识别?
- 2.2.2 类型识别有哪些方法?
- 2.3.1 什么是角色识别?
- 2.3.2 角色识别有哪些方法?
- 2.4.1 什么是论元检测?
- 2.4.2 论元检测有哪些方法?
- 1.1 什么是事件?
- 1.2 什么是事件抽取?
- 1.3 ACE 测评中事件抽取涉及的几个基本术语及任务是什么?
- 1.4 事件抽取怎么发展的?
- 1.5 事件抽取存在什么问题?
- 一、原理篇
- 二、基本任务篇
- 三、常见方法篇
- 四、数据集及评价指标篇
- 五、对比篇
- 六、应用篇
- 七、拓展篇
1.2 NLP 预训练算法 常见面试篇
-
【关于 TF-idf】
-
- 2.1 什么是 TF-IDF?
- 2.2 TF-IDF 如何评估词的重要程度?
- 2.3 TF-IDF 的思想是什么?
- 2.4 TF-IDF 的计算公式是什么?
- 2.5 TF-IDF 怎么描述?
- 2.6 TF-IDF 的优点是什么?
- 2.7 TF-IDF 的缺点是什么?
- 2.8 TF-IDF 的应用?
- 1.1 为什么有 one-hot ?
- 1.2 one-hot 是什么?
- 1.3 one-hot 有什么特点?
- 1.4 one-hot 存在哪些问题?
- 一、one-hot 篇
- 二、TF-IDF 篇
-
关于 word2vec
-
- 4.1 word2vec 训练 trick,window 设置多大?
- 4.1 word2vec 训练 trick,词向量纬度,大与小有什么影响,还有其他参数?
- 3.1 word2vec 和 NNLM 对比有什么区别?(word2vec vs NNLM)
- 3.2 word2vec 和 tf-idf 在相似度计算时的区别?
- 2.1 Word2vec 中 霍夫曼树 是什么?
- 2.2 Word2vec 中 为什么要使用 霍夫曼树?
- 2.3 Word2vec 中使用 霍夫曼树 的好处?
- 2.4 为什么 Word2vec 中会用到 负采样?
- 2.5 Word2vec 中会用到 负采样 是什么样?
- 2.6 Word2vec 中 负采样 的采样方式?
- 1.1 Wordvec 指什么?
- 1.2 Wordvec 中 CBOW 指什么?
- 1.3 Wordvec 中 Skip-gram 指什么?
- 1.4 CBOW vs Skip-gram 哪一个好?
- 一、Wordvec 介绍篇
- 二、Wordvec 优化篇
- 三、Wordvec 对比篇
- 四、word2vec 实战篇
-
【关于 FastText】
-
- 3.1 为什么要用 层次化 Softmax 回归 (Hierarchical Softmax) ?
- 3.2 层次化 Softmax 回归 (Hierarchical Softmax) 的思想是什么?
- 3.3 层次化 Softmax 回归 (Hierarchical Softmax) 的步骤?
- 2.1 引言
- 2.2 fastText 是什么?
- 2.3 fastText 的结构是什么样?
- 2.4 为什么 fastText 要使用词内的 n-gram 信息 (subword n-gram information)?
- 2.5 fastText 词内的 n-gram 信息 (subword n-gram information) 介绍?
- 2.6 fastText 词内的 n-gram 信息 的 训练过程?
- 2.7 fastText 词内的 n-gram 信息 存在问题?
- 1.1 word-level Model 是什么?
- 1.2 word-level Model 存在什么问题?
- 1.3 Character-Level Model 是什么?
- 1.4 Character-Level Model 优点?
- 1.5 Character-Level Model 存在问题?
- 1.6 Character-Level Model 问题的解决方法?
- 一、fastText 动机篇
- 二、 词内的 n-gram 信息 (subword n-gram information) 介绍篇
- 三、 层次化 Softmax 回归 (Hierarchical Softmax) 介绍篇
- 四、fastText 存在问题?
-
【关于 Elmo】
-
- 3.1 Elmo 存在的问题是什么?
- 2.1 Elmo 的 特点?
- 2.2 Elmo 的 思想是什么?
- 1.1 为什么会有 Elmo?
- 一、Elmo 动机篇
- 二、Elmo 介绍篇
- 三、Elmo 问题篇
1.3 Bert 常见面试篇
-
Bert 常见面试篇
-
- 3.1 【对比】多义词问题是什么?
- 3.2 【对比】word2vec 为什么解决不了多义词问题?
- 3.3 【对比】GPT 和 BERT 有什么不同?
- 3.4 【对比】为什么 elmo、GPT、Bert 能够解决多义词问题?(以 elmo 为例)
- 2.1 Bert 介绍篇
- 2.2 Bert 输入输出表征篇
- 2.3 【BERT】Bert 预训练篇
- 2.4 【BERT】 fine-turning 篇?
- 2.5 【BERT】 Bert 损失函数篇?
- 2.1.1【BERT】Bert 是什么?
- 2.1.2【BERT】Bert 三个关键点?
- 2.2.1 【BERT】Bert 输入输出表征长啥样?
- 2.3.3.1 【BERT】Bert 为什么需要预训练任务 Next Sentence Prediction ?
- 2.3.3.2 【BERT】 Bert 预训练任务 Next Sentence Prediction 怎么做?
- 2.3.2.1 【BERT】 Bert 为什么需要预训练任务 Masked LM ?
- 2.3.2.2 【BERT】 Bert 预训练任务 Masked LM 怎么做?
- 2.3.2.3 【BERT】 Bert 预训练任务 Masked LM 存在问题?
- 2.3.2.4 【BERT】 预训练和微调之间的不匹配的解决方法?
- 2.3.1 【BERT】Bert 预训练任务介绍
- 2.3.2 【BERT】Bert 预训练任务 之 Masked LM 篇
- 2.3.3 【BERT】Bert 预训练任务 之 Next Sentence Prediction 篇
- 2.4.1 【BERT】为什么 Bert 需要 fine-turning?
- 2.4.2 【BERT】 Bert 如何 fine-turning?
- 2.5.1 【BERT】BERT 的两个预训练任务对应的损失函数是什么 (用公式形式展示)?
- 1.1 【演变史】one-hot 存在问题?
- 1.2【演变史】wordvec 存在问题?
- 1.3【演变史】fastText 存在问题?
- 1.4【演变史】elmo 存在问题?
- 一、动机篇
- 二、Bert 篇
- 三、 对比篇?
1.3.1 Bert 模型压缩 常见面试篇
-
Bert 模型压缩 常见面试篇
-
- 3.1 Bert 模型压缩方法 之 低秩因式分解 & 跨层参数共享
- 3.2 Bert 模型压缩方法 之 蒸馏
- 3.3 Bert 模型压缩方法 之 量化
- 3.4 Bert 模型压缩方法 之 剪枝
- 3.1.1 什么是低秩因式分解?
- 3.1.2 什么是跨层参数共享?
- 3.1.3 ALBERT 所所用的方法?
- 3.2.1 什么是蒸馏?
- 3.2.2 使用 模型蒸馏 的论文 有哪些,稍微介绍一下?
- 3.3.1 什么是量化?
- 3.3.2 Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT 【量化】
- 3.4.1 什么是剪枝?
- 一、Bert 模型压缩 动机篇
- 二、Bert 模型压缩对比表
- 三、 Bert 模型压缩方法介绍
- 四、模型压缩存在问题?
1.3.2 Bert 模型系列 常见面试篇
- 认识 XLNet 么?能不能讲一下? 和 Bert 的 区别在哪里?
- 认识 RoBERTa 么?能不能讲一下? 和 Bert 的 区别在哪里?
- 认识 SpanBERT 么?能不能讲一下? 和 Bert 的 区别在哪里?
- 认识 MASS 么?能不能讲一下? 和 Bert 的 区别在哪里?
1.4 文本分类 常见面试篇
-
文本分类 常见面试篇
-
- 6.1 文本分类任务使用的评估算法和指标有哪些?
- 6.2 简单介绍混淆矩阵和 kappa?
- 5.1 激活函数 sigmoid 篇
- 5.2 激活函数 softmax 篇
- 5.3 分类问题使用的损失函数还有有哪些?
- 5.1.1 二分类问题使用的激活函数 sigmoid 简介?
- 5.1.2 Sigmod 的缺点是什么?
- 5.2.1 softmax 函数是什么?
- 5.2.2 softmax 函数怎么求导?
- 4.1 fastText 篇
- 4.2 TextCNN 篇
- 4.3 DPCNN 篇
- 4.4 TextRCNN 篇
- 4.5 RNN+Attention 篇
- 4.6 GNN 图神经网络篇
- 4.7 Transformer 篇
- 4.8 预训练模型 篇
- 4.1.1 fastText 的分类过程?
- 4.1.2 fastText 的优点?
- 4.2.1 TextCNN 进行文本分类的过程?
- 4.2.2 TextCNN 可以调整哪些参数?
- 4.2.3 使用 CNN 作为文本分类器时,不同通道 channels 对应着文本的什么信息?
- 4.2.4 TextCNN 中卷积核的长与宽代表了什么?
- 4.2.5 在 TextCNN 中的 pooling 操作与一般 CNN 的 pooling 操作有何不同?
- 4.2.6 TextCNN 的局限性?
- 4.3.1 如何解决长文本分类任务?
- 4.3.2 简单介绍 DPCNN 模型相较于 TextCNN 的改进?
- 4.4.1 简要介绍 TextRCNN 相较于 TextCNN 的改进?
- 4.5.1 RNN+Attention 进行文本分类任务的思路,以及为什么要加 Attention / 注意力机制如何应用于文本分类领域?
- 4.6.1 GNN 图神经网络如何应用于文本分类领域?
- 4.7.1 基于 Transformer 的预训练模型如何应用于文本分类领域?
- 4.8.1 你了解哪些预训练模型?它们的特点是什么?
- 3.1 (一个具体的)文本分类任务可以使用哪些特征?
- 3.2 (对于西文文本)使用单词和使用字母作为特征相比,差异如何?
- 3.3 能不能简单介绍下词袋模型?
- 3.4 n-gram 篇
- 3.5 主题建模篇
- 3.6 文本相似度篇
- 3.4.1 什么是 n 元语法?为什么要用 n-gram?
- 3.4.2 n-gram 算法的局限性是什么?
- 3.5.1 介绍一下主题建模任务?
- 3.5.2 主题建模的常用方法
- 3.5.3 TF-IDF 算法是做什么的?简单介绍下 TF-IDF 算法
- 3.5.4 tf-idf 高意味着什么?
- 3.5.5 tf-idf 的不足之处
- 3.6.1 如何计算两段文本之间的距离?
- 3.6.2 什么是 jaccard 距离?
- 3.6.3 Dice 系数和 Jaccard 系数的区别?
- 3.6.4 同样是编辑距离,莱文斯坦距离和汉明距离的区别在哪里?
- 3.6.5 写一下计算编辑距离(莱温斯坦距离)的编程题吧?
- 2.1 文本分类任务的数据预处理方法有哪些?
- 2.2 你使用过哪些分词方法和工具?
- 2.3 中文文本分词的方法?
- 2.4 基于字符串匹配的分词方法的原理 是什么?
- 2.5 统计语言模型如何应用于分词?N-gram 最大概率分词?
- 2.6 基于序列标注的分词方法 是什么?
- 2.7 基于 (Bi-)LSTM 的词性标注 是什么?
- 2.8 词干提取和词形还原有什么区别?
- 1.1 分类任务有哪些类别?它们都有什么特征?
- 1.2 文本分类任务相较于其他领域的分类任务有何不同之处?
- 1.3 文本分类任务和文本领域的其他任务相比有何不同之处?
- 1.4 文本分类的过程?
- 一、 抽象命题
- 二、数据预处理
- 三、特征提取
- 四、模型篇
- 五、损失函数
- 六、模型评估和算法比较
-
文本分类 trick 常见面试篇
-
- 一、文本分类数据预处理 如何做?
- 二、文本分类 预训练模型 如何选择?
- 三、文本分类 参数 如何优化?
- 四、文本分类 有哪些棘手任务?
- 五、文本分类 标签体系构建?
- 六、文本分类 策略构建?
-
用检索的方式做文本分类 常见面试篇
-
- 为什么需要用检索的方式做文本分类?
- 基于检索的方法做文本分类思路?
- 检索的方法的召回库如何构建?
- 检索的方法 的 训练阶段 如何做?
- 检索的方法 的 预测阶段 如何做?
- 用检索的方式做文本分类 方法 适用场景有哪些?
1.5 文本匹配 常见面试篇
-
文本匹配模型 ESIM 常见面试篇
-
- 为什么需要 ESIM?
- 介绍一下 ESIM 模型?
-
语义相似度匹配任务中的 BERT 常见面试篇
-
- 一、Sentence Pair Classification Task:使用 CLS
- 二、cosine similairity
- 三、长短文本的区别
- 四、sentence/word embedding
- 五、siamese network 方式
1.6 问答系统 常见面试篇
1.6.1 [FAQ 检索式问答系统 常见面试篇]
-
一、动机
-
- 1.1 问答系统的动机?
- 1.2 问答系统 是什么?
-
二、FAQ 检索式问答系统介绍篇
-
- 2.1 FAQ 检索式问答系统 是 什么?
- 2.2 query 匹配标准 QA 的核心是什么?
-
三、FAQ 检索式问答系统 方案篇
-
- 3.2.1 QQ 匹配的优点有哪些?
- 3.2.2 QQ 匹配的语义空间是什么?
- 3.2.3 QQ 匹配的语料的稳定性是什么?
- 3.2.4 QQ 匹配的业务回答与算法模型的解耦是什么?
- 3.2.5 QQ 匹配的新问题发现与去重是什么?
- 3.2.6 QQ 匹配的上线运行速度是什么?
- 3.1 常用 方案有哪些?
- 3.2 为什么 QQ 匹配比较常用?
- 3.3 QQ 匹配一般处理流程是怎么样? 【假设 标准问题库 已处理好】
-
四、FAQ 标准问题库构建篇
-
- 4.1 如何发现 FAQ 中标准问题?
- 4.2 FAQ 如何做拆分?
- 4.3 FAQ 如何做合并?
- 4.4 FAQ 标准库如何实时更新?
-
五、FAQ 标准问题库答案优化篇
-
- 5.1 FAQ 标准问题库答案如何优化?
1.6.2 问答系统工具篇 常见面试篇
-
Faiss 常见面试篇
-
- 4.1 sklearn cosine_similarity 和 Faiss 哪家强
- 3.1 Faiss 如何安装?
- 3.2 Faiss 的索引 Index 有哪些?
- 3.3 Faiss 的索引 Index 都怎么用?
- 3.4 Faiss 然后使用 GPU?
- 3.3.1 数据预备
- 3.3.2 暴力美学 IndexFlatL2
- 3.3.3 闪电侠 IndexIVFFlat
- 3.3.4 内存管家 IndexIVFPQ
- 2.1 什么是 Faiss ?
- 2.2 Faiss 如何使用?
- 2.3 Faiss 原理与核心算法
- 1.1 传统的相似度算法所存在的问题?
- 一、动机篇
- 二、介绍篇
- 三、Faiss 实战篇
- 四、 Faiss 对比篇
[milvus、PG 等数据库同理]
1.7 对话系统 常见面试篇
-
对话系统 常见面试篇
-
- 3.1 什么是任务型对话系统?
- 3.2 任务型对话系统的流程是怎么样?
- 3.3 任务型对话系统 语言理解(SLU)篇
- 3.4 任务型对话系统 DST(对话状态跟踪)篇
- 3.5 任务型对话系统 DPO(对话策略学习)篇
- 3.6 任务型对话系统 NLG(自然语言生成)篇
- 3.3.1 什么是 语言理解(SLU)?
- 3.3.2 语言理解(SLU)的输入输出是什么?
- 3.3.3 语言理解(SLU)所使用的技术是什么?
- 3.4.1 什么是 DST(对话状态跟踪)?
- 3.4.2 DST(对话状态跟踪)的输入输出是什么?
- 3.4.3 DST(对话状态跟踪)存在问题和解决方法?
- 3.4.4 DST(对话状态跟踪)实现方式是什么?
- 3.5.1 DPO(对话策略学习)是什么?
- 3.5.2 DPO(对话策略学习)的输入输出是什么?
- 3.5.3 DPO(对话策略学习)的实现方法是什么?
- 3.6.1 NLG(自然语言生成)是什么?
- 3.6.2 NLG(自然语言生成)的输入输出是什么?
- 3.6.3 NLG(自然语言生成)的实现方式?
- 2.1 为什么要用 多轮对话系统?
- 2.2 常见的多轮对话系统解决方案是什么?
- 1.1 对话系统有哪几种?
- 1.2 这几种对话系统的区别?
- 一、对话系统 介绍篇
- 二、多轮对话系统 介绍篇
- 三、任务型对话系统 介绍篇
1.8 知识图谱 常见面试篇
1.8.1 [知识图谱 常见面试篇]
-
一、知识图谱简介
-
- 1.2.1 什么是图(Graph)呢?
- 1.2.2 什么是 Schema 呢?
- 1.1 引言
- 1.2 什么是知识图谱呢?
- 1.3 知识图谱的类别有哪些?
- 1.4 知识图谱的价值在哪呢?
-
二、怎么构建知识图谱呢?
-
- 2.4.1 实体命名识别(Named Entity Recognition)
- 2.4.2 关系抽取(Relation Extraction)
- 2.4.3 实体统一(Entity Resolution)
- 2.4.4 指代消解(Disambiguation)
- 2.1 知识图谱的数据来源于哪里?
- 2.2 信息抽取的难点在哪里?
- 2.3 构建知识图谱所涉及的技术?
- 2.4、知识图谱的具体构建技术是什么?
-
三、知识图谱怎么存储?
-
四、知识图谱可以做什么?
1.8.2 [KBQA 常见面试篇]
-
一、基于词典和规则的方法
-
- 基于词典和规则的方法 实现 KBQA?
- 基于词典和规则的方法 实现 KBQA 流程?
-
二、基于信息抽取的方法
-
- 基于信息抽取的方法 实现 KBQA 流程?
1.8.3 [Neo4j 常见面试篇]
-
一、Neo4J 介绍与安装
-
- 1.1 引言
- 1.2 Neo4J 怎么下载?
- 1.3 Neo4J 怎么安装?
- 1.4 Neo4J Web 界面 介绍
- 1.5 Cypher 查询语言是什么?
-
二、Neo4J 增删查改篇
-
- 2.1 引言
- 2.2 Neo4j 怎么创建节点?
- 2.3 Neo4j 怎么创建关系?
- 2.4 Neo4j 怎么创建 出生地关系?
- 2.5 Neo4j 怎么查询?
- 2.6 Neo4j 怎么删除和修改?
-
三、如何利用 Python 操作 Neo4j 图数据库?
-
- 3.1 neo4j 模块:执行 CQL (cypher) 语句是什么?
- 3.2 py2neo 模块是什么?
-
四、数据导入 Neo4j 图数据库篇
Nebula、Tugraph 同理
1.9 [文本摘要 常见面试篇]
-
一、动机篇
-
- 1.1 什么是文本摘要?
- 1.2 文本摘要技术有哪些类型?
-
二、抽取式摘要篇
-
- 2.1.1 句子重要性评估算法有哪些?
- 2.1.2 基于约束的摘要生成方法有哪些?
- 2.1.3 TextTeaser 算法是怎么抽取摘要的?
- 2.1.4 TextRank 算法是怎么抽取摘要的?
- 2.1 抽取式摘要是怎么做的?
- 2.2 抽取式摘要的可读性问题是什么?
-
三、压缩式摘要篇
-
- 3.1 压缩式摘要是怎么做的?
-
四、生成式摘要篇
-
- 4.1 生成式摘要是怎么做的?
- 4.2 生成式摘要存在哪些问题?
- 4.3 Pointer-generator network 解决了什么问题?
-
五、摘要质量评估方法
-
- 5.1 摘要质量的评估方法有哪些类型?
- 5.2 什么是 ROUGE?
- 5.3 几种 ROUGE 指标之间的区别是什么?
- 5.4 BLEU 和 ROUGE 有什么不同?
1.10 [文本纠错篇 常见面试篇]
-
一、介绍篇
-
- 1.1 什么是文本纠错?
- 1.2 常见的文本错误类型?
- 1.3 文本纠错 常用方法?
-
二、pipeline 方法 介绍篇
-
- pipeline 中的 错误检测 如何实现?
- pipeline 中的 候选召回 如何实现?
- pipeline 中的 纠错排序 如何实现?
- pipeline 中的 ASR 回显优化 如何实现?
1.11 [文本摘要 常见面试篇]
-
一、动机篇
-
- 1.1 什么是文本摘要?
- 1.2 文本摘要技术有哪些类型?
-
二、抽取式摘要篇
-
- 2.1.1 句子重要性评估算法有哪些?
- 2.1.2 基于约束的摘要生成方法有哪些?
- 2.1.3 TextTeaser 算法是怎么抽取摘要的?
- 2.1.4 TextRank 算法是怎么抽取摘要的?
- 2.1 抽取式摘要是怎么做的?
- 2.2 抽取式摘要的可读性问题是什么?
-
三、压缩式摘要篇
-
- 3.1 压缩式摘要是怎么做的?
-
四、生成式摘要篇
-
- 4.1 生成式摘要是怎么做的?
- 4.2 生成式摘要存在哪些问题?
- 4.3 Pointer-generator network 解决了什么问题?
-
五、摘要质量评估方法
-
- 5.1 摘要质量的评估方法有哪些类型?
- 5.2 什么是 ROUGE?
- 5.3 几种 ROUGE 指标之间的区别是什么?
- 5.4 BLEU 和 ROUGE 有什么不同?
1.12 文本生成 常见面试篇
-
[生成模型的解码方法 常见面试篇]
-
- 什么是生成模型?
- 介绍一下 基于搜索的解码方法?
- 介绍一下 基于采样的解码方法?
- 深度学习算法篇 常见面试篇
2.1 CNN 常见面试篇
-
一、动机篇
-
二、CNN 卷积层篇
-
- 2.1 卷积层的本质是什么?
- 2.2 CNN 卷积层与全连接层的联系?
- 2.3 channel 的含义是什么?
-
三、CNN 池化层篇
-
- 3.1 池化层针对区域是什么?
- 3.2 池化层的种类有哪些?
- 3.3 池化层的作用是什么?
- 3.4 池化层 反向传播 是什么样的?
- 3.5 mean pooling 池化层 反向传播 是什么样的?
- 3.6 max pooling 池化层 反向传播 是什么样的?
-
四、CNN 整体篇
-
- 4.1 CNN 的流程是什么?
- 4.2 CNN 的特点是什么?
- 4.3 卷积神经网络为什么会具有平移不变性?
- 4.4 卷积神经网络中 im2col 是如何实现的?
- 4.5 CNN 的局限性是什么?
-
五、Iterated Dilated CNN 篇
-
- 5.1 什么是 Dilated CNN 空洞卷积?
- 5.2 什么是 Iterated Dilated CNN?
-
六、反卷积 篇
-
- 6.1 解释反卷积的原理和用途?
2.2 RNN 常见面试篇
-
一、RNN 篇
-
- 1.2 为什么需要 RNN?
- 1.2 RNN 结构是怎么样的?
- 1.3 RNN 前向计算公式?
- 1.4 RNN 存在什么问题?
-
二、长短时记忆网络 (Long Short Term Memory Network, LSTM) 篇
-
- 2.1 为什么 需要 LSTM?
- 2.2 LSTM 的结构是怎么样的?
- 2.3 LSTM 如何缓解 RNN 梯度消失和梯度爆炸问题?
- 2.3 LSTM 的流程是怎么样的?
- 2.4 LSTM 中激活函数区别?
- 2.5 LSTM 的复杂度?
- 2.6 LSTM 存在什么问题?
-
三、GRU (Gated Recurrent Unit)
-
- 3.1 为什么 需要 GRU?
- 3.2 GRU 的结构是怎么样的?
- 3.3 GRU 的前向计算?
- 3.4 GRU 与其他 RNN 系列模型的区别?
-
四、RNN 系列模型篇
-
- 4.1 RNN 系列模型 有什么特点?
2.3 Attention 常见面试篇
-
一、seq2seq 篇
-
- 1.1 seq2seq (Encoder-Decoder)是什么?
- 1.2 seq2seq 中 的 Encoder 怎么样?
- 1.3 seq2seq 中 的 Decoder 怎么样?
- 1.4 在 数学角度上 的 seq2seq ,你知道么?
- 1.5 seq2seq 存在 什么 问题?
-
二、Attention 篇
-
- 步骤一 执行 encoder (与 seq2seq 一致)
- 步骤二 计算对齐系数 a
- 步骤三 计算上下文语义向量 C
- 步骤四 更新 decoder 状态
- 步骤五 计算输出预测词
- 2.1 什么是 Attention?
- 2.2 为什么引入 Attention 机制?
- 2.3 Attention 有什么作用?
- 2.4 Attention 流程是怎么样?
- 2.5 Attention 的应用领域有哪些?
-
三、Attention 变体篇
-
- 3.1 Soft Attention 是什么?
- 3.2 Hard Attention 是什么?
- 3.3 Global Attention 是什么?
- 3.4 Local Attention 是什么?
- 3.5 self-attention 是什么?
2.4 生成对抗网络 GAN 常见面试篇
-
一、动机
-
二、介绍篇
-
- 2.2.1 GAN 的基本结构
- 2.2.2 GAN 的基本思想
- 2.1 GAN 的基本思想
- 2.2 GAN 基本介绍
-
三、训练篇
-
- 3.1 生成器介绍
- 3.2 判别器介绍
- 3.3 训练过程
- 3.4 训练所涉及相关理论基础
-
四、总结
2.5 Transformer 常见面试篇
-
[Transformer 常见面试篇]
-
- 3.1 self-attention 模块
- 3.2 multi-head attention 模块
- 3.3 位置编码(Position encoding)模块
- 3.4 残差模块模块
- 3.5 Layer normalization 模块
- 3.6 Mask 模块
- 3.1.1 传统 attention 是什么?
- 3.1.2 为什么 会有 self-attention?
- 3.1.3 self-attention 的核心思想是什么?
- 3.1.4 self-attention 的目的是什么?
- 3.1.5 self-attention 的怎么计算的?
- 3.1.6 self-attention 为什么 Q 和 K 使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
- 3.1.7 为什么采用点积模型的 self-attention 而不采用加性模型?
- 3.1.8 Transformer 中在计算 self-attention 时为什么要除以 d \sqrt{d} d ?
- 3.1.9 self-attention 如何解决长距离依赖问题?
- 3.1.10 self-attention 如何并行化?
- 3.2.1 multi-head attention 的思路是什么样?
- 3.2.2 multi-head attention 的步骤是什么样?
- 3.2.3 Transformer 为何使用多头注意力机制?(为什么不使用一个头)
- 3.2.4 为什么在进行多头注意力的时候需要对每个 head 进行降维?
- 3.2.5 multi-head attention 代码介绍
- 3.3.1 为什么要 加入 位置编码(Position encoding) ?
- 3.3.2 位置编码(Position encoding)的思路是什么 ?
- 3.3.3 位置编码(Position encoding)的作用是什么 ?
- 3.3.4 位置编码(Position encoding)的步骤是什么 ?
- 3.3.5 Position encoding 为什么选择相加而不是拼接呢?
- 3.3.6 Position encoding 和 Position embedding 的区别?
- 3.3.7 为何 17 年提出 Transformer 时采用的是 Position Encoder 而不是 Position Embedding?而 Bert 却采用的是 Position Embedding ?
- 3.3.8 位置编码(Position encoding)的代码介绍
- 3.4.1 为什么要 加入 残差模块?
- 3.5.1 为什么要 加入 Layer normalization 模块?
- 3.5.2 Layer normalization 模块的是什么?
- 3.5.3 Batch normalization 和 Layer normalization 的区别?
- 3.5.4 Transformer 中为什么要舍弃 Batch normalization 改用 Layer normalization 呢?
- 3.5.5 Layer normalization 模块代码介绍
- 3.6.1 什么是 Mask?
- 3.6.2 Transformer 中用到 几种 Mask?
- 3.6.3 能不能介绍一下 Transformer 中用到几种 Mask?
- 2.1 Transformer 整体结构是怎么样?
- 2.2 Transformer-encoder 结构怎么样?
- 2.3 Transformer-decoder 结构怎么样?
- 1.1 为什么要有 Transformer?
- 1.2 Transformer 作用是什么?
- 一、动机篇
- 二、整体结构篇
- 三、模块篇
2.6 关于 Transformer 问题及改进
-
一、Transformer 问题篇
-
- 1.1 既然 Transformer 怎么牛逼,是否还存在一些问题?
-
二、每个问题的解决方法是什么?
-
- 2.1.1 Transformer 固定了句子长度?
- 2.1.2 Transformer 固定了句子长度 的目的是什么?
- 2.1.3 Transformer 针对该问题的处理方法?
- 2.1 问题一:Transformer 不能很好的处理超长输入问题
- 2.2 问题二:Transformer 方向信息以及相对位置 的 缺失 问题
- 2.3 问题三:缺少 Recurrent Inductive Bias
- 问题四:问题四:Transformer 是非图灵完备的: 非图灵完备通俗的理解,就是无法解决所有的问题
- 问题五:transformer 缺少 conditional computation;
- 问题六:transformer 时间复杂度 和 空间复杂度 过大问题;
3.NLP 技巧面
3.1 少样本问题面
3.1.1 [数据增强(EDA) 面试篇]
-
一、动机篇
-
- 1.1 什么是 数据增强?
- 1.2 为什么需要 数据增强?
-
二、常见的数据增强方法篇
-
- 2.8.1 什么是对抗增强?
- 2.7.1 什么是语法树操作?
- 2.6.1 什么是 交叉增强篇
- 2.5.1 什么是回译法?
- 2.4.1 什么是随机删除法?
- 2.3.1 什么是随机交换法?
- 2.2.1 什么是随机插入法?
- 2.1.1 什么是基于词典的替换方法?
- 2.1.2 什么是基于词向量的替换方法?
- 2.1.3 什么是基于 MLM 的替换方法?
- 2.1.4 什么是基于 TF-IDF 的词替换?
- 2.1 词汇替换篇
- 2.2 词汇插入篇
- 2.3 词汇交换篇
- 2.4 词汇删除篇
- 2.5 回译篇
- 2.6 交叉增强篇
- 2.7 语法树篇
- 2.8 对抗增强篇
3.1.2 [主动学习 面试篇]
-
一、动机篇
-
- 1.1 主动学习是什么?
- 1.2 为什么需要主动学习?
-
二、主动学习篇
-
- 2.1 主动学习的思路是什么?
- 2.2 主动学习方法 的价值点在哪里?
-
三、样本选取策略篇
-
- 3.2.1 测试集内选取 “信息” 量最大的数据标记
- 3.2.2 依赖不确定度的样本选取策略(Uncertainty Sampling, US)
- 3.2.3 基于委员会查询的方法(Query-By-Committee,QBC)
- 3.1 以未标记样本的获取方式的差别进行划分
- 3.2 测试集内选取 “信息” 量最大的数据标记
3.1.3 [数据增强 之 对抗训练 面试篇]
-
一、介绍篇
-
- 1.1 什么是 对抗训练 ?
- 1.2 为什么 对抗训练 能够 提高模型效果?
- 1.3 对抗训练 有什么特点?
- 1.4 对抗训练 的作用?
-
二、概念篇
-
- 2.1 对抗训练的基本概念?
- 2.2 如何计算扰动?
- 2.3 如何优化?
-
三、实战篇
-
- 3.1 NLP 中经典对抗训练 之 Fast Gradient Method(FGM)
- 3.2 NLP 中经典对抗训练 之 Projected Gradient Descent(PGD)
3.2 [“脏数据” 处理 面试篇]
-
一、动机
-
- 1.1 何为 “脏数据”?
- 1.2 “脏数据” 会带来什么后果?
-
二、“脏数据” 处理篇
-
- 2.2.1 什么是 置信学习方法?
- 2.2.2 置信学习方法 优点?
- 2.2.3 置信学习方法 怎么做?
- 2.2.4 置信学习方法 怎么用?有什么开源框架?
- 2.2.5 置信学习方法 的工作原理?
- 2.1 “脏数据” 怎么处理呢?
- 2.2 置信学习方法篇
点击查看答案
3.3 [batch_size 设置 面试篇]
- 一、训练模型时,batch_size 的设置,学习率的设置?
- 一、 为什么要用 早停法 EarlyStopping?
- 二、 早停法 EarlyStopping 是什么?
- 三、早停法 torch 版本怎么实现?
3.5 [标签平滑法 LabelSmoothing 面试篇]
- 一、为什么要有 标签平滑法 LabelSmoothing?
- 二、 标签平滑法 是什么?
- 三、 标签平滑法 torch 怎么复现?
3.6 Bert Trick 面试篇
3.6.1 [Bert 未登录词处理 面试篇]
- 什么是 Bert 未登录词?
- Bert 未登录词 如何处理?
- Bert 未登录词各种处理方法 有哪些优缺点?
3.6.2 [BERT 在输入层引入额外特征 面试篇]
- BERT 在输入层如何引入额外特征?
3.6.3 [关于 BERT 继续预训练 面试篇]
- 什么是 继续预训练?
- 为什么会存在 【数据分布 / 领域差异】大 问题?
- 如何进行 继续预训练?
- 还有哪些待解决问题?
- 训练数据问题解决方案?
- 知识缺乏问题解决方案?
- 知识理解缺乏问题解决方案?
3.6.4 [BERT 如何处理篇章级长文本 面试篇]
- 为什么 Bert 不能 处理 长文本?
- BERT 有哪些处理篇章级长文本?
- Prompt Tuning 面试篇
4.1 [Prompt 面试篇]
- 什么是 prompt?
- 如何设计 prompt?
- prompt 进阶——如何自动学习 prompt?
- Prompt 有哪些关键要点?
- Prompt 如何实现?
4.2 [Prompt 文本生成 面试篇]
- Prompt 之文本生成评估手段有哪些?
- Prompt 文本生成具体任务有哪些?
4.3 [LoRA 面试篇]
- 什么是 lora?
- lora 是 怎么做的呢?
- lora 为什么可以这样做?
- 用一句话描述 lora?
- lora 优点是什么?
- lora 缺点是什么?
- lora 如何实现?
4.4 [PEFT(State-of-the-art Parameter-Efficient Fine-Tuning)面试篇]
-
一、微调 Fine-tuning 篇
-
- 1.1 什么是 微调 Fine-tuning ?
- 1.2 微调 Fine-tuning 基本思想是什么?
-
二、轻度微调(lightweight Fine-tuning)篇
-
- 2.1 什么是 轻度微调(lightweight Fine-tuning)?
-
三、适配器微调(Adapter-tuning)篇
-
- 3.1 什么 是 适配器微调(Adapter-tuning)?
- 3.2 适配器微调(Adapter-tuning)变体有哪些?
-
四、提示学习(Prompting)篇
-
- 4.3.1 前缀微调(Prefix-tining)篇
- 4.3.2 指示微调(Prompt-tuning)篇
- 4.3.3 P-tuning 篇
- 4.3.4 P-tuning v2 篇
- 4.3.5 PPT 篇
- 4.3.1.1 什么是 前缀微调(Prefix-tining)?
- 4.3.1.2 前缀微调(Prefix-tining)的核心是什么?
- 4.3.1.3 前缀微调(Prefix-tining)的技术细节有哪些?
- 4.3.1.4 前缀微调(Prefix-tining)的优点是什么?
- 4.3.1.5 前缀微调(Prefix-tining)的缺点是什么?
- 4.3.2.1 什么是 指示微调(Prompt-tuning)?
- 4.3.2.2 指示微调(Prompt-tuning)的核心思想?
- 4.3.2.3 指示微调(Prompt-tuning)的 优点 / 贡献 是什么?
- 4.3.2.4 指示微调(Prompt-tuning)的 缺点 是什么?
- 4.3.2.5 指示微调(Prompt-tuning)与 Prefix-tuning 区别 是什么?
- 4.3.2.6 指示微调(Prompt-tuning)与 fine-tuning 区别 是什么?
- 4.3.3.1 P-tuning 动机是什么?
- 4.3.3.2 P-tuning 核心思想是什么?
- 4.3.3.3 P-tuning 做了哪些改进?
- 4.3.3.4 P-tuning 有哪些优点 / 贡献?
- 4.3.3.5 P-tuning 有哪些缺点?
- 4.3.4.1 为什么需要 P-tuning v2?
- 4.3.4.2 P-tuning v2 是什么?
- 4.3.4.3 P-tuning v2 有哪些优点?
- 4.3.4.4 P-tuning v2 有哪些缺点?
- 4.3.5.1 为什么需要 PPT ?
- 4.3.5.2 PPT 核心思想 是什么?
- 4.3.5.3 PPT 具体做法是怎么样?
- 4.3.5.4 常用的 soft prompt 初始化方法?
- 4.3.5.5 PPT 的优点是什么?
- 4.3.5.6 PPT 的缺点是什么?
- 4.1 什么是 提示学习(Prompting)?
- 4.2 提示学习(Prompting)的目的是什么?
- 4.3 提示学习(Prompting) 代表方法有哪些?
- 4.4 提示学习(Prompting) 优点 是什么?
- 4.5 提示学习(Prompting) 本质 是什么?
-
五、指令微调(Instruct-tuning)篇
-
- 5.1 为什么需要 指令微调(Instruct-tuning)?
- 5.2 指令微调(Instruct-tuning)是什么?
- 5.3 指令微调(Instruct-tuning)的优点是什么?
- 5.4 指令微调(Instruct-tuning) vs 提升学习(Prompting)?
- 5.5 指令微调(Instruct-tuning) vs 提升学习(Prompting) vs Fine-tuning?
-
六、指令提示微调(Instruct Prompt tuning)篇
-
- 6.1 为什么需要 指令微调(Instruct-tuning)?
- 6.2 指令微调(Instruct-tuning) 是什么?
- 6.3 指令微调(Instruct-tuning) 在不同任务上性能?
-
七、self-instruct 篇
-
- 7.1 什么是 self-instruct?
-
八、Chain-of-Thought 篇
-
- 8.1 为什么需要 Chain-of-Thought ?
- 8.2 什么是 Chain-of-Thought ?
- 8.3 Chain-of-Thought 的思路是怎么样的?
- 8.4 Chain-of-Thought 的优点是什么?
- 8.5 为什么 chain-of-thought 会成功?
-
九、LoRA 篇
-
- 9.3.1 AdaLoRA 动机是什么?
- 9.3.2 AdaLoRA 核心思想是什么?
- 9.3.3 AdaLoRA 优点是什么?
- 9.2.1 AdaLoRA 核心思想是什么?
- 9.2.2 AdaLoRA 实现思路是什么?
- 9.1.1 LoRA 核心思想是什么?
- 9.1.2 LoRA 具体思路是什么?
- 9.1.3 LoRA 优点是什么?
- 9.1.4 LoRA 缺点是什么?
- 9.1 LoRA 篇
- 9.2 AdaLoRA 篇
- 9.3 DyLoRA 篇
-
十、BitFit 篇
-
- 10.1 AdaLoRA 核心思想是什么?
- 10.2 AdaLoRA 优点是什么?
- 10.3 AdaLoRA 缺点是什么?
5.LLMs 面试篇
5.1 [【现在达模型 LLM,微调方式有哪些?各有什么优缺点?]
- 现在达模型 LLM,微调方式有哪些?各有什么优缺点?
5.2 [GLM:ChatGLM 的基座模型 常见面试题]
- GLM 的 核心是什么?
- GLM 的 模型架构是什么?
- GLM 如何进行 多任务训练?
- 在进行 NLG 时, GLM 如何保证 生成长度的未知性?
- GLM 的 多任务微调方式有什么差异?
- GLM 的 多任务微调方式有什么优点?
qwen2.5 Llama 3.2 同理
人工智能122
人工智能 · 目录
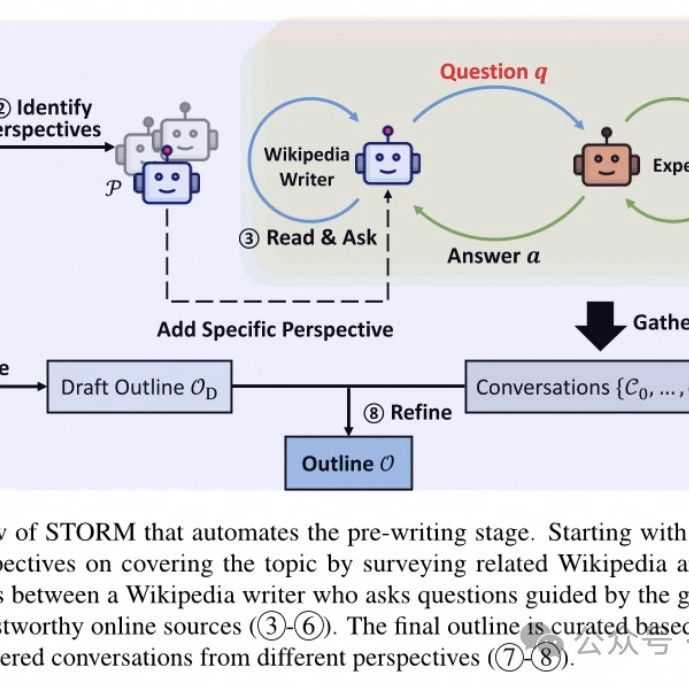
上一篇【多 Agent 协作论文解读】采用 STORM 模式更好利用 LLM 撰写长文章,基于 Dify 复现
阅读 95
喜欢此内容的人还喜欢
【多 Agent 协作论文解读】采用 STORM 模式更好利用 LLM 撰写长文章,基于 Dify 复现
我常看的号
汀丶人工智能
不喜欢
不看的原因
确定
- 内容低质
- 不看此公众号内容
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 86万+
86万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









