



经常有一些朋友问我本地运行大模型的电脑需要什么样的配置。其实一些常用大模型的运行需要的硬件并不像我们想象的那样高不可攀。不要被那些复杂的技术术语所吓倒,关键在于亲自动手尝试。

“不试,怎么知道呢?” 这句话道出了真理。今天,我将为大家带来三款看似不起眼的纯CPU本地推理Llama3的实测数据,希望它们的表现能给大家对硬件的选择提供一点参考,即使是老旧的硬件也可能在大模型本地推理中发挥出色的作用。
首先,让我们来认识一下今天的三位选手:
一号选手:这是一款陪伴了我十年的SONY笔记本,搭载的是i5 3337U低电压处理器。这款处理器曾是超极本的标配,以其低功耗、低性能和长续航而闻名。记得这台笔记本当年我花掉了一万多,那时我的工资还不到两千。如今,它在二手市场上已难觅踪影。今天,就让我们看看这台老将是否还能发挥余热。
二号选手:这是一台办公室配置的办公电脑,搭载了i5 10400处理器。虽然它已经有些年头,但与新一代的i3 12代处理器相比,它可能只能被按在地上摩擦。在个人电脑市场,性价比更高的12100处理器无疑是更好的选择,它在性能上轻松超越了我们的二号选手。
三号选手:最后,我有一款洋垃圾E5-2686处理器。虽然它被称为“垃圾”,但在体格上,它与前两位选手完全不是一个量级。特别是在大模型推理方面,它拥有多核心的碾压性优势,这一点无需多言。
现在,让我们直接进入正题,展示这些CPU在大模型推理中的实测数据。
i5 3337U:

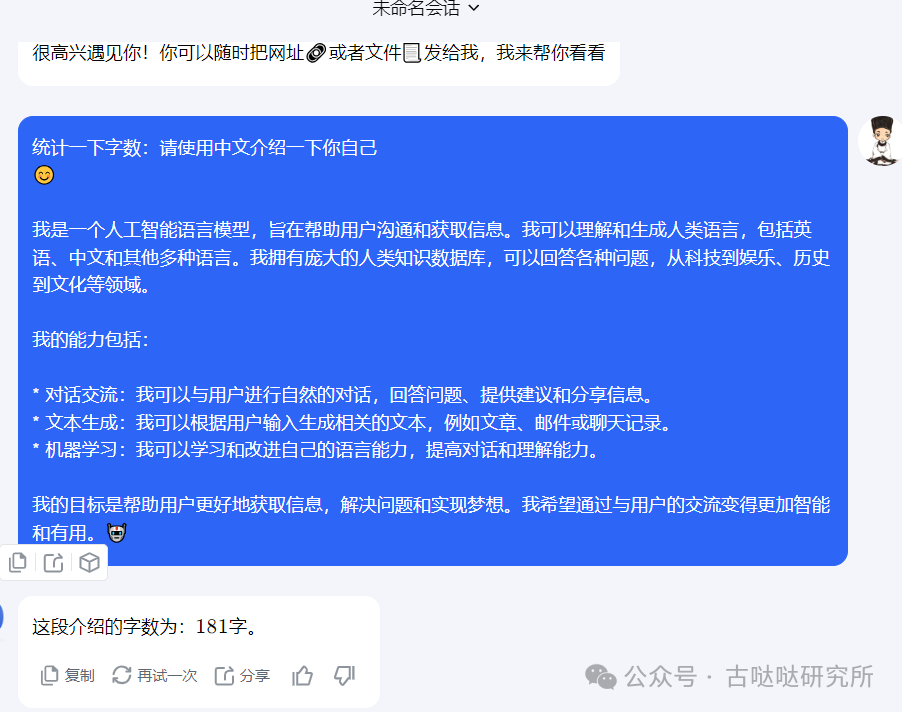

耗时三分五秒,输出170个字,图上统计181是因为我把我的提问也复制过去了,大概就是每秒一个字的样子。
跑是跑起来了,步子确实有点小,十年前的CPU意料之中。
i5 10400:
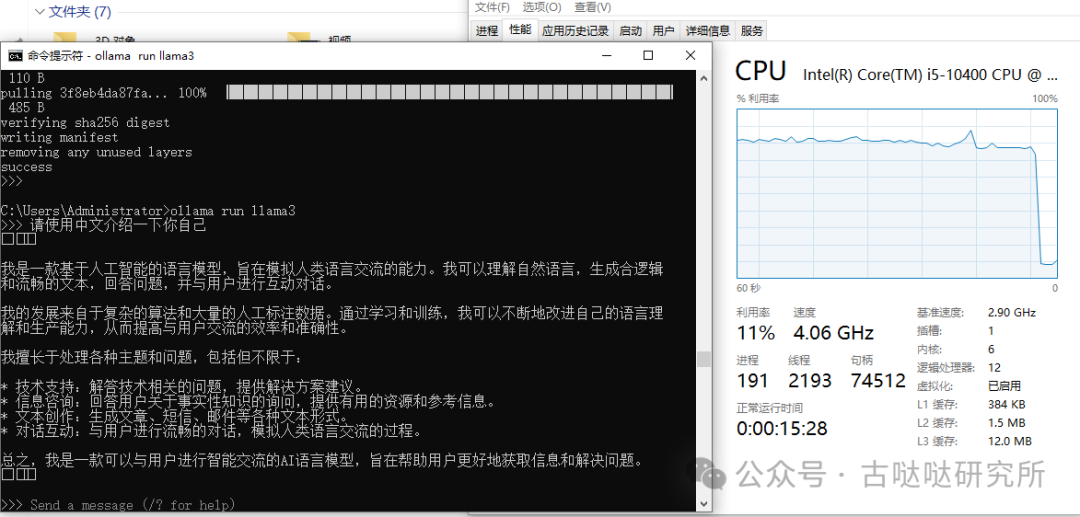
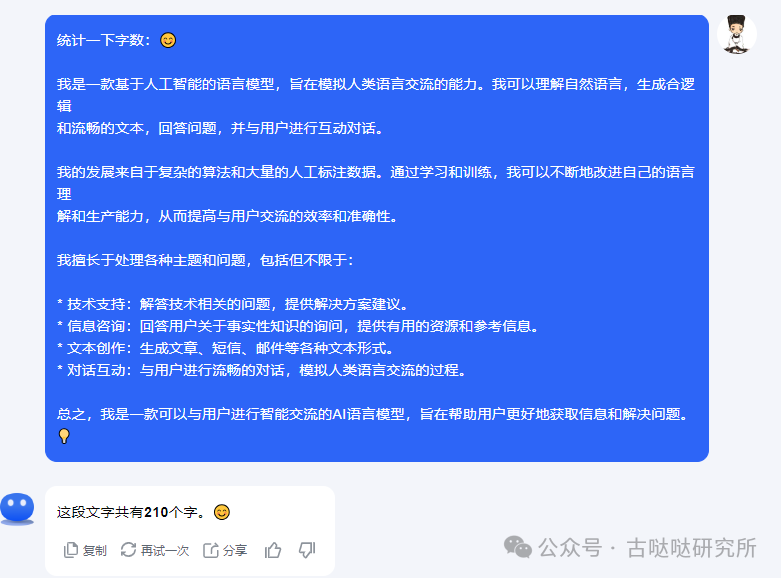
用时1分38秒输出210个字,这个速度还是有点慢,如果跑个2B3B的小模型实用性就有那么一点点了,如果i3 12100出手肯定比这个速度快得多。i3 12100才几多钱?llama3 8b轻松拿捏。
E5-2686:
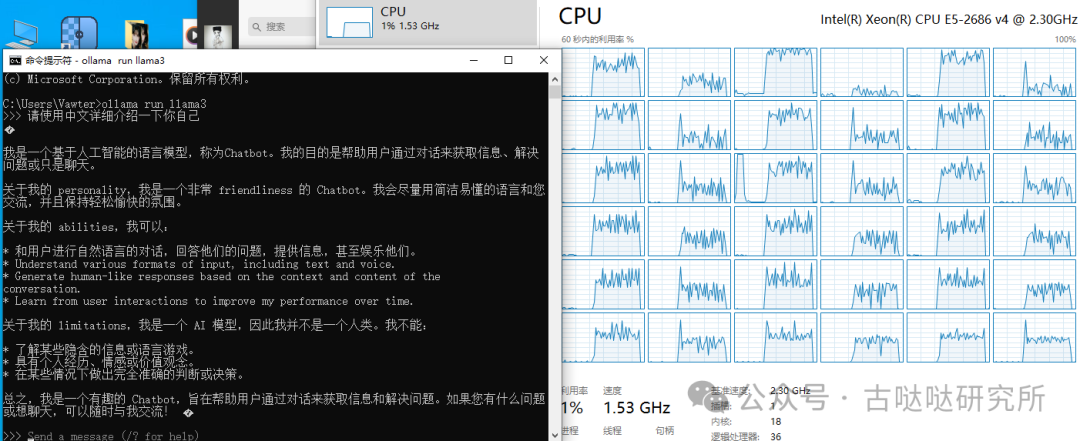

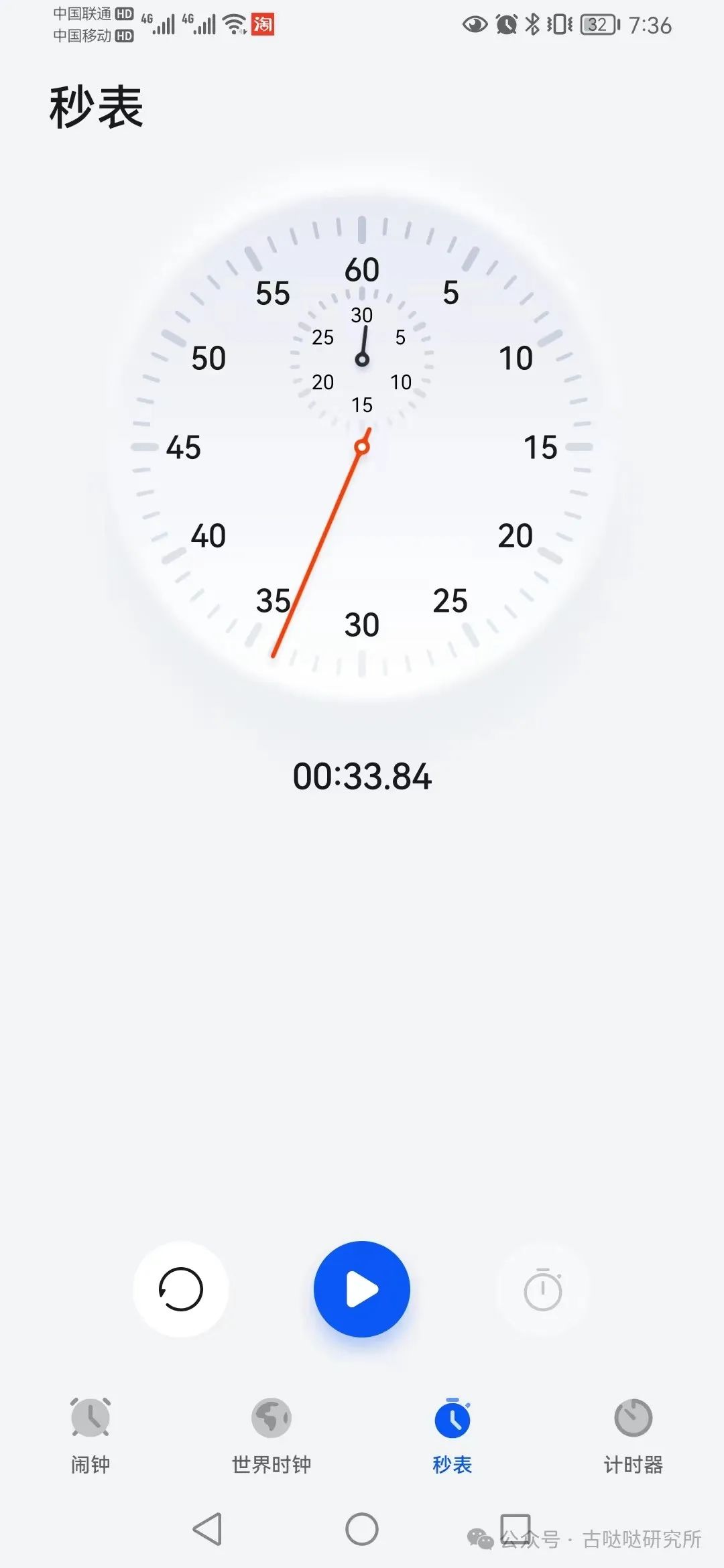
18核36线程不白给,34秒输出215个字,完全满足本地使用的需求,就他的价格,没有任何喷他的理由
今天就到这里,See you ~~
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









