





 文章讲述了网络爬虫在大数据时代的重要作用,特别是在帮助企业收集和分析公开数据方面。通过Python爬虫技术,企业可以自动化、实时获取所需信息,如竞品分析、市场动态,从而优化决策。文中提出了一条从基础Python包学习到构建复杂爬虫框架,再到应对反爬策略和分布式爬虫的学习路径,强调了实践和具体目标的重要性。
文章讲述了网络爬虫在大数据时代的重要作用,特别是在帮助企业收集和分析公开数据方面。通过Python爬虫技术,企业可以自动化、实时获取所需信息,如竞品分析、市场动态,从而优化决策。文中提出了一条从基础Python包学习到构建复杂爬虫框架,再到应对反爬策略和分布式爬虫的学习路径,强调了实践和具体目标的重要性。
数据量爆发式增长的互联网时代,网站与用户的沟通本质上是数据的交换:搜索引擎从数据库中提取搜索结果,将其展现在用户面前;电商将产品的描述、价格展现在网站上,以供买家选择心仪的产品;社交媒体在用户生态圈的自我交互下产生大量文本、图片和视频数据等。
这些数据如果得以分析利用,不仅能够帮助第一方企业(拥有这些数据的企业)做出更好的决策,对于第三方企业也是有益的。而网络爬虫技术,则是大数据分析领域的第一个环节。

网络爬虫能带来什么好处
大量企业和个人开始使用网络爬虫采集互联网的公开数据。那么对于企业而言,互联网上的公开数据能够带来什么好处呢?这里将用国内某家知名家电品牌举例说明。
作为一个家电品牌,电商市场的重要性日益凸显。该品牌需要及时了解对手的产品特点、价格以及销量情况,才能及时跟进产品开发进度和营销策略,从而知己知彼,赢得竞争。过去,为了获取对手产品的特点,产品研发部门会手动访问一个个电商产品页面,人工复制并粘贴到Excel表格中,制作竞品分析报告。但是这种重复性的手动工作不仅浪费宝贵的时间,一不留神复制少了一个数字还会导致数据错误;此外,竞争对手的销量则是由某一家咨询公司提供报告,每周一次,但是报告缺乏实时性,难以针对快速多变的市场及时调整价格和营销策略。针对上述两个痛点——无法自动化和无法实时获取,本书介绍的网络爬虫技术都能够很好地解决,实现实时自动化获取数据。
上面的例子仅为数据应用的冰山一角。近几年来,随着大数据分析的火热,毕竟有数据才能进行分析,网络爬虫技术已经成为大数据分析领域的第一个环节。
对于这些公开数据的应用价值,我们可以使用KYC框架来理解,也就是Know Your Company(了解你的公司)、Know Your Competitor(了解你的竞争对手)、Know Your Customer(了解你的客户)。通过简单描述性分析,这些公开数据就可以带来很大的商业价值。进一步讲,通过深入的机器学习和数据挖掘,在营销领域可以帮助企业做好4P(Product:产品创新,Place:智能选址,Price:动态价格,Promotion:个性化营销活动);在金融领域,大数据征信、智能选股等应用会让公开数据带来越来越大的价值。
那我们想要学习爬虫对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情,但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现,但建议你从一开始就要有一个具体的目标。
在目标的驱动下,你的学习才会更加精准和高效。**那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。**基于python爬虫,我们整理了一个完整的学习框架:
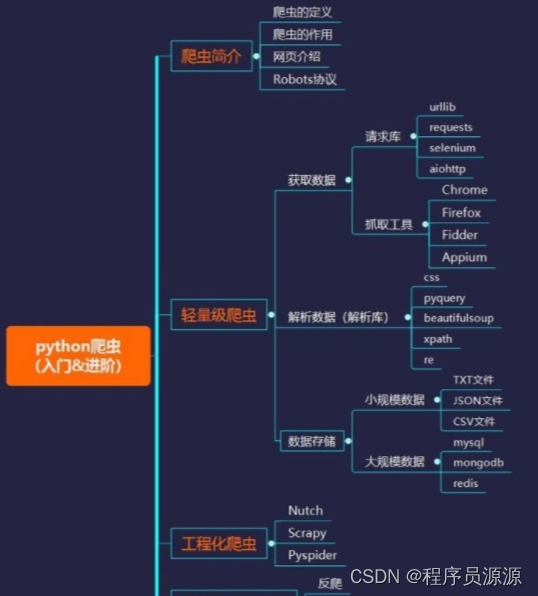
1、学习 Python 包并实现基本的爬虫过程
大部分爬虫都是按 “ 发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。这样下来基本套路都差不多,一般的静态网站根本不在话下。当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化。
文章到这里我想要推荐下我的资料!目前python是一门相对应比较火爆的编程语言,应用范围也非常的广泛,但目前竞争不大,工资也算乐观,未来发展也极好
但是对python这个行业根本不了解的情况下,一味的买书看书、看视频,是很难达到预想的效果的,甚至到了中期阶段可能会萌生放弃的想法。
很多初学者也是因为这些原因走入了学习的误区,那么初学者应该怎样学习Python呢,需要多长的时间才能学会Python呢?
Python究竟应该怎么学呢,我自己最初也是从零基础开始学习Python的,给大家分享Python的学习思路和方法。
这里有一套Python基础学习资料包,都是我自己学习Python时候精心筛选出来的,能最好的保障你什么阶段应该学什么,需要在下面的自提。
点击免费领取《优快云大礼包》:
最新全套【Python入门到进阶资料 & 实战源码 & 安装工具】
2、了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为csv这样的文件。当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
3、学习scrapy,搭建工程化爬虫
掌握前面的技术一般量级的数据和代码基本没有问题了,但是在遇到非常复杂的情况,可能仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而它最让人惊喜的还是它超高的性能,让你可以将爬虫工程化、模块化。学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备Python爬虫工程师的思维了。
4、学习数据库知识,应对大规模数据存储与提取
爬回来的数据量小的时候,你可以用文档的形式来存储,一旦数据量大了,这就有点行不通了。所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。MongoDB 可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。
5、掌握各种技巧,应对特殊网站的反爬措施
当然,爬虫过程中也会经历一些绝望啊,比如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。遇到这些反爬虫的手段,当然还需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。往往网站在高效开发和反爬虫之间会偏向前者,这也为爬虫提供了空间,掌握这些应对反爬虫的技巧,绝大部分的网站已经难不到你了。
6、分布式爬虫,实现大规模并发采集,提升效率
爬取基本数据已经不是问题了,你的瓶颈会集中到爬取海量数据的效率。这个时候,相信你会很自然地接触到一个很厉害的名字:分布式爬虫。分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握Scrapy+ MongoDB + Redis 这三种工具。Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。所以有些东西看起来很吓人,但其实分解开来,也不过如此。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
只要按照以上的Python爬虫学习路线,一步步完成,即使是新手小白也能成为老司机,而且学下来会非常轻松顺畅。所以新手在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目,直接开始操作就好。
大家拿到脑图后,根据脑图对应的学习路线,做好学习计划制定。根据学习计划的路线来逐步学习,正常情况下2个月以内,再结合文章中资料,就能够很好地掌握Python并实现一些实践功能。

这份完整版的Python全套学习资料已经上传至优快云官方,朋友们如果需要可以扫描下方二维码免费获取【保证100%免费】

以上全套资料已经为大家打包准备好了,希望对正在学习Python的你有所帮助!
如果你觉得这篇文章有帮助,可以点个赞呀~
我会坚持每天更新Python相关干货,分享自己的学习经验帮助想学习Python的朋友们少走弯路!

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









