




 博客主要介绍了交叉熵损失函数,包含Softmax函数和NLL损失函数,阐述了似然函数用于模型参数估计。还讲解了梯度下降法,指出权重初始值设定的重要性,以及学习率在参数更新中的作用。最后展示训练结果并给出预测模块代码。
博客主要介绍了交叉熵损失函数,包含Softmax函数和NLL损失函数,阐述了似然函数用于模型参数估计。还讲解了梯度下降法,指出权重初始值设定的重要性,以及学习率在参数更新中的作用。最后展示训练结果并给出预测模块代码。
首先讲一下交叉熵损失函数,里面包含了Softmax函数和NLL损失函数
接下来讲一下NLL损失函数
Legative Log Likelihood Loss,中文名称是最大似然或者log似然代价函数
似然函数是什么呢?
似然函数就是我们有一堆观察所得得结果,然后我们用这堆观察结果对模型的参数进行估计。
举个例子:
抛一个硬币,假设正面朝上的概率是θ,那么反面朝上的概率就是1-θ
但是我们不知道θ是多少,这个θ就是模型的参数
我们为了获得θ的值,我们抛了十次,得到一个序列x=正正反反正反正正正正,获得这个序列的概率是θ⋅θ⋅(1-θ)⋅(1-θ)⋅θ⋅(1-θ)⋅θ⋅θ⋅θ⋅θ = θ⁷ (1-θ)³,我们尝试所有θ可能的值,绘制了一个图(θ的似然函数)
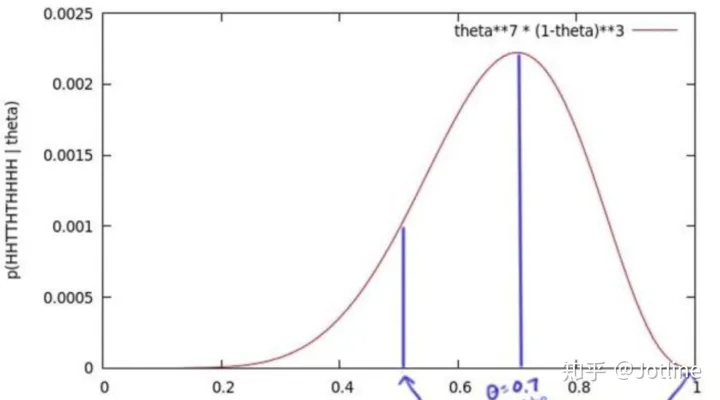
我们发现这个函数有最大值,当θ=0.7的时候,得到这个序列的概率最大,当我们实验的次数越来越多,这个最大值约接近真实值0.5。
损失函数的用途是衡量当前参数下模型的预测值和真实label的差距。似然函数损失函数当然也是如此。
在PyTorch中,CrossEntropyLoss其实是LogSoftMax和NLLLoss的合体。
交叉熵损失函数
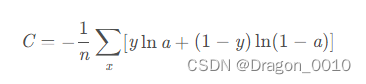
softmax函数
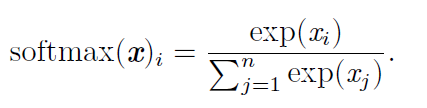
softmax一般用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
loss(x,class)=−log(exp(x[class])∑jexp(x[j]))=−x[class]+log(∑jexp(x[j]))
什么叫做梯度下降法?
顺着梯度下滑,找到最陡的方向,迈一小步,然后再找当前位,置最陡的下山方向,再迈一小步…
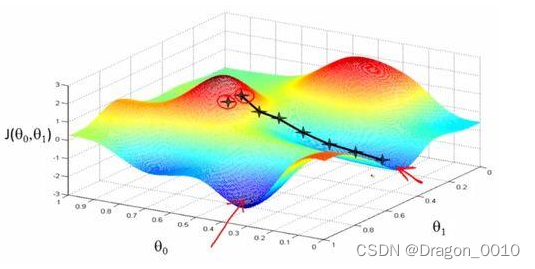
通过比较以上两个图,可以会发现,由于初始值的不同,会得到两个不同的极小值,所以权重初始值的设定也是十分重要的,通常的把W全部设置为0很容易掉到局部最优解,一般可以按照高斯分布的方式分配初始值。
当误差越大,梯度就越大,参数w(神
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









