




 本文详细介绍了如何使用Elasticsearch设计商品索引,包括属性类型选择、嵌套字段应用及搜索优化策略,旨在解决数据扁平化处理中遇到的问题。
本文详细介绍了如何使用Elasticsearch设计商品索引,包括属性类型选择、嵌套字段应用及搜索优化策略,旨在解决数据扁平化处理中遇到的问题。
PUT product
{
"mappings": {
"properties": {
"skuId": {
"type": "long"
},
"spuId": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": {
"type": "keyword"
},
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount": {
"type": "long"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"brandId": {
"type": "long"
},
"catalogId": {
"type": "long"
},
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {
"type": "keyword"
}
}
}
}
}
}https://www.elastic.co/guide/en/elasticsearch/reference/7.9/nested.html
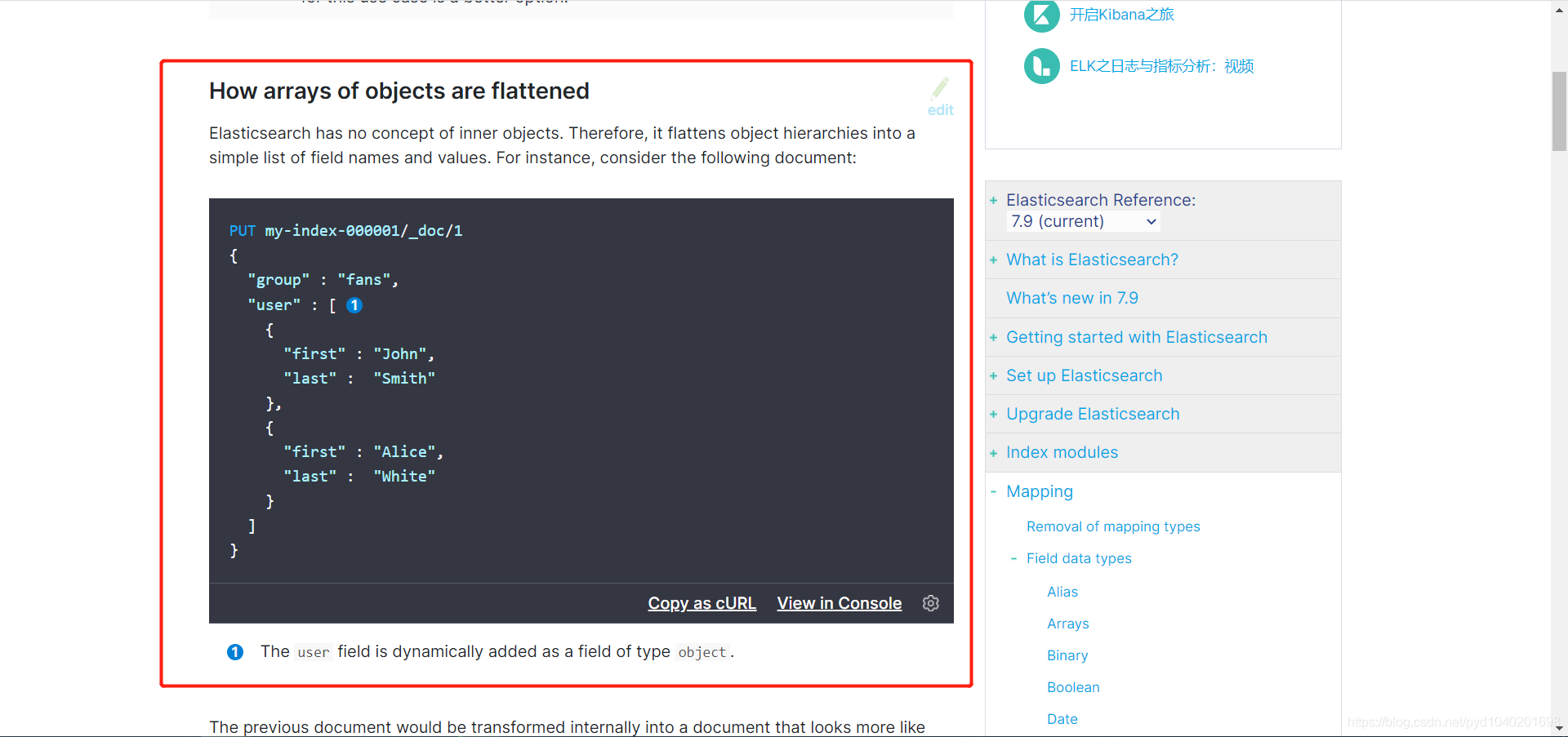
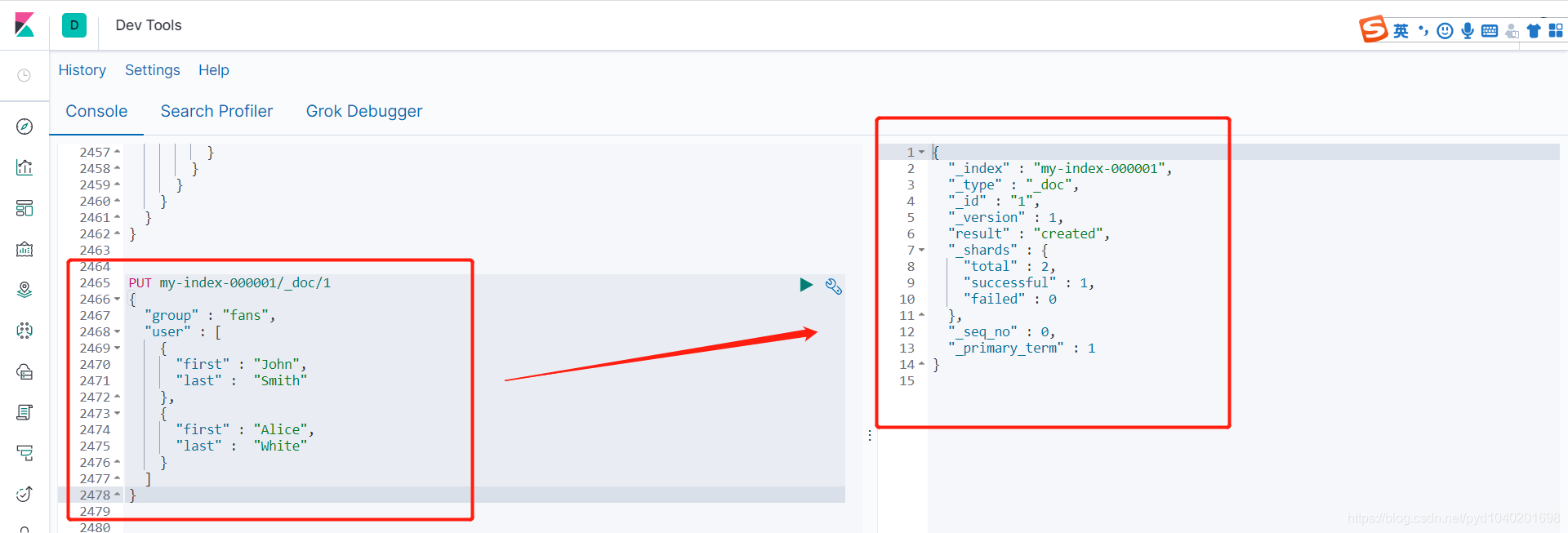
PUT my-index-000001/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
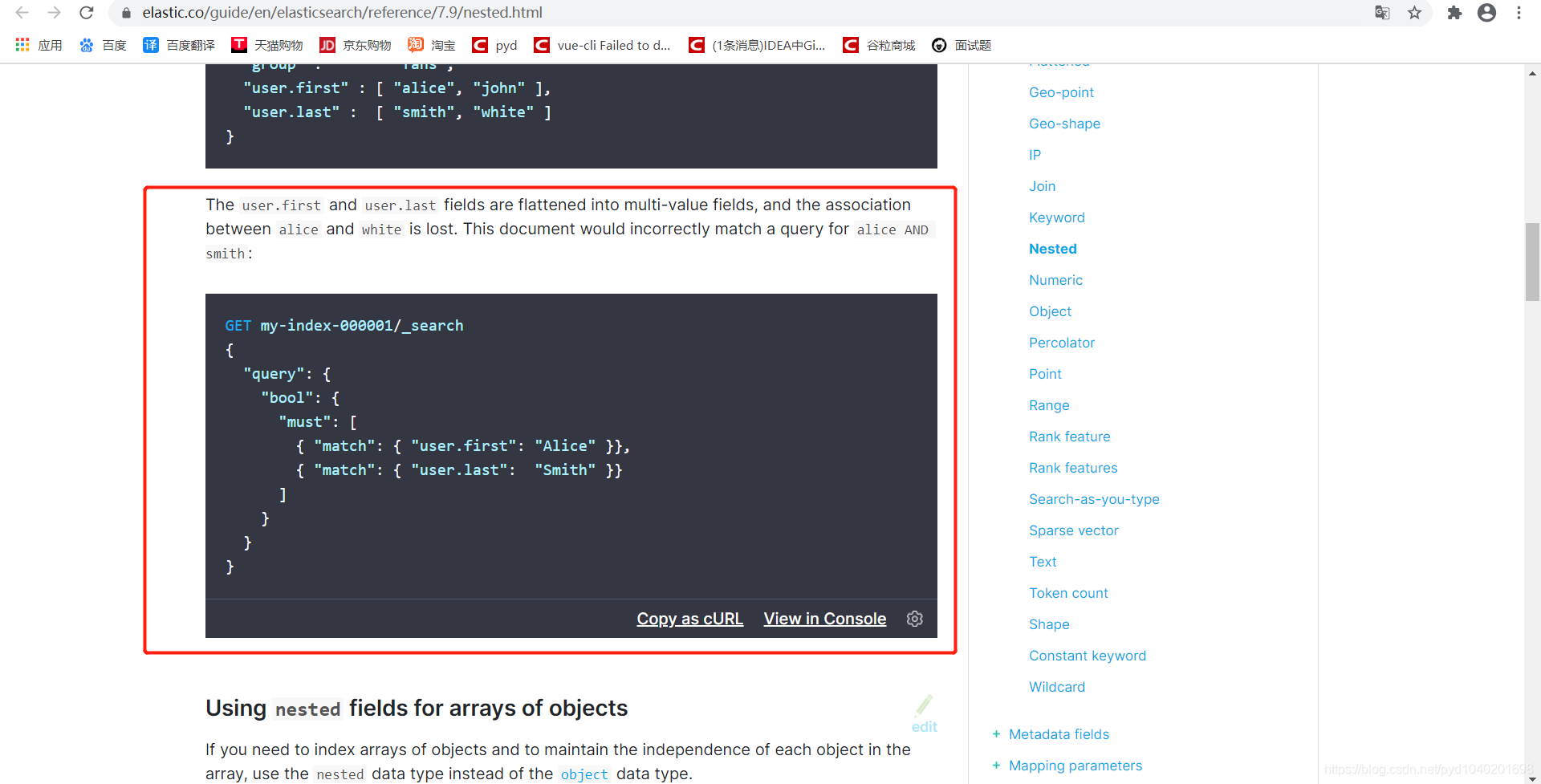
GET my-index-000001/_search
{
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}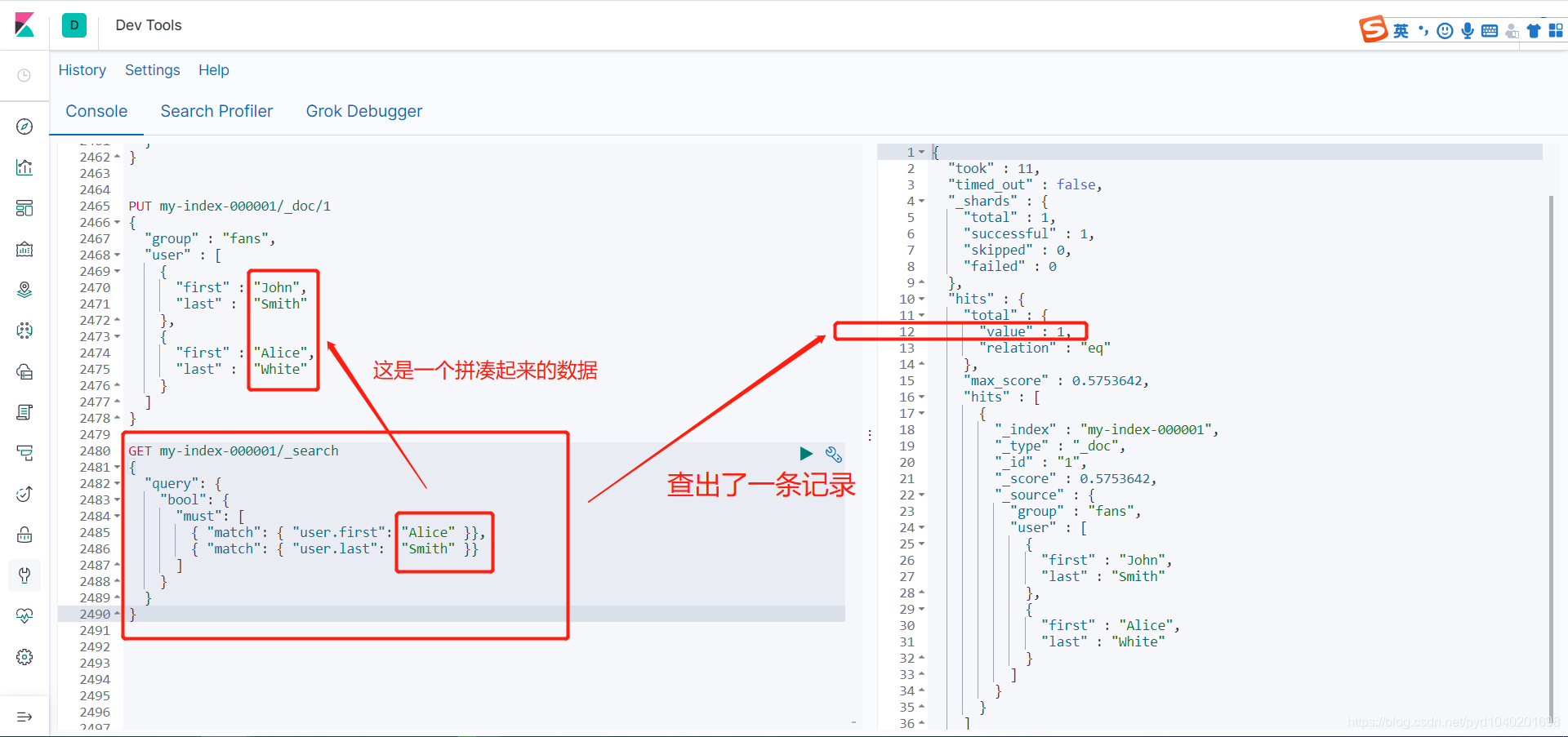
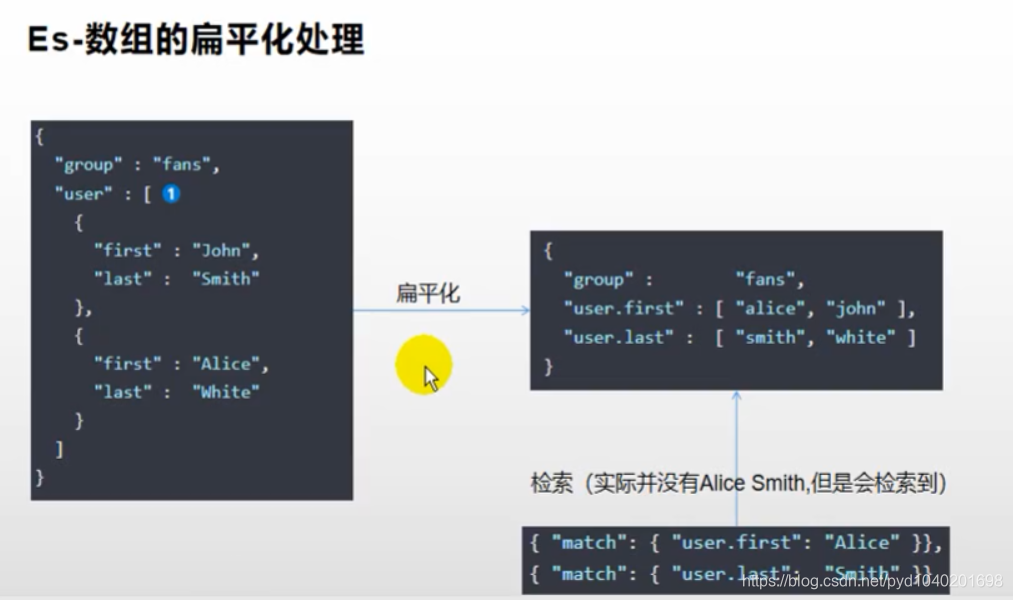
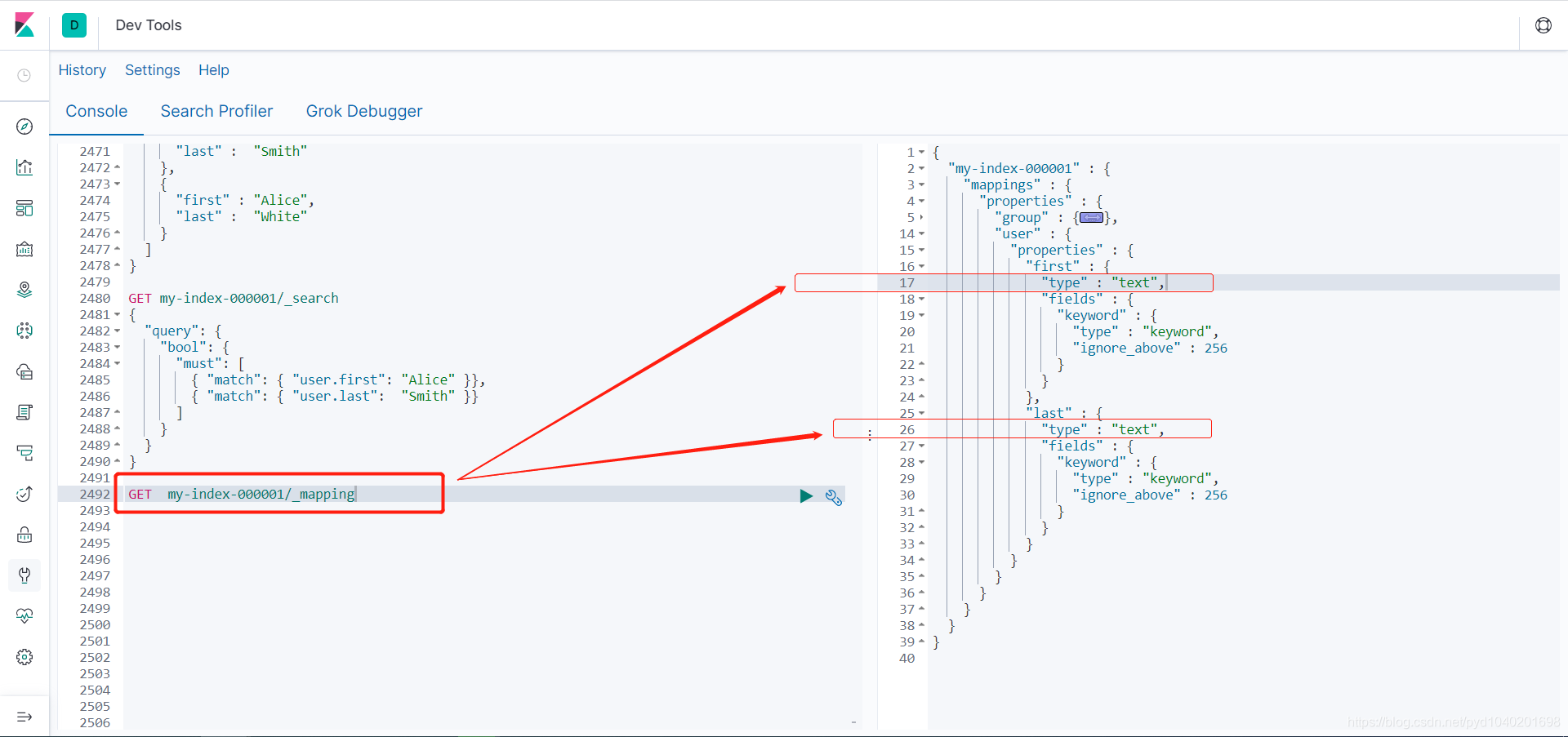
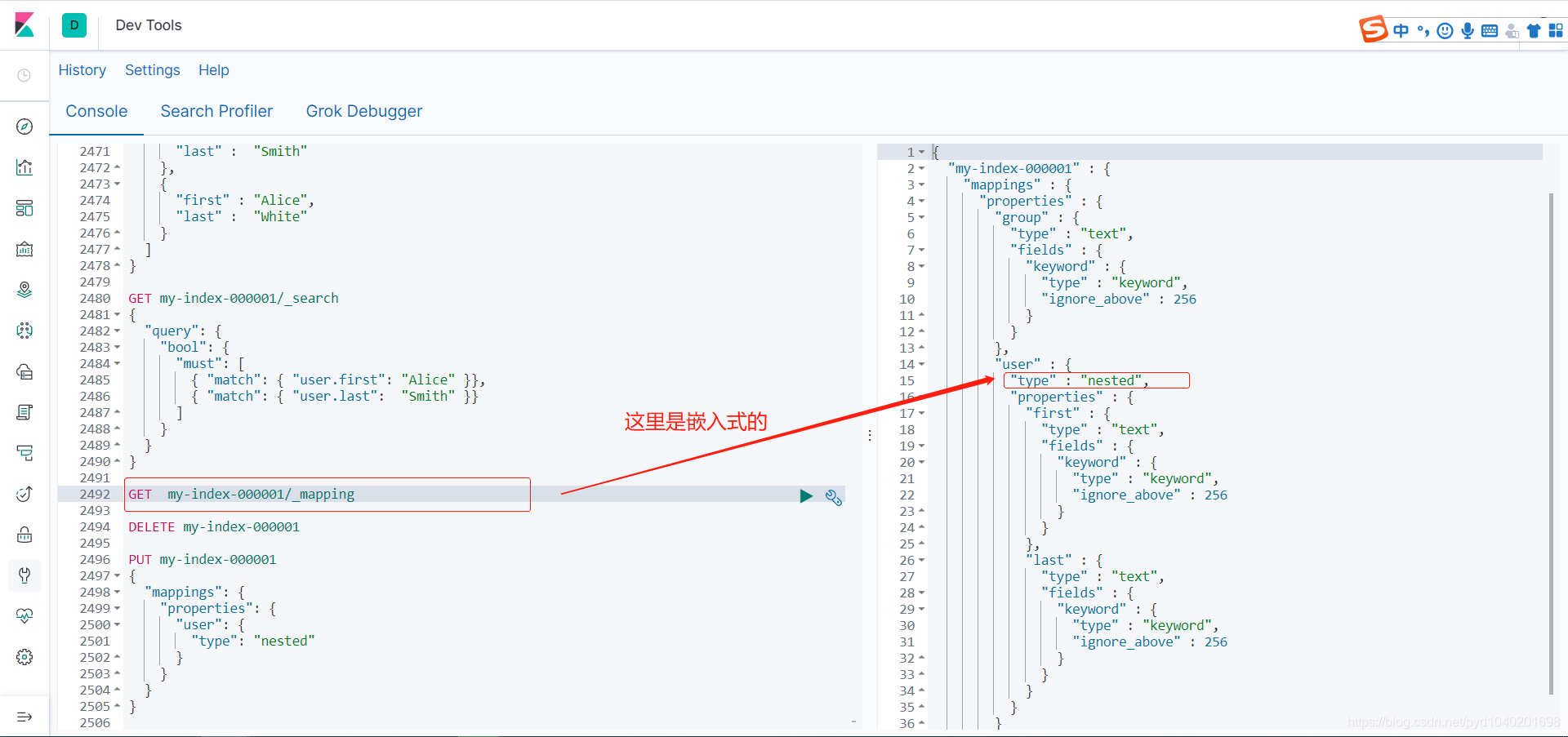
是text的,不是嵌入式的
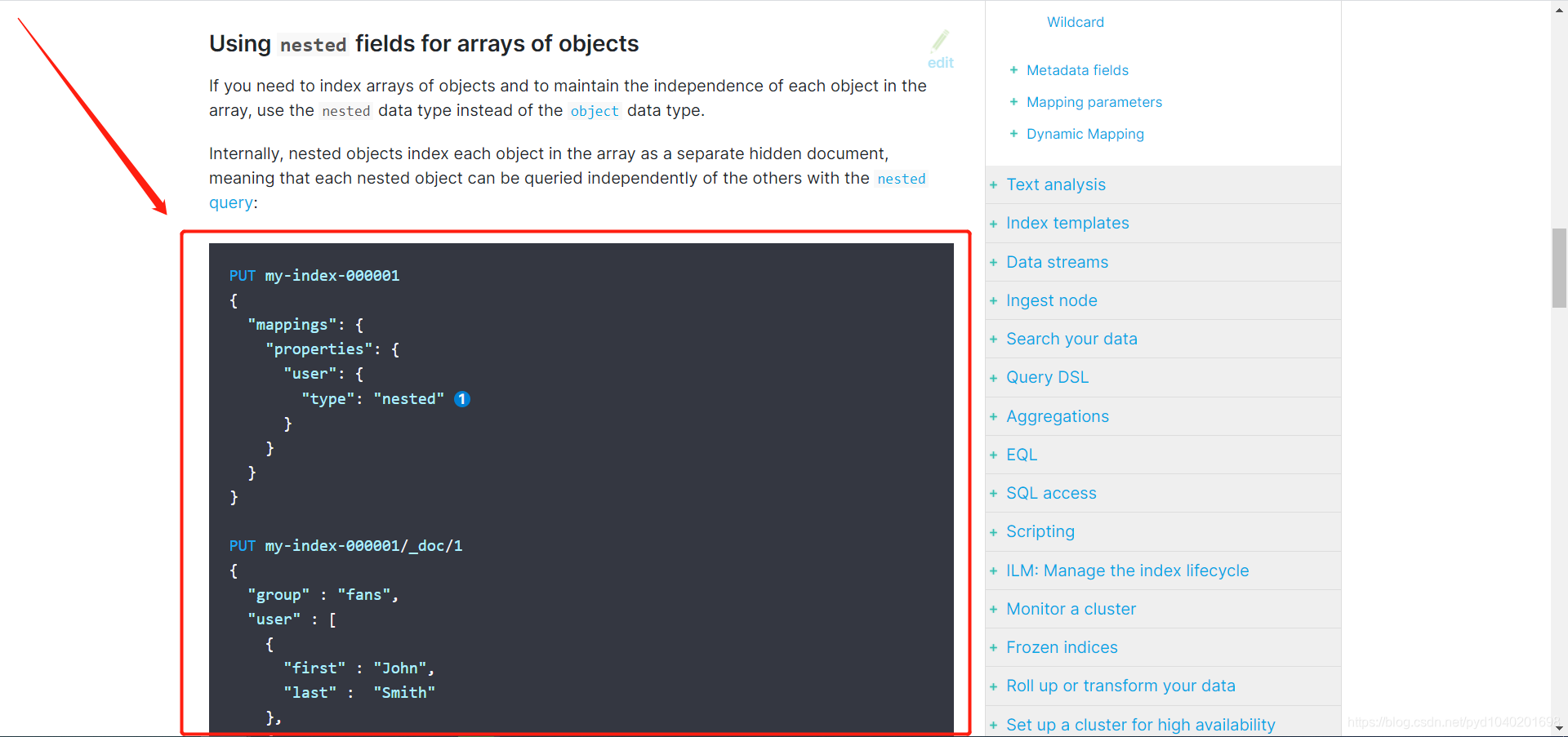
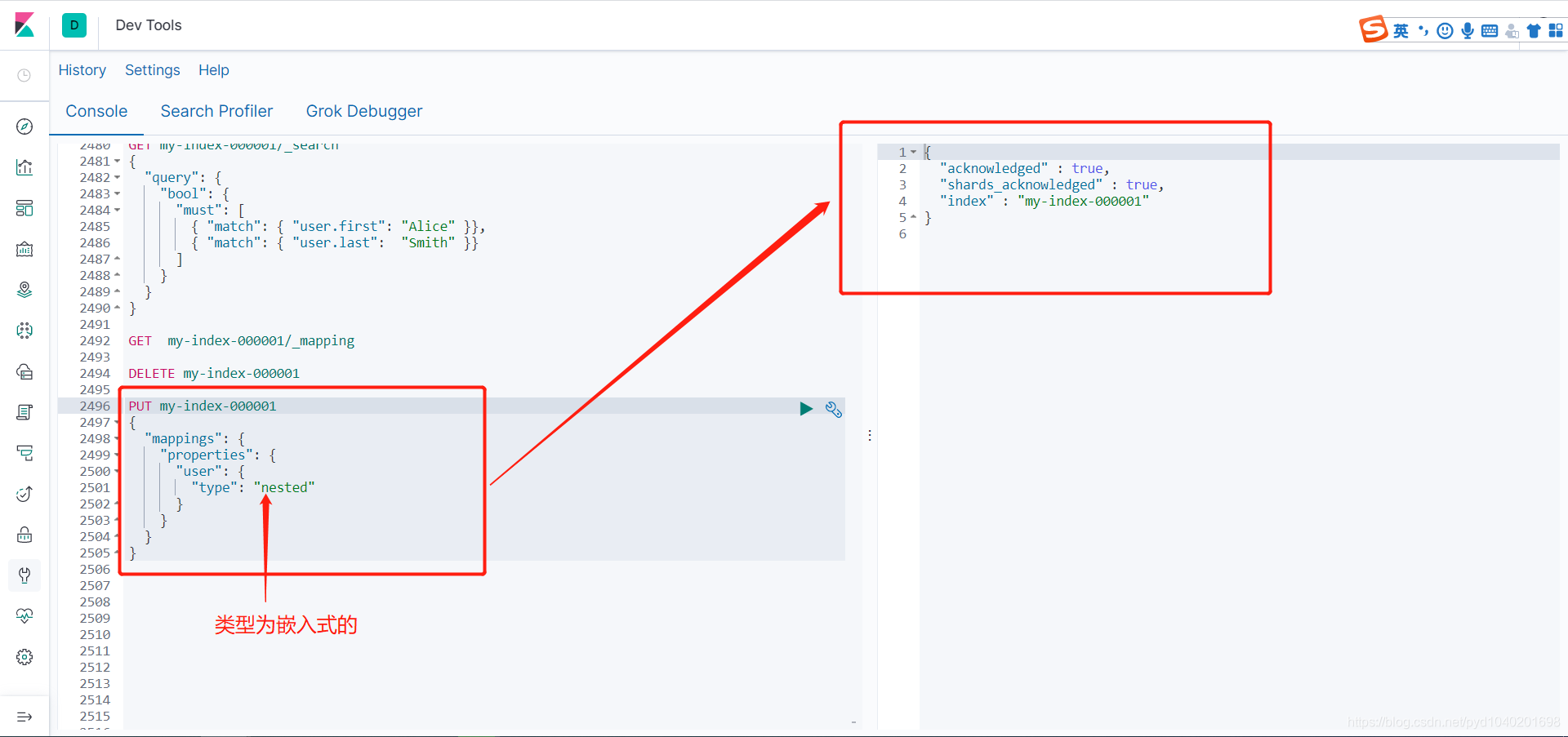
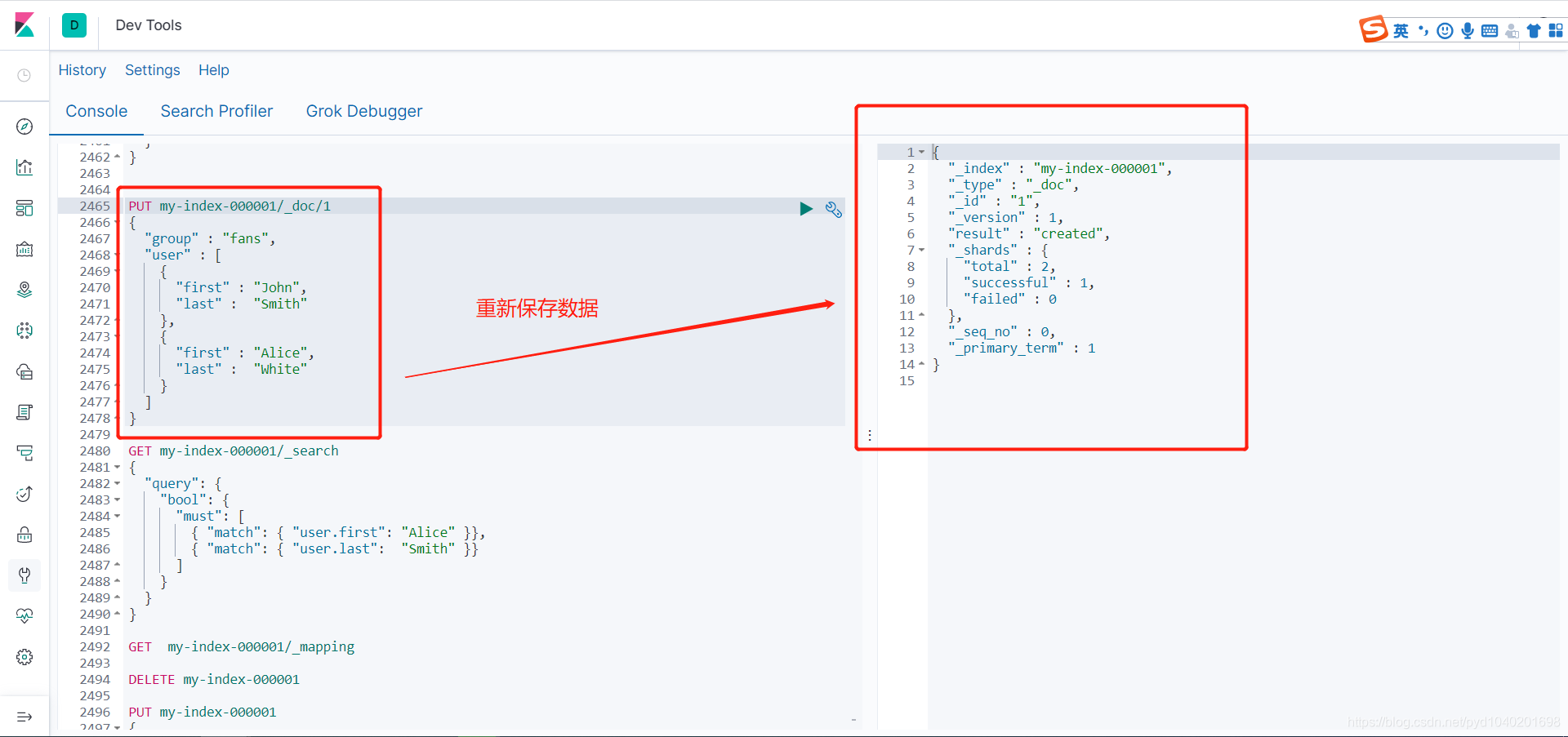
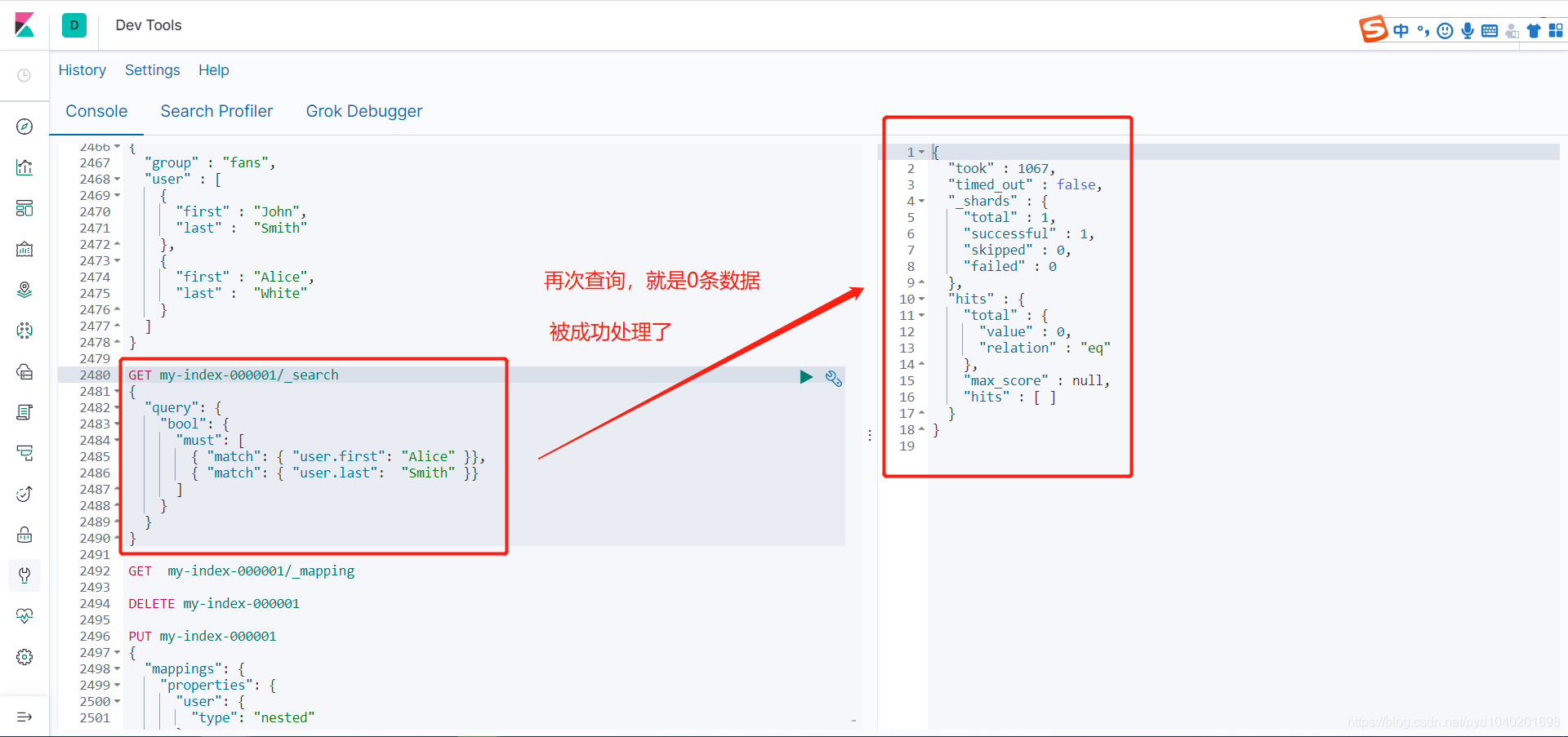
这样就处理里数据扁平化处理的错误

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









