







 本文详细探讨了商城业务中商品上架过程中,SKU在Elasticsearch中的存储模型,包括两种存储方式的优缺点分析,最终选择了以空间换取时间的第一种方案。此外,还讲解了nested数据类型在解决对象数组关联性问题上的应用,以及商品上架接口的编写、远程查询库存的处理和Feign接口的使用。整个流程涵盖了商品信息的构建、远程服务调用以及异常处理,确保商品成功上架并更新状态。
本文详细探讨了商城业务中商品上架过程中,SKU在Elasticsearch中的存储模型,包括两种存储方式的优缺点分析,最终选择了以空间换取时间的第一种方案。此外,还讲解了nested数据类型在解决对象数组关联性问题上的应用,以及商品上架接口的编写、远程查询库存的处理和Feign接口的使用。整个流程涵盖了商品信息的构建、远程服务调用以及异常处理,确保商品成功上架并更新状态。
目录
商城业务-商品上架-sku在es中存储模型的分析
首先,需要上架的商品才能被检索,可以按照sku的基本信息进行检索,例如:sku的标题、价格区间、销量、图片等,也可以按照spu的规格参数值进行检索,例如:cpu的型号、电池容量等,也可以通过分类或者品牌进行检索。
在ES中第1种数据存储格式 :
{
skuId:1
spuId:11
skuTitle: 华为
price: 998
saleCount: 100
attrs:[
{ 尺寸:5寸 }
{ cpu型号:高通998 }
{ 分辨率: 全高清 }
]
}出现的问题是:不节省空间,因为ES中的数据都是存储在内存中的
解决方案:扩展内存条,分布在多台服务器中
优点:以空间换取时间
在ES中第2种数据存储格式 :
skuIndex{
skuId:1
spuId:11
skuTitle: 华为
price: 998
saleCount: 100
}
spuIndex{
spuId:11,
attrs:[
{ 尺寸:5寸 }
{ cpu型号:高通998 }
{ 分辨率: 全高清 }
]
}出现的问题:节省了内存但是访问量增大之后会网络拥塞,典型的用时间换空间
因此,选择第一种存储模型
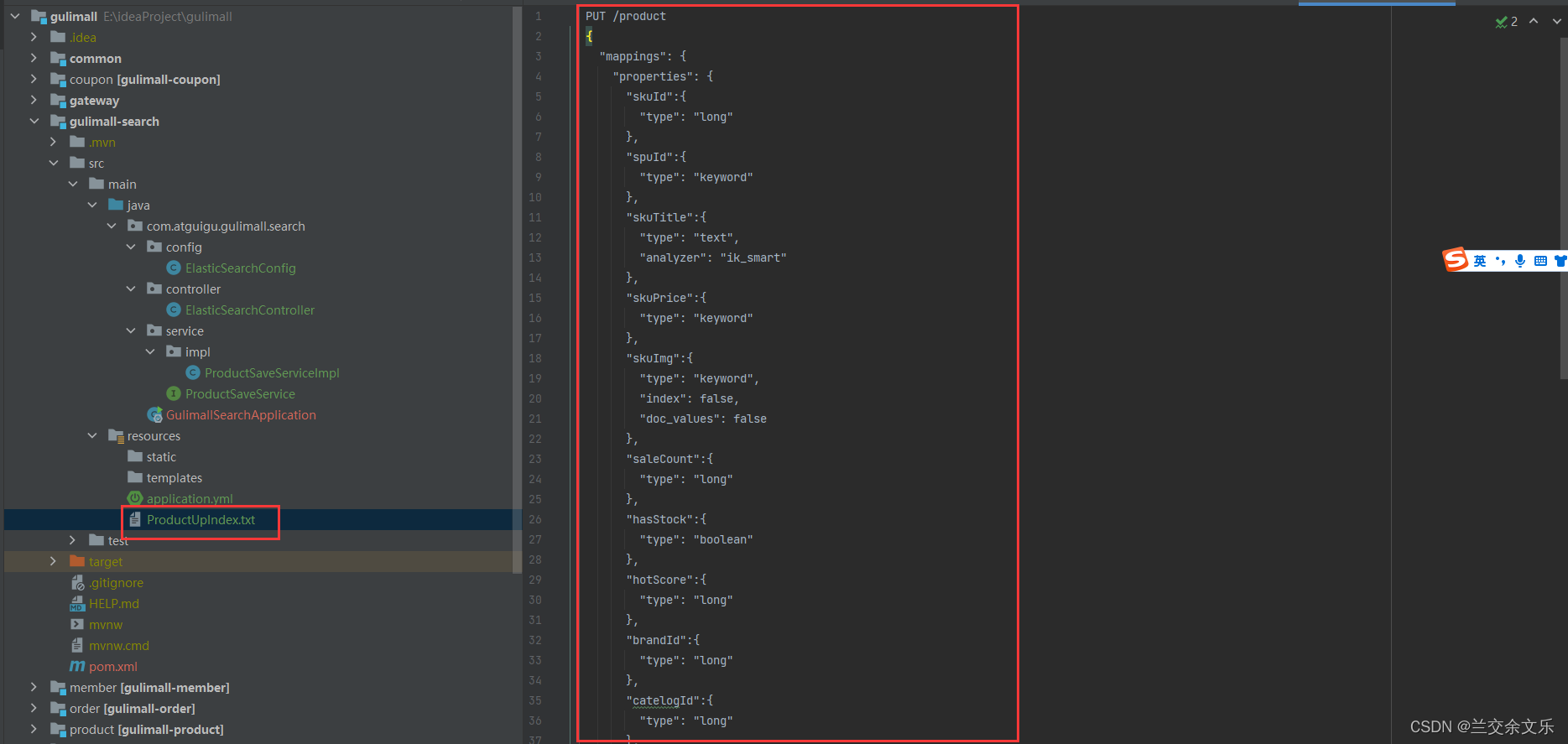
PUT /product
{
"mappings": {
"properties": {
"skuId":{
"type": "long"
},
"spuId":{
"type": "keyword"
},
"skuTitle":{
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice":{
"type": "keyword"
},
"skuImg":{
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount":{
"type": "long"
},
"hasStock":{
"type": "boolean"
},
"hotScore":{
"type": "long"
},
"brandId":{
"type": "long"
},
"catelogId":{
"type": "long"
},
"brandName":{
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg":{
"type": "keyword",
"index": false,
"doc_values": false
},
"catelogName":{
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs":{
"type": "nested",
"properties": {
"attrId":{
"type":"long"
},
"attrName":{
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue":{
"type":"keyword"
}
}
}
}
}
}分析:keyword不全文检索,text全文检索,价格使用keyword为了保存精度,hasStock表示库存,hotScore表示热度,只用于显示的数据将index和doc_values设置为false表示不参与检索和聚合,内嵌数据要用nested下面会说
商城业务-商品上架-nested数据类型场景
地址:Nested field type | Elasticsearch Guide [8.1] | Elastic
如果数组中存放的数据是对象,那么数组中的数据将会被扁平化处理
我们存储以下数据:
PUT my-index-000001/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}数组中数据就会被扁平化成这样:
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
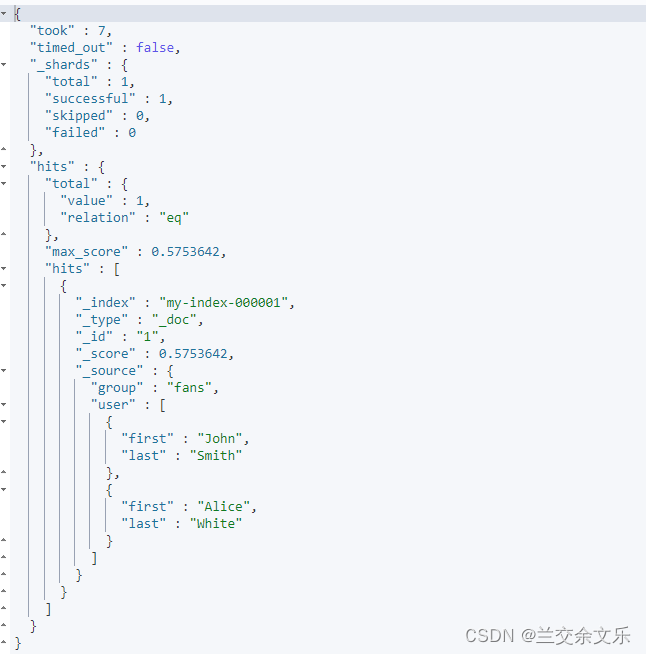
}然后我们查询alice smith就会查到结果
GET my-index-000001/_search
{
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
如果数组中的存储的为对象,不将数组的类型存储为nested,那么将会丢失关联性。例如:上面我要存储的只有Alice White但是我们搜Alice Smith也会出现结果
解决方案:将数组的类型设置为nested
DELETE my-index-000001
PUT my-index-000001
{
"mappings": {
"properties": {
"user": {
"type": "nested"
}
}
}
}
PUT my-index-000001/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
GET my-index-000001/_search
{
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
商城业务-商品上架-构造基本数据
由于product服务和search服务都要用到TO,因此,为了方便编写在common中。在实际开发中应该是product和search服务各写一个VO
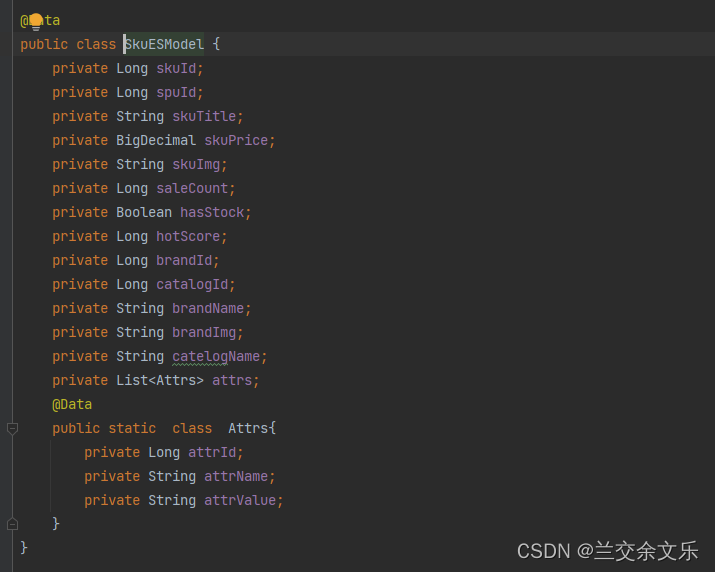
商城业务-商品上架-编写上架接口
请求路径
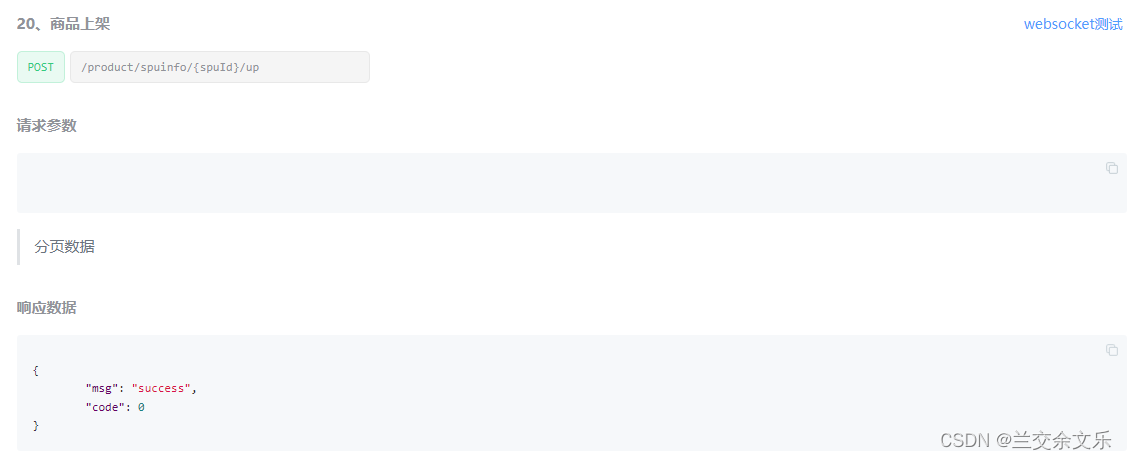
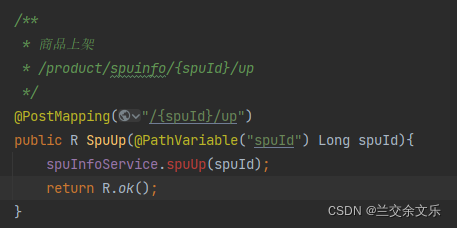
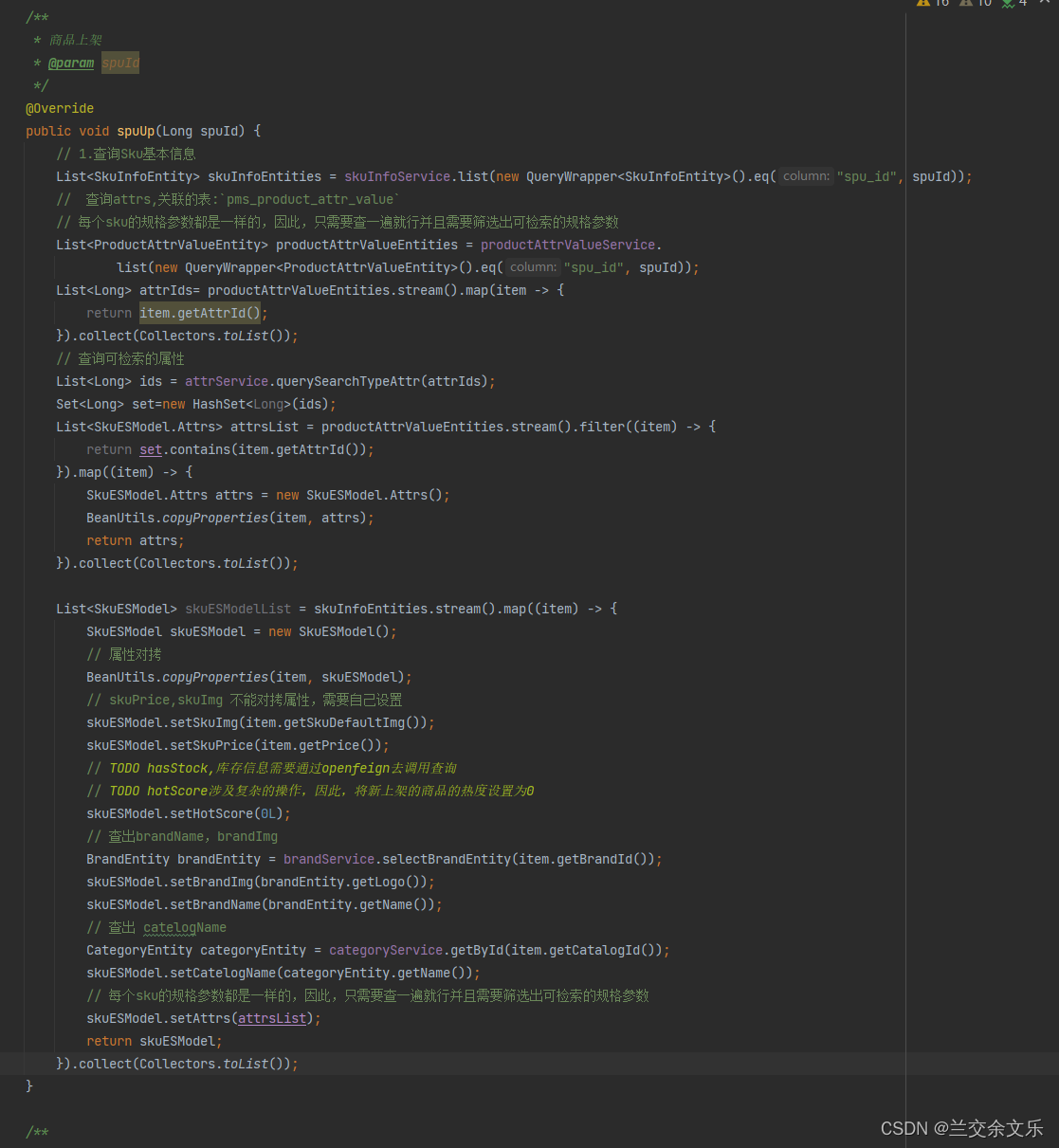
查询可检索属性的sql编写

/**
* 商品上架
* @param spuId
*/
@Override
public void spuUp(Long spuId) {
// 1.查询Sku基本信息
List<SkuInfoEntity> skuInfoEntities = skuInfoService.list(new QueryWrapper<SkuInfoEntity>().eq("spu_id", spuId));
// 查询attrs,关联的表:`pms_product_attr_value`
// 每个sku的规格参数都是一样的,因此,只需要查一遍就行并且需要筛选出可检索的规格参数
List<ProductAttrValueEntity> productAttrValueEntities = productAttrValueService.
list(new QueryWrapper<ProductAttrValueEntity>().eq("spu_id", spuId));
List<Long> attrIds= productAttrValueEntities.stream().map(item -> {
return item.getAttrId();
}).collect(Collectors.toList());
// 查询可检索的属性
List<Long> ids = attrService.querySearchTypeAttr(attrIds);
Set<Long> set=new HashSet<Long>(ids);
List<SkuESModel.Attrs> attrsList = productAttrValueEntities.stream().filter((item) -> {
return set.contains(item.getAttrId());
}).map((item) -> {
SkuESModel.Attrs attrs = new SkuESModel.Attrs();
BeanUtils.copyProperties(item, attrs);
return attrs;
}).collect(Collectors.toList());
List<SkuESModel> skuESModelList = skuInfoEntities.stream().map((item) -> {
SkuESModel skuESModel = new SkuESModel();
// 属性对拷
BeanUtils.copyProperties(item, skuESModel);
// skuPrice,skuImg 不能对拷属性,需要自己设置
skuESModel.setSkuImg(item.getSkuDefaultImg());
skuESModel.setSkuPrice(item.getPrice());
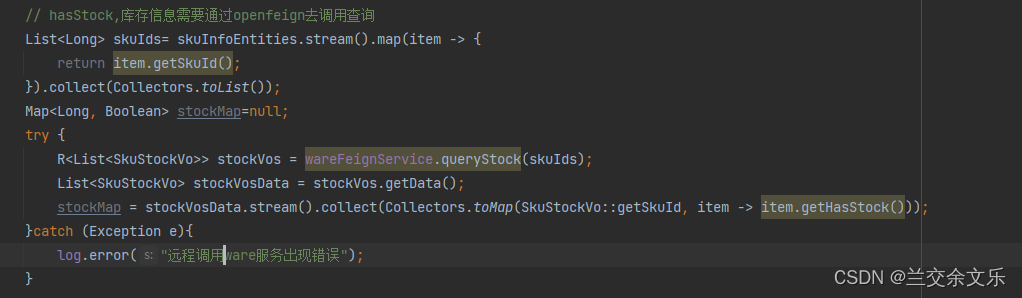
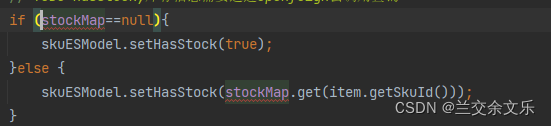
// TODO hasStock,库存信息需要通过openfeign去调用查询
// TODO hotScore涉及复杂的操作,因此,将新上架的商品的热度设置为0
skuESModel.setHotScore(0L);
// 查出brandName,brandImg
BrandEntity brandEntity = brandService.selectBrandEntity(item.getBrandId());
skuESModel.setBrandImg(brandEntity.getLogo());
skuESModel.setBrandName(brandEntity.getName());
// 查出 catelogName
CategoryEntity categoryEntity = categoryService.getById(item.getCatalogId());
skuESModel.setCatelogName(categoryEntity.getName());
// 每个sku的规格参数都是一样的,因此,只需要查一遍就行并且需要筛选出可检索的规格参数
skuESModel.setAttrs(attrsList);
return skuESModel;
}).collect(Collectors.toList());
}商城业务-商品上架-远程查询库存和泛型结果封装
①在ware服务中编写查询库存的接口方便其它服务调用
编写Vo
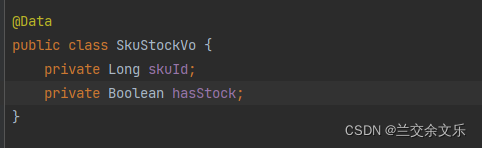
编写接口

分析:首先,一个商品可以存放在多个仓库中,因此,需要累加,但是还需要减去被锁定的商品即未支付的商品数量
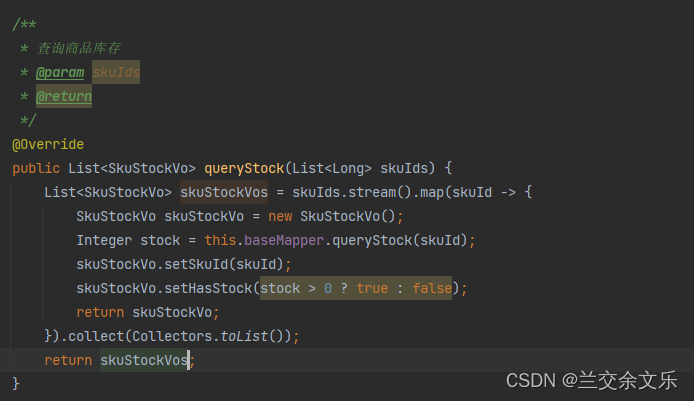

编写feign接口
 出现问题: 这里通过r.get("data")去获取数据将会非常的麻烦
出现问题: 这里通过r.get("data")去获取数据将会非常的麻烦
解决方案:
1.设计R的时候加上泛型
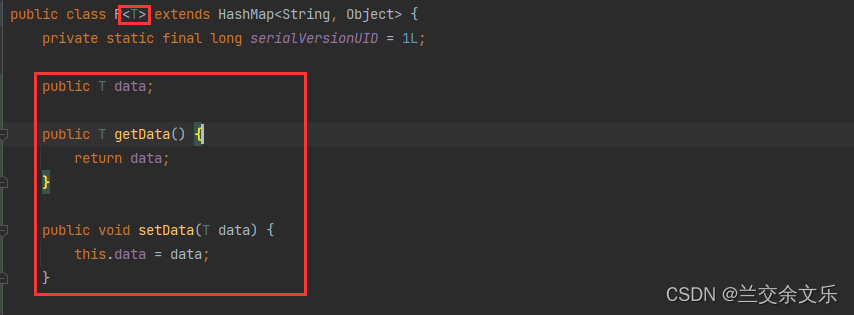
2. 直接返回我们想要的结果
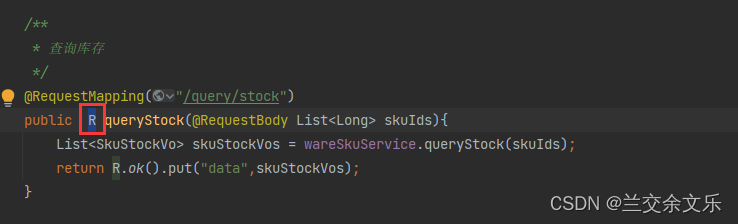
将R改成List<SkuStockVo>
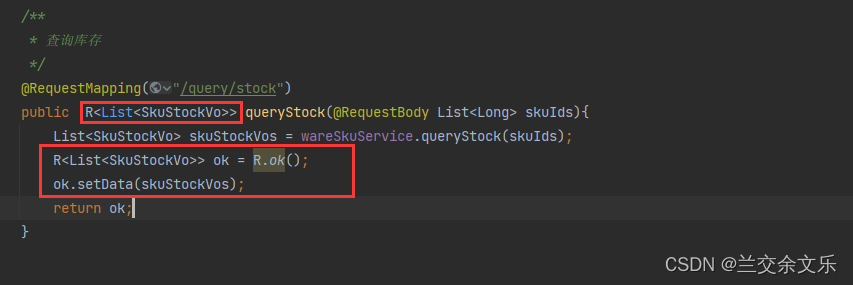
3.自己封装解析的结果
在product和common的vo中复制SkuStockVo
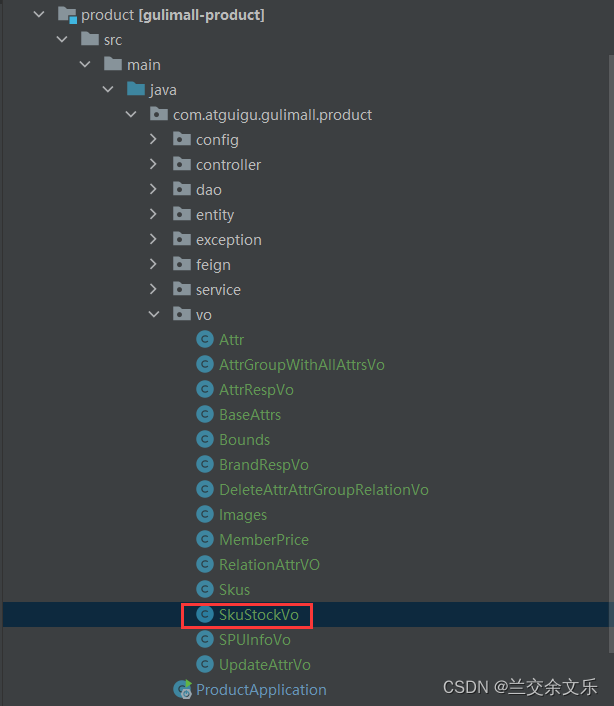
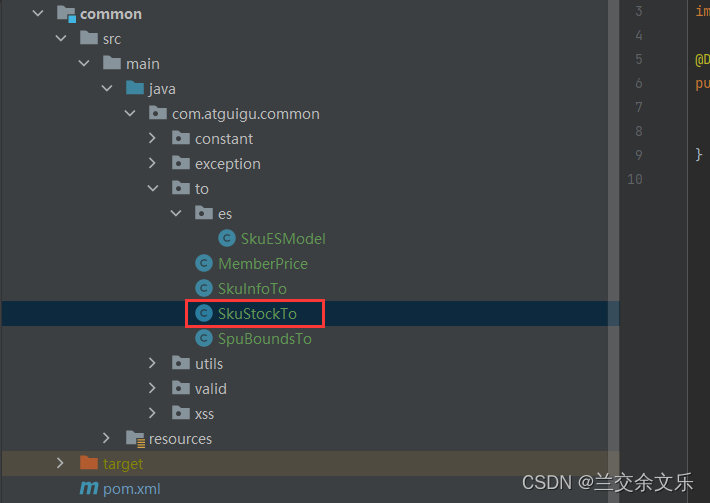

由于是远程服务调用,可能出现网络阻塞的问题导致抛出异常,影响后面的代码执行,因此,需要捕获以下异常
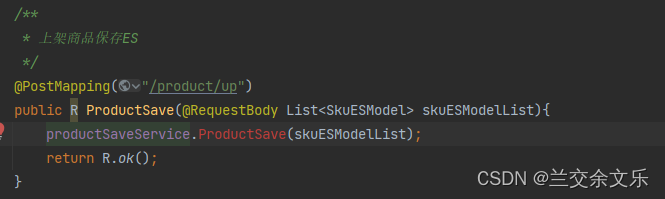
商城业务-商品上架-远程上架接口
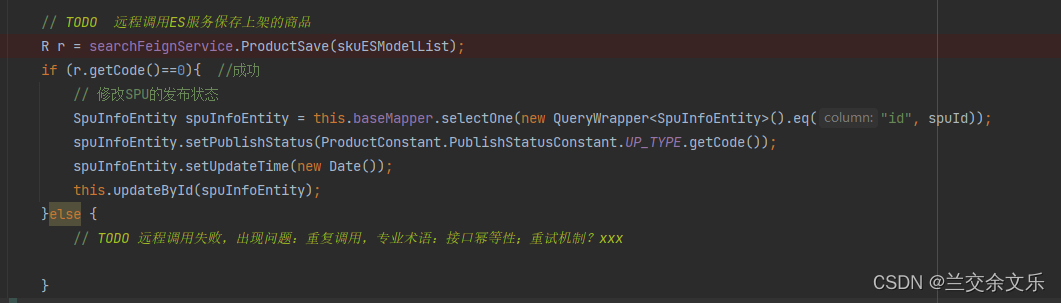
远程调用ES服务保存上架的商品
编写接口
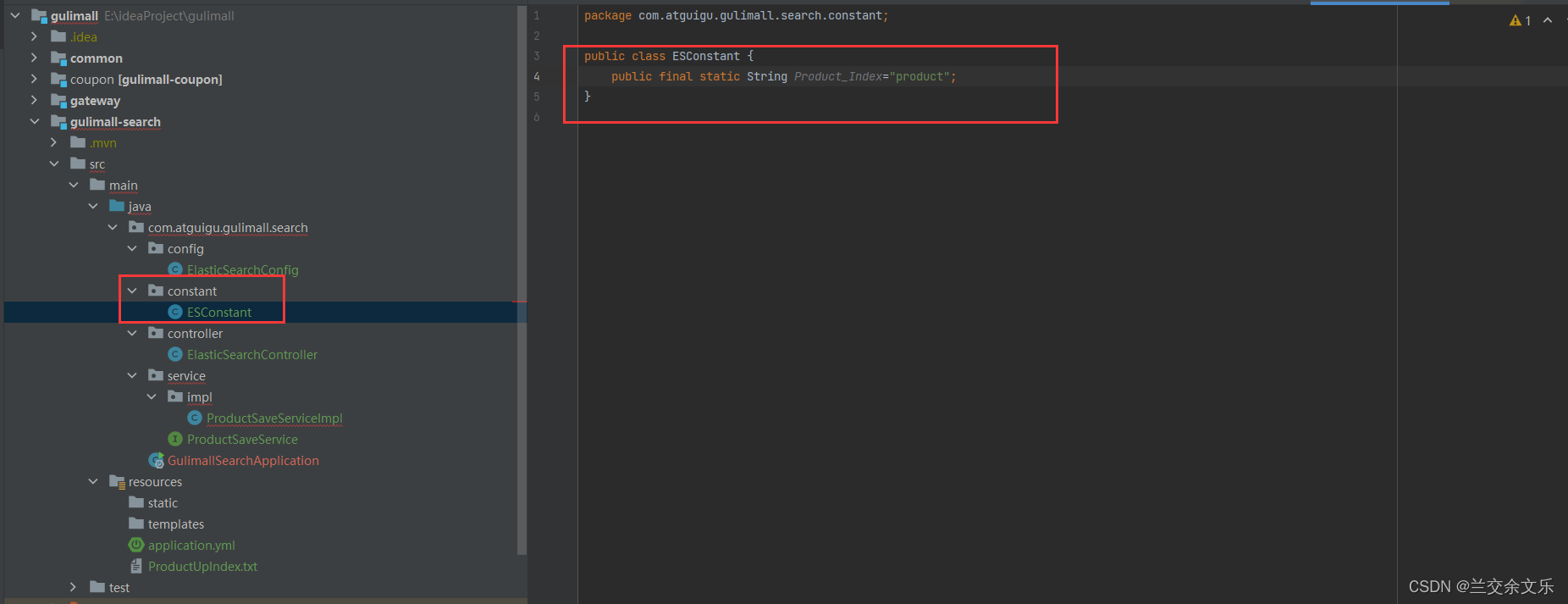
在kibana中创建索引,并将映射关系保存起来
给ES中保存数据
使用bulk批量保存
index中参数即索引是个常量,因此,编写一个常量
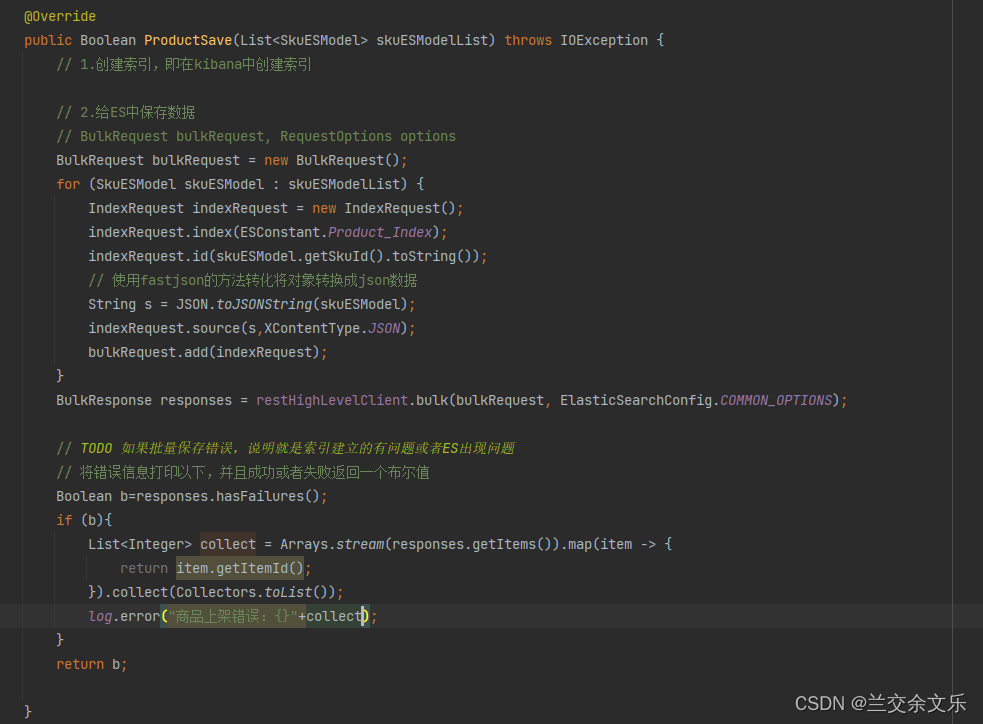
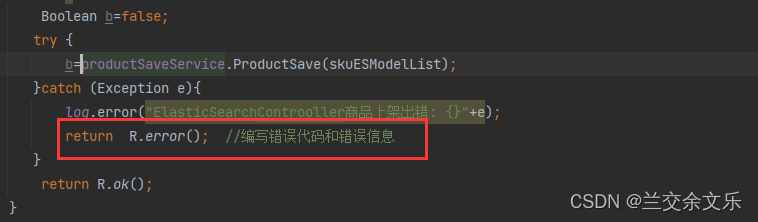
进行一个异常的处理
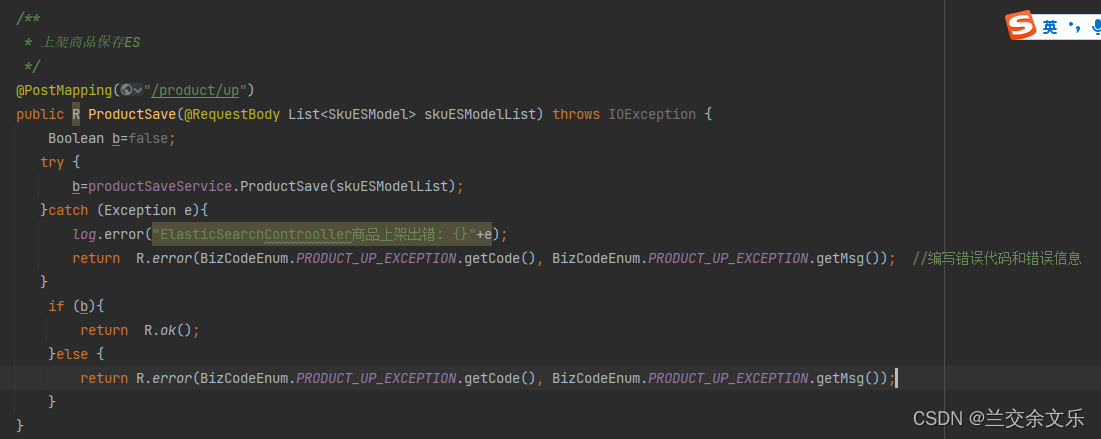
编写feign接口

远程调用ES保存信息


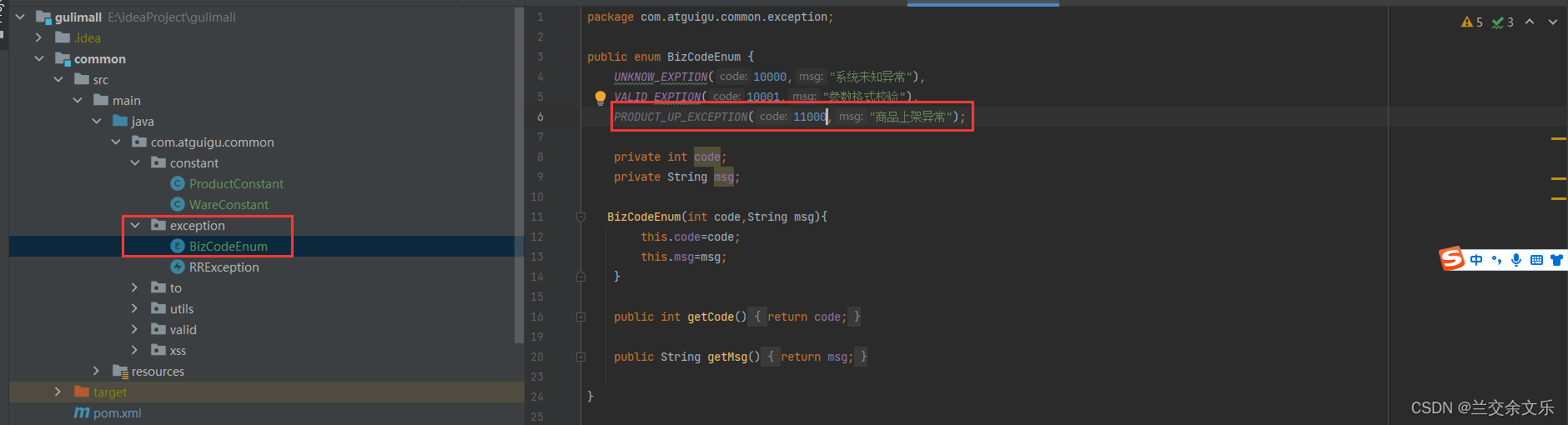
成功之后要将SPU中的发布状态修改,创建枚举类
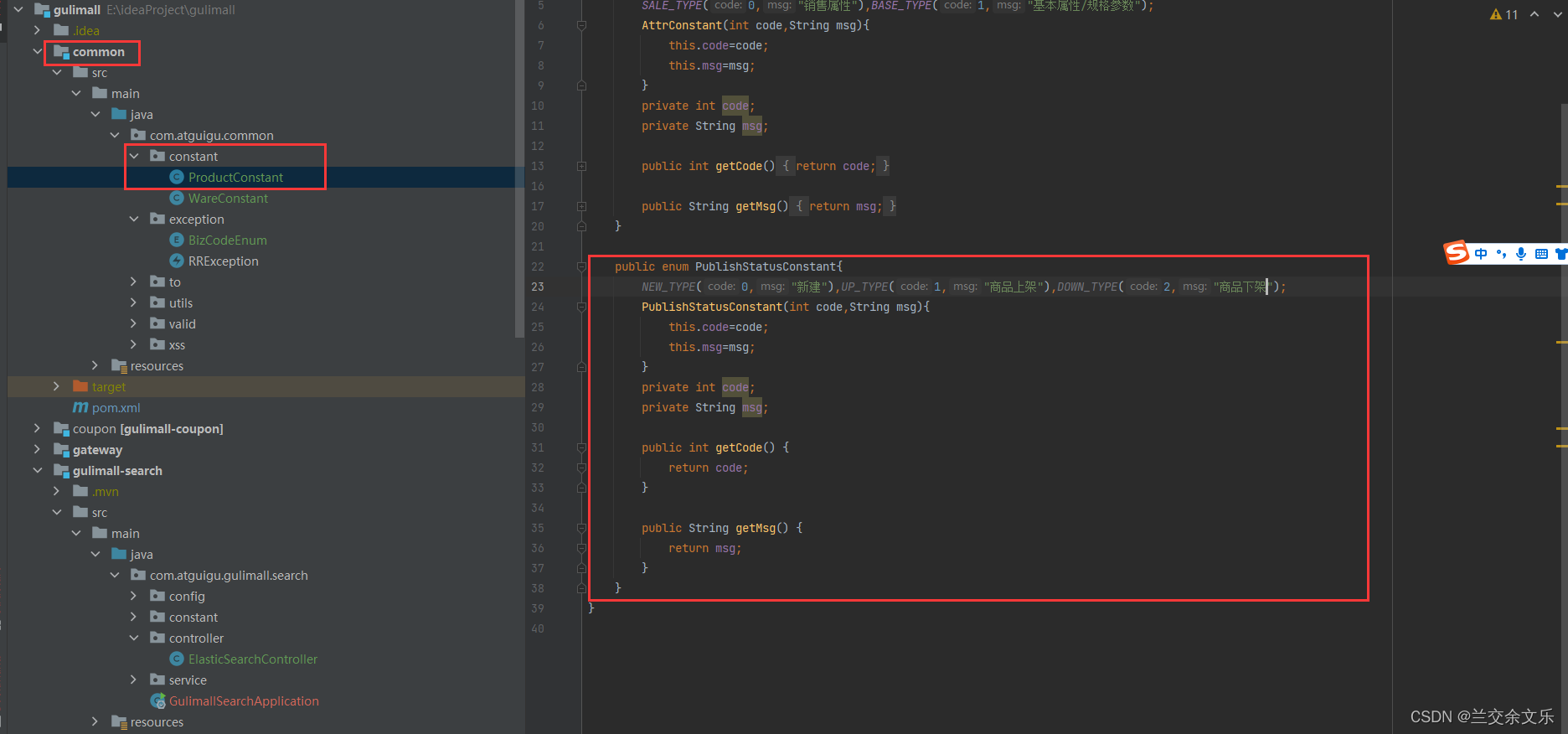

商城业务-商品上架-上架接口调试&feign源码
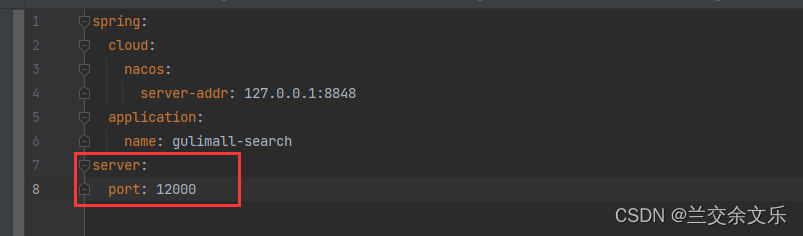
1.配置search的端口号和加入一键启动
 将product、ware、search服务以debug的方式启动
将product、ware、search服务以debug的方式启动
在product中的商品上架方法中打上断点,查询库存方法中打上断点,search服务中上架商品方法中打上断点
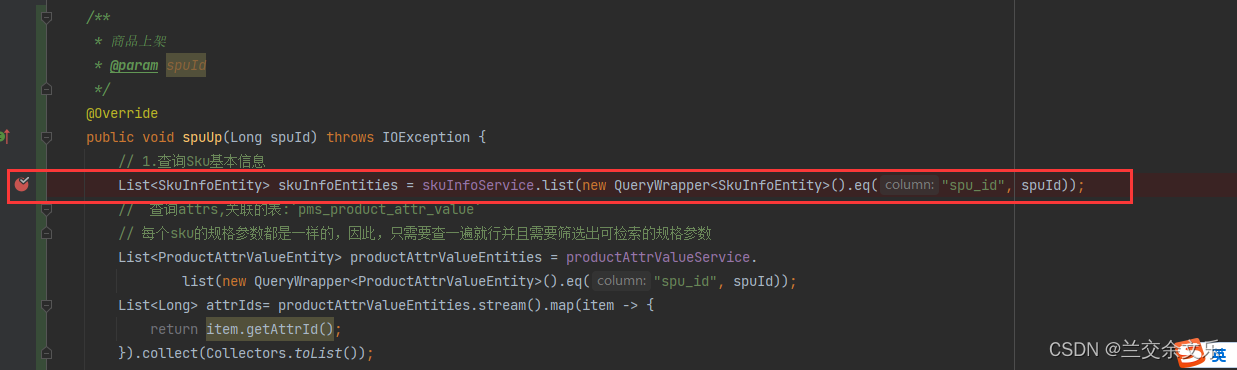
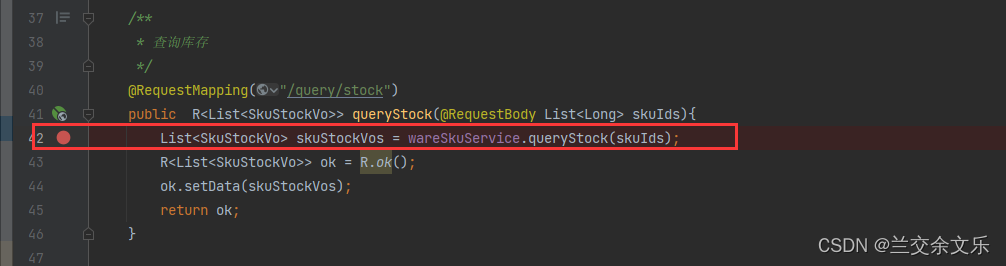
出现问题:属性拷贝未成功
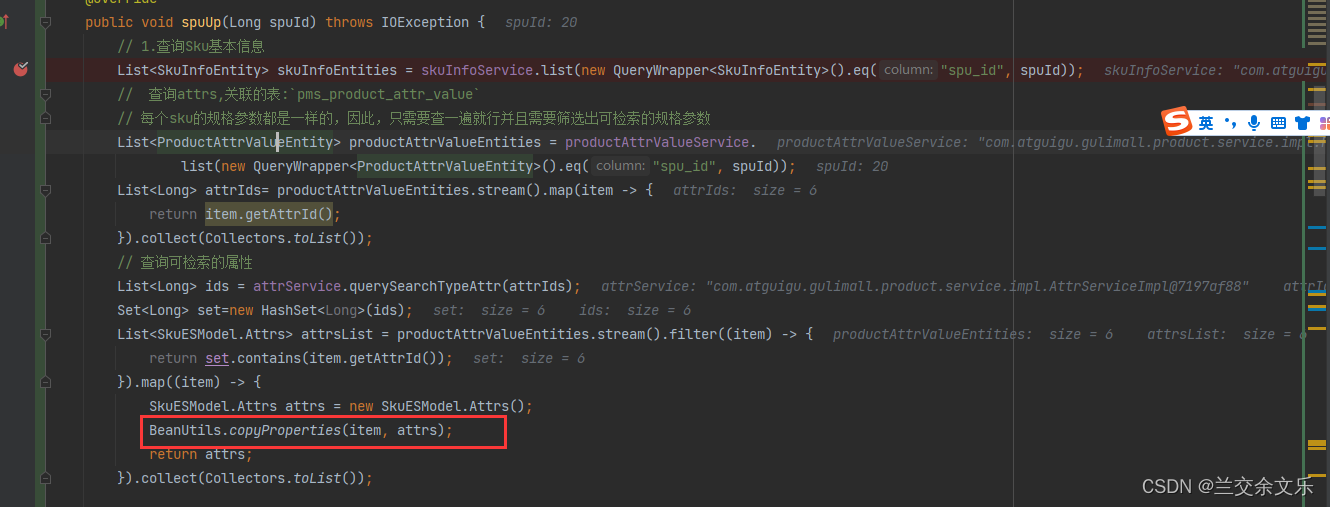
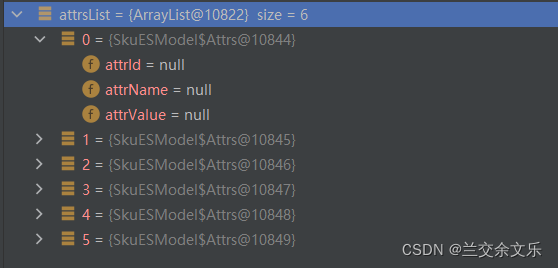
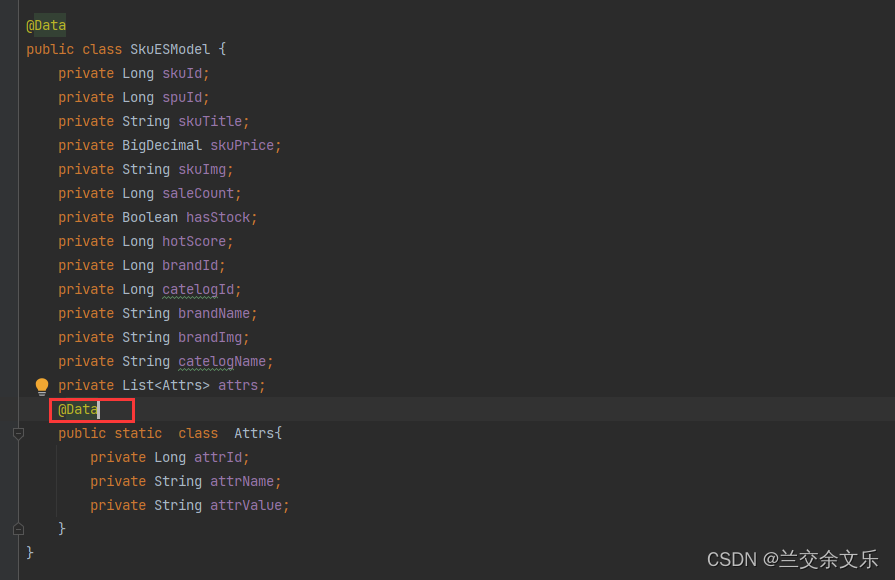
解决方案如下: 加上@Data注解
查询库存出现null指针异常,解决方案如下:
feign执行过程的查看方法就是打断点,点击step into即可查看
feign执行的过程 :
①构造请求数据,将对象转化为json
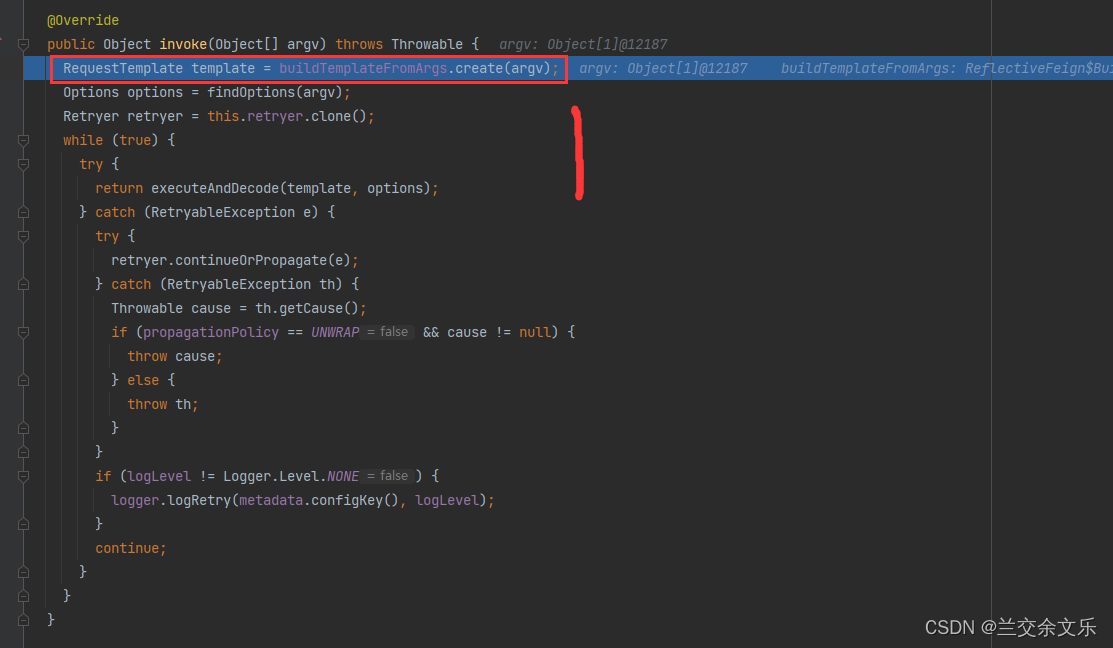
②发送请求进行执行(执行成功会解码响应数据)
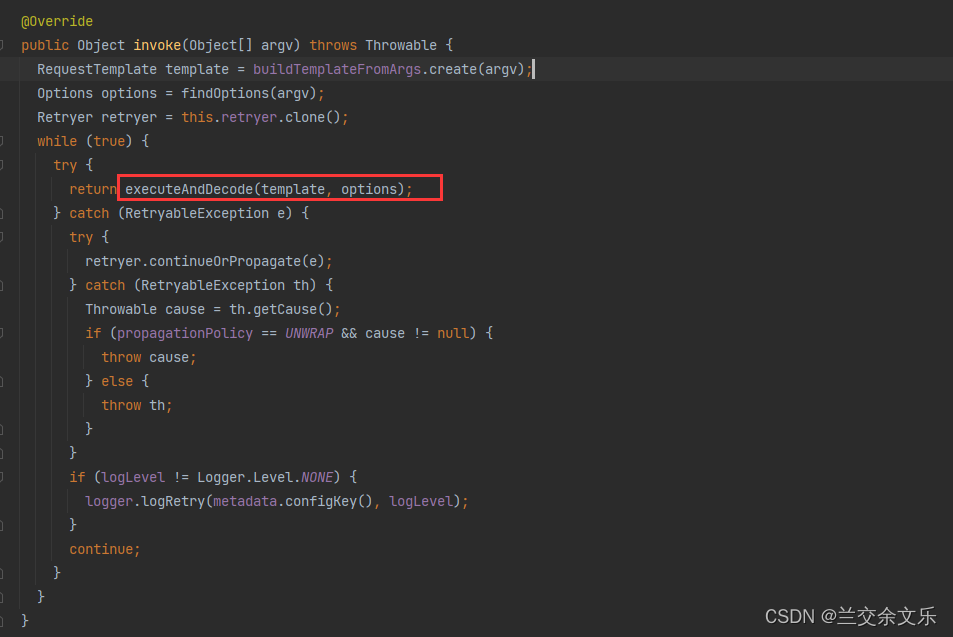
③ 请求执行会有重试机制(默认不开启)
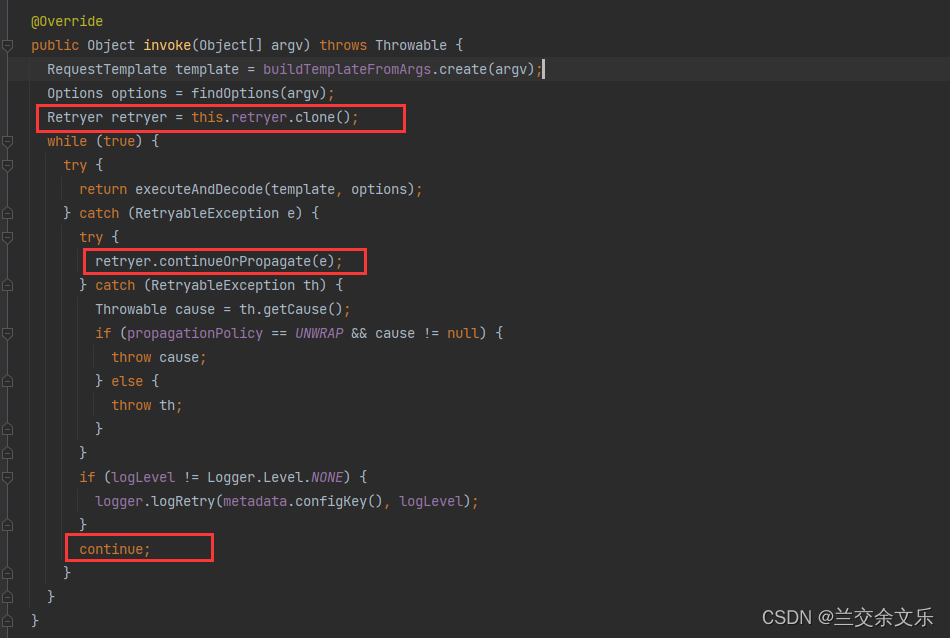
while(true){
try{
executeAndDecode(template, options);
}catch(Exception e){
try{retryer.continueOrPropagate(e);}catch(){throw ex;}
continue;
}
}默认最多重试5次
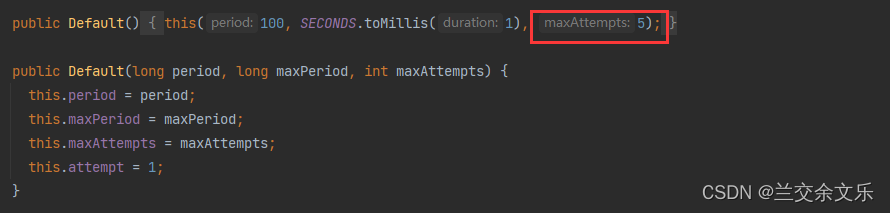
NEVER_RETRY从不重试,直接抛出异常

查看上架商品的结果:

总结一下上架商品的逻辑:
前提条件:凡是上架了的商品都是可检索的商品,因此,需要在ES中构造product index
后台逻辑:根据spuId查询所有skuInfo,将skuInfo中可以对拷的属性拷贝到skuESModel中,不能对拷的属性进行一个设置,像库存信息就需要调用ware服务,规格参数每个sku都一样,因此,可以将属性的设置提取出来,属性需要查询可检索的属性,查询的逻辑为挑选出可检索的attrId,作为HashSet的构造参数,遍历sku关联attr实体将HashSet含有的id进行一个规格参数得对拷。最后,将model批量保存到ES中。
商城业务-商品上架-抽取响应结果&上架测试完成
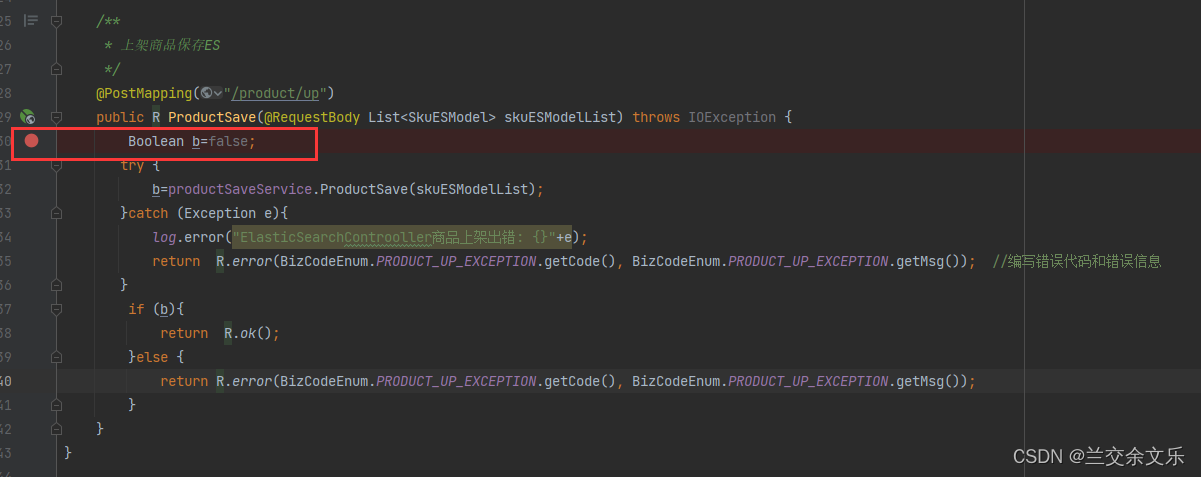
出现问题:上架成功之后,上架状态未修改

出现问题的原因:有错误返回true,这里无错误返回false
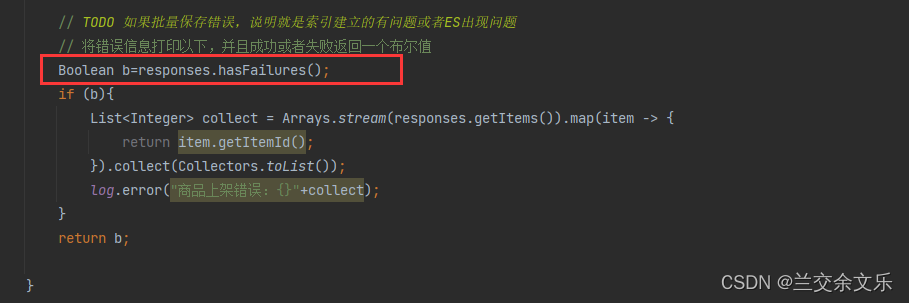
解决方案如下:
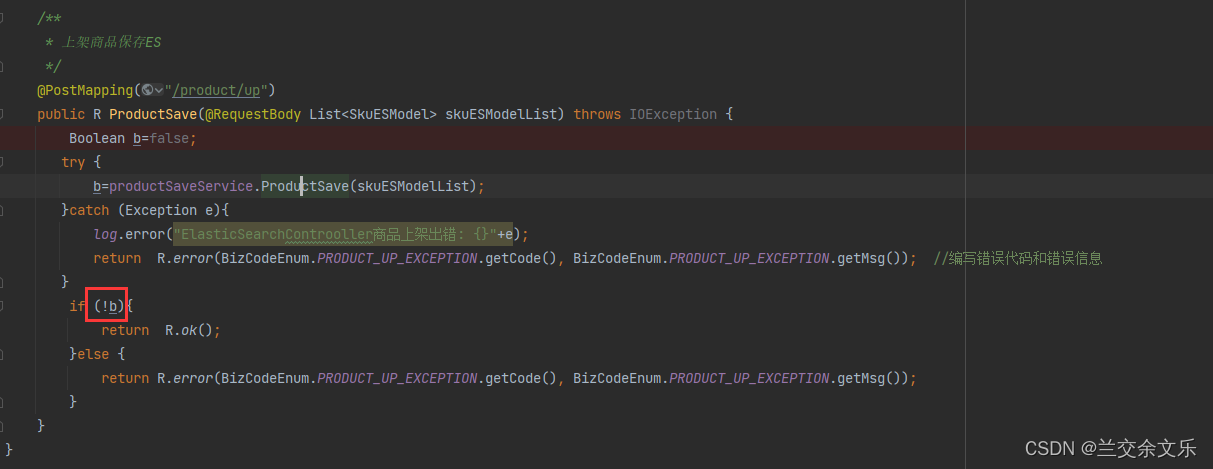
出现问题:未将库存信息封装进R中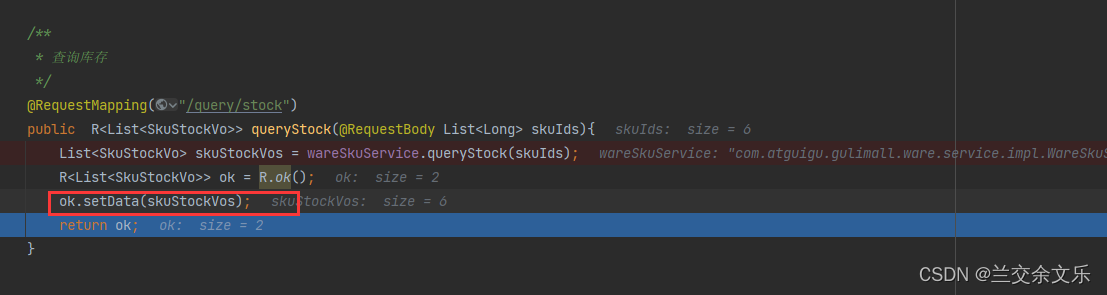
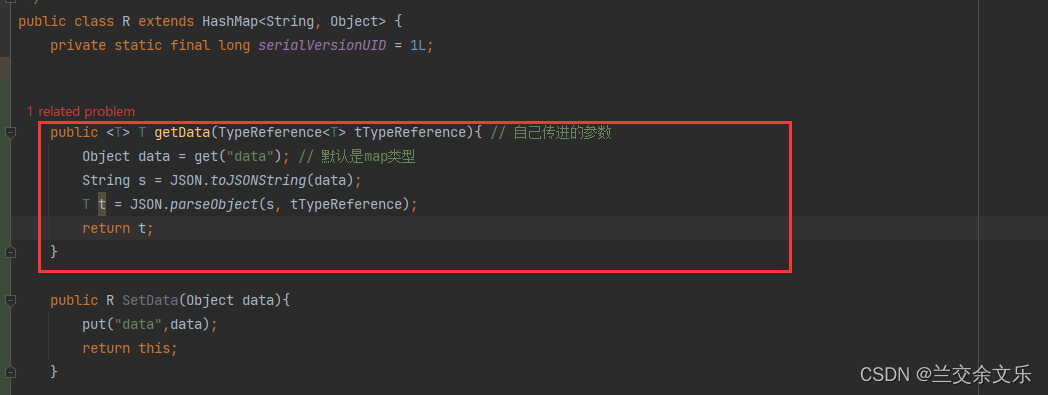
出现问题的原因:R是个HashMap这个封装不行,必须采用key-value形式
R的重新封装,获取自己想要的数据类型
解决方案如下:
删除以下内容
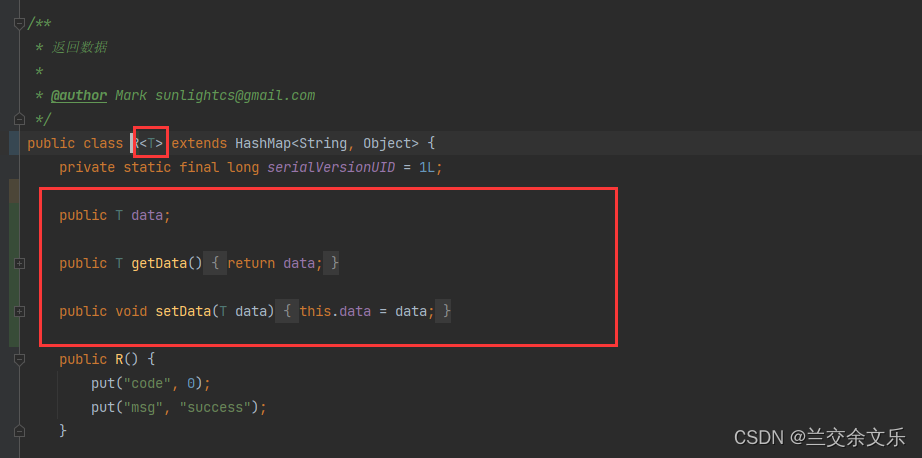
编写封装数据的方法
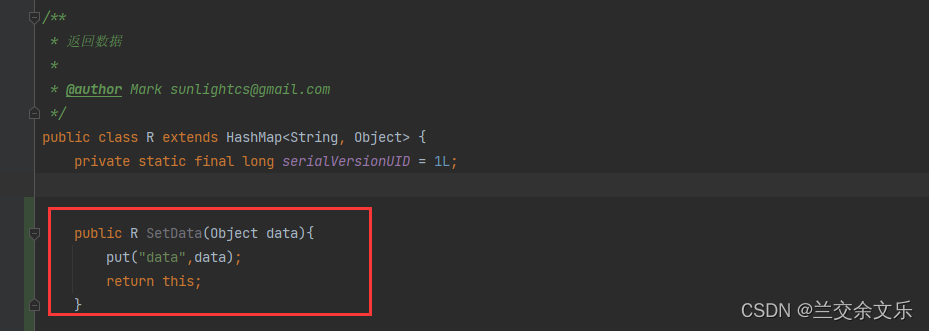
编写获取自己想要数据的方法
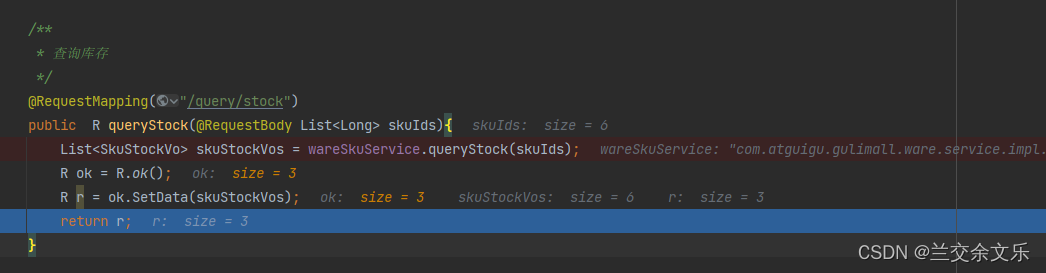
修改调用远程服务的方法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









