



Pandas是Python数据分析的核心库,提供高性能、易用的数据结构和数据分析工具。其名称源于“Panel Data”(面板数据)。它构建于NumPy之上,核心优势在于:
a)核心数据结构:提供DataFrame(二维表)和Series(一维列)结构,完美处理表格型或异质型数据。
b)集成数据管理:内置数据清洗、对齐、缺失值处理、合并、重塑等功能,简化数据预处理流程。
c)灵活的数据访问:支持基于标签(loc)或基于整数位置(iloc)的智能索引与切片,高效访问数据子集。
d)强大的分析工具:提供分组聚合(groupby)、透视表(pivot_table)、时间序列分析等高级功能,助力深度数据洞察。
一、Pandas库的简介与安装
Pandas是一个开源的Python第三方库,这个库是Python进行数据分析和数据处理的核心包之一,它提供了大量的数据操作与分析相关功能(例如,数据清洗、转换、聚合、可视化等)。Pandas的核心功能是DataFrame和Series这两种数据结构,它们支持灵活的数据索引、对齐以及处理缺失数据的能力,能够高效地存储和操作带标签的、关系型的表格数据,是数据科学和数据分析任务中不可或缺的工具。
同样Pandas的使用需要安装,以下是使用pip安装Pandas库的安装命令代码:
#pip方式安装Pandas库
#默认安装最新版本
pip install pandas
#安装指定的版本
pip install pandas==1.3.0
二、Pandas库的核心功能与数据结构
(1)Series(序列)
Series是一个一维的、带标签的数组对象,这是一种类似于一维数组结构的数据类型,由一组数据(Numpy模块中的一维的ndarray数组对象)和一组相关联的数据标签(索引,可以是数值、日期时间、字符串等)组成。
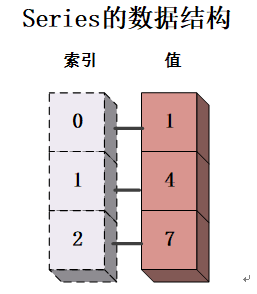
创建Series对象的语法代码如下所示:
# 创建Series数据对象
ser_obj=pd.Series(data=None,index=None,dtype=None,name=None,copy=False,fastpath=False)
在使用pd.Series()函数创建Series对象时,可以通过一系列参数对其进行灵活配置,以满足不同的数据需求。以下是几个常用参数及其功能的详细说明:
- data:该参数用于指定Series所包含的数据内容,可接受的数据类型包括列表、元组、NumPy数组、字典或其它Series对象。若不提供此参数,将默认创建一个空的Series对象。
- index:该参数用于定义Series的索引标签,支持传入列表、数组或Pandas索引对象。索引标签可与数据值一一对应,提供更直观的数据访问方式。若不显式设置,Pandas将自动生成从0开始的整数位置索引。需注意的是,若data为字典类型,则默认会直接使用字典的键(key)作为索引,此时通常无需再指定index参数。
- dtype:用于设置Series对象中的数据类型(例如,int64、float64、bool、datetime64等),如果设置了该参数,会强制将数据类型转化为指定的数据类型。如果不设置,pandas会自动按照数据中第一个非NaN/null值来推断数据类型。
- name:Series对象的名称,用来标识Series对象,如果设置了该参数,则创建的Series对象具有特定名称,可以方便后续对Series对象的操作。
- copy:这是一个布尔型参数,用于控制是否对输入的数据对象进行深度拷贝。默认为False,即进行浅拷贝,创建的Series与原数据对象共享内存,对Series的修改可能会影响原始数据。若设置为True,则进行深度拷贝,创建一个全新的数据副本,对新Series 的任何操作都不会影响原始数据源。
- fastpath:这是一个主要用于库内部实现的优化参数,通常不建议普通用户使用。它用于在某些特定情况下启用快速路径以提升性能。默认值为 False,意味着不启用此优化。用户在日常使用中无需关心此参数。
通过Series()函数来创建不同形式Series对象的具体示例代码如下所示:
# Series对象的创建
import pandas as pd
# 创建一个空Series对象
ser_obj_empty=pd.Series()
print(f"这是一个空Series对象:{ser_obj_empty}")
# 通过列表创建一个Series对象
list_obj=[9,5,1]
ser_obj_list=pd.Series(list_obj)
print(f"使用列表创建一个默认索引的Series对象:\n{ser_obj_list}")
# 通过列表创建一个Series对象并设置其索引
list_obj2=[9,5,1]
ser_obj_list2=pd.Series(list_obj,index=['b','a','c'])
print(f"使用列表创建一个指定索引的Series对象:\n{ser_obj_list2}")
# 通过字典创建一个Series对象
dict_obj= {'a':9,'b':5,'c':1}
ser_obj_dict=pd.Series(dict_obj)
print(f"使用字典创建一个Series对象:\n{ser_obj_dict}")
如果要为Series对象指定索引时,需要确保index参数与data参数中长度保持一致,并且index参数中的值不能重复。
(2)DataFrame(数据框)
DataFrame是一个二维的、大小可变的、potentially heterogeneous(可异质的)表格型数据结构,兼具行索引和列索引。它是Pandas中最常用、最重要的对象,其中的每一行或者每一列都可以看作是一个Series数据。可以理解为一个由多个Series组成的字典,这些Series共享同一个行索引。
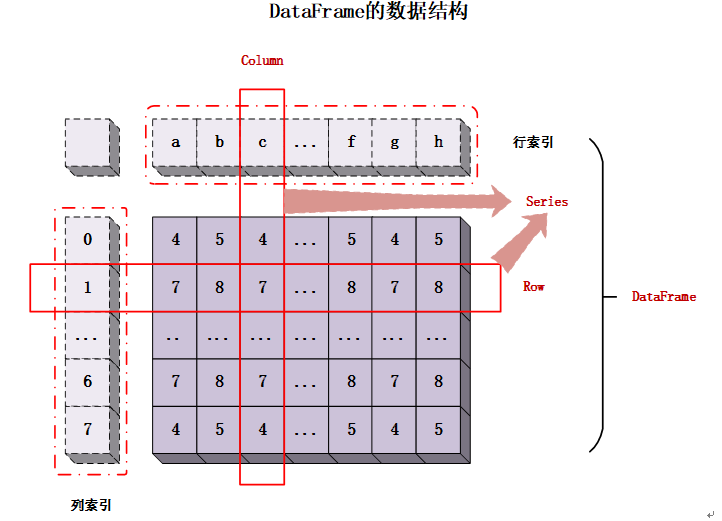
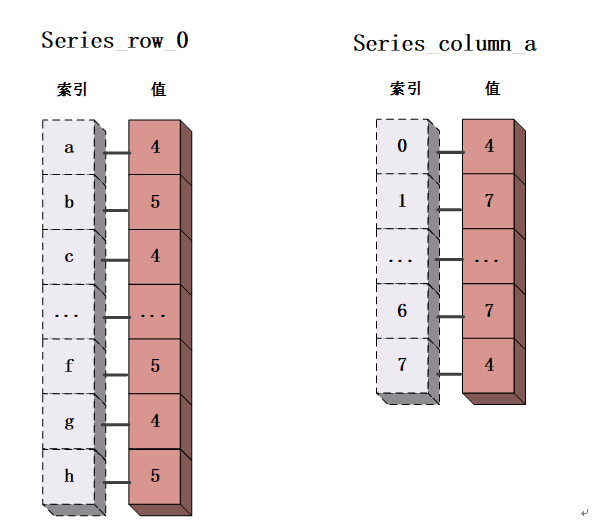
DataFrame对象可以看做由众多Series对象组成的一个二维表,可以通过Pandas模块中的DataFrame()函数进行创建。创建DataFrame对象的语法代码如下所示:
# 创建DataFrame数据对象
df_obj=pd.DataFrame(data=None,index=None,columns=None,dtype=None,name=None,copy=False)
DataFrame()函数中使用的参数与Series()函数中的参数基本一致,只是个别参数的使用有所区别。
- data:DataFrame对象中的数据部分,参数对象的类型可以是字典、二维数组、Series、DataFrame或其他一些可以转化为DataFrame类型的对象。如果不设置参数内容,就会创建一个空的DataFrame对象。
- index:DataFrame对象中行索引,用来进行每行数据的标识。
- columns:DataFrame对象中列索引,用来进行每列数据的标识。
通过DataFrame()函数来创建不同形式DataFrame对象的具体示例代码如下所示:
# DataFrame对象的创建
import pandas as pd
# 创建一个空DataFrame对象
df_obj_empty=pd.DataFrame()
print(f"这是一个空DataFrame对象:{df_obj_empty}")
# 通过二维列表创建一个DataFrame对象,使用默认索引
list_obj=[[9,8,7],[6,5,4],[3,2,1]]
df_obj_list=pd.DataFrame(list_obj)
print(f"使用列表创建一个默认索引的DataFrame对象:\n{df_obj_list}")
# 通过二维列表创建一个DataFrame对象,使用指定索引
list_obj2=[[9,8,7],[6,5,4],[3,2,1]]
df_obj_list2=pd.DataFrame(list_obj,index=['b','a','c'],columns=['f','j','i'])
print(f"使用列表创建一个指定索引的DataFrame对象:\n{df_obj_list2}")
# 通过字典创建一个DataFrame对象
dict_obj= {'row1': {'columns1':9,'columns2':8,'columns3':7},
'row2': {'columns1':6,'columns2':5,'columns3':4},
'row3': {'columns1':3,'columns2':2,'columns3':1}}
df_obj_dict=pd.DataFrame(dict_obj)
print(f"使用字典创建一个Series对象:\n{df_obj_dict}")
三、Pandas库的数据操作与数据处理
1.数据的访问与索引
Pandas模块中的Series与DataFrame对象同样支持索引与切片操作,但由于其索引类型不限于整数类型,这两个对象的索引与切片操作方式与ndarray数组对象存在明显区别。
(1)Series对象的索引与切片
Series对象索引与切片的具体的示例代码如下所示:
# Series对象的索引与切片操作
import pandas as pd
#索引
# 创建一个Series对象
ser_obj=pd.Series([9,7,5,2],index=['a','b','c','d'])
print(f"创建的Series对象为:\n{ser_obj}")
print("显示索引方式")
print(f"获取Series中的第一个元素(索引值方式):{ser_obj['a']}")
print(f"获取Series中的最后一个元素(索引值方式):{ser_obj['d']}")
print(f"获取Series中的第一个元素(loc的索引值方式):{ser_obj.loc['a']}")
print(f"获取Series中的最后一个元素(loc的索引值方式):{ser_obj.loc['d']}")
print("隐式索引方式")
print(f"获取Series中的第一个元素(位置索引方式):{ser_obj.iloc[0]}")
print(f"获取Series中的最后一个元素(位置索引方式):{ser_obj.iloc[-1]}")
print("布尔索引方式")
print(f"获取Series中的元素(布尔索引方式):\n{ser_obj[ser_obj>5]}")
# 切片
print("显示切片")
print(f"获取Series中的一个切片(索引值方式):\n{ser_obj['a':'c']}")
print(f"获取Series中的一个切片(loc的索引值方式):\n{ser_obj.loc['a':'c']}")
print("隐式切片")
print(f"获取Series中的一个切片(位置索引方式):\n{ser_obj.iloc[:2]}")
(2)DataFrame对象的索引与切片
DataFrame对象索引与切片操作具体的示例代码如下所示:
# DataFrame对象的索引与切片操作
import pandas as pd
#索引
# 创建一个DataFrame对象
db_obj=pd.DataFrame([[9,8,7],[6,5,4],[3,2,1]],columns=['a','b','c'])
print(f"创建的DataFrame对象为:\n{db_obj}")
print("显示索引方式")
print(f"获取DataFrame中的第一列元素(索引值方式):\n{db_obj['a']}")#使用列索引
print(f"获取DataFrame中的第一列元素(loc索引值方式):\n{db_obj.loc[:,'a']}")#使用列索引
print(f"获取DataFrame中的第一行元素(索引值方式):\n{db_obj.loc[0]}")#使用行索引
print(f"获取DataFrame中的第一行的第一个元素(loc索引值方式):\n{db_obj.loc[0,'a']}")#标签索引的方式获取一个单一元素
print(f"获取DataFrame中的第一列的第一个元素(loc的索引值方式):{db_obj.loc[0]['a']}")#标签索引的方式获取一个单一元素
print("隐式索引方式")
print(f"获取DataFrame中的第一行元素(位置索引方式):\n{db_obj.iloc[0]}")
print(f"获取DataFrame中的第一列元素(位置索引方式):\n{db_obj.iloc[:,0]}")
print(f"获取DataFrame中的第一行的第一个元素(iloc索引值方式):{db_obj.iloc[0,0]}")#(推荐)
print(f"获取DataFrame中的第一列的第一个元素(iloc索引值方式):{db_obj.iloc[0][0]}")#(不推荐)
print("布尔索引方式")
#进行布尔索引时使用某一列作为判断条件,筛选出符合条件的所有行
print(f"获取DataFrame中第一列大于5的所有行(布尔索引方式):\n{db_obj[db_obj['a']>5]}")#单个判断条件
print(f"获取DataFrame中第一列大于5,第三列小于5的所有行(布尔索引方式):\n{db_obj[(db_obj['a']>5) & (db_obj['c']<5)]}")
# 切片
print("显示切片")
print(f"获取DataFrame中几行的切片(索引值方式):\n{db_obj[0:2]}") #行切片
print(f"获取DataFrame中指定列的切片(索引值方式):\n{db_obj[['a','c']]}")#列切片
print(f"获取DataFrame中的一个行列切片(loc的索引值方式):\n{db_obj.loc[:1,'a':'b']}")#行列切片
print("隐式切片")
print(f"获取DataFrame中的几行切片(位置索引方式):\n{db_obj.iloc[:2]}")#行切片
print(f"获取DataFrame中的几行切片(位置索引方式):\n{db_obj.iloc[:2,0:1]}")#行切片
2.Series与DataFrame对象的合并
(1)Series对象的合并
Series对象是一个一维对象,可以看作行也可看作列,因此在进行组合时可以按照行方向与列方向两种方式进行组合。
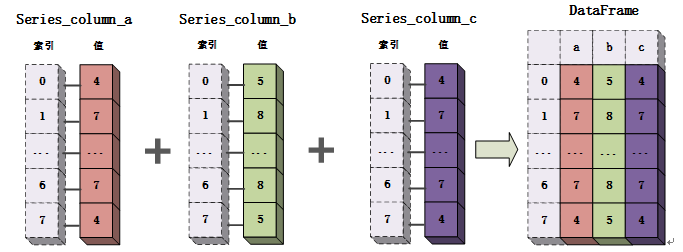
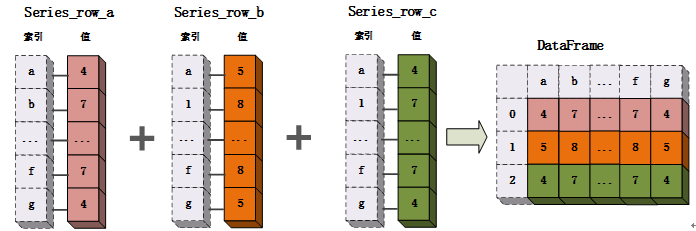
Series对象合并的示例代码如下所示:
import pandas as pd
# 创建两个Series对象
s1 = pd.Series([1, 2, 3, 4], name='A')
s2 = pd.Series([4, 5, 6], name='B')
# 按列合并
# 将Series作为字典的值传递给DataFrame构造函数
df_column = pd.DataFrame({'A':s1,'B':s2})
print(f"这是一个按列合并出的DataFrame:\n{df_column}")
# 按行合并
# 将Series作为列表传递给DataFrame构造函数
df_row = pd.DataFrame([s1,s2])
print(f"这是一个按行合并出的DataFrame:\n{df_row}")
(2)DataFrame对象的合并
同Series对象的组合相比,DataFrame对象的组合就复杂的多。在组合过程中可能会发生合并、连接、追加等操作。
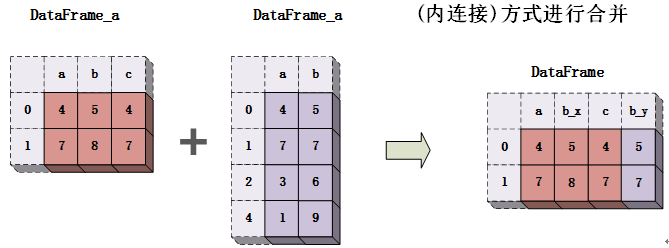
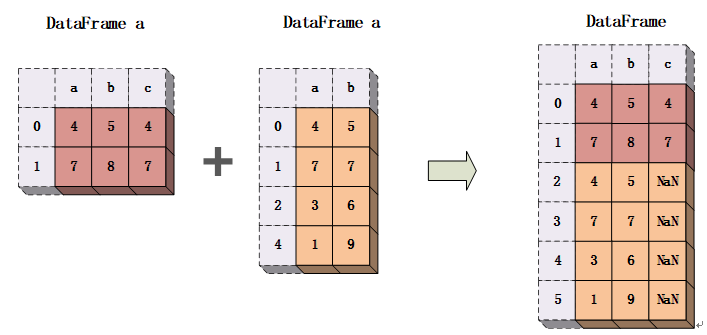
DataFrame对象合并的示例代码如下所示:
import pandas as pd
# 创建两个DataFrame
df1=pd.DataFrame({'A': [4,7],
'B': [5,8],
'C': [4,7]})
df2=pd.DataFrame({'A': [4,1,7,3,1],
'B': [5,1,7,6,9]})
# merge()方法,将两个DataFrame对象进行合并
# 内连接方式合并两个DataFrame对象
result_inner = pd.merge(df1, df2, on='A')#等价于pd.merge(df1, df2, on='key', how='inner')方式
print(f"这是两个DataFrame对象合并后的结果(内连接方式):\n{result_inner}")
# 左连接方式合并两个DataFrame对象
result_left = pd.merge(df1, df2, on='A',how='left')
print(f"这是两个DataFrame对象合并后的结果(左连接方式):\n{result_left}")
# 右连接方式合并两个DataFrame对象
result_right = pd.merge(df1, df2, on='A',how='right')
print(f"这是两个DataFrame对象合并后的结果(右连接方式):\n{result_right}")
# 外连接方式合并两个DataFrame对象
result_outer = pd.merge(df1, df2, on='A',how='outer')
print(f"这是两个DataFrame对象合并后的结果(外连接方式):\n{result_outer}")
# concat ()方法,将两个DataFrame对象进行连接
# 按行进行连接
result_vertical = pd.concat([df1, df2], ignore_index=True)
print(f"这是两个DataFrame对象连接后的结果(按行连接方式):\n{result_vertical}")
# 按列进行连接
result_horizontal = pd.concat([df1, df2], axis=1)
print(f"这是两个DataFrame对象连接后的结果(按行连接方式):\n{result_horizontal}")
3.常用的数据处理方法
Pandas模块是一个十分强大的数据分析库,提供了更为丰富与高效便捷的数据结构,能够方便有效的完成数据清洗。
|
名称 |
说明 |
实例 |
|
read_csv() |
读取csv文件中数据,并以将数据以一个DataFrame对象形式进行返回(csv文件是一种表格文件,只是表格数据是以纯文本形式存放) |
#读取csv文件中的数据 df=pd.read_csv(filename) |
|
read_excel() |
读取excel文件中数据,并以将数据以一个DataFrame对象形式进行返回 |
#读取excel文件中的数据 df=pd.read_excel(filename) |
|
read_sql() |
读取SQL数据库中的数据,并以DataFrame对象格式进行返回(读取数据库中的数据时,先进行数据库的连接,与SQL语句的编写) |
# 从 SQL 数据库中读取数据 import sqlite3 file_name= 'database.db' conn = sqlite3.connect(file_name) sql='SELECT * FROM table_name' df = pd.read_sql(sql, conn) |
|
read_json() |
读取JSON文件中的数据,并以DataFrame对象格式进行返回(不是所有的JSON数据都能转化为DataFrame格式) |
#读取JSON字符串中的数据 df=pd.read_json(json_string) |
|
read_html() |
读取HTML页面中的数据,并以DataFrame对象格式进行返回 |
#读取HTML页面中的数据 df=pd.read_html(url) |
|
head() |
用来获取DataFrame对象中的前几行,可以通过参数n来设置读取的行数 |
# 获取前5行数据 df_5=df.head(5) |
|
tail() |
用来获取DataFrame对象中的前几行,可以通过参数n来设置读取的行数 |
# 获取后5行数据 df_5=df.tail(5) |
|
info() |
显示的是DataFrame对象的详细信息,包括列名、数据类型、缺失值等 |
# 显示详细信息 df.info() |
|
describe() |
显示DataFrame对象中数据的基本统计信息,包括最大值、最小值、均值等 |
# 显示数据的基本统计信息 print(df.describe) |
|
shape |
显示DataFrame对象中的行数与列数,选要注意该方法使用时无需“()” |
# 显示行数与列数 print(df.shape) |
|
dropna() |
删除DataFrame对象中包含缺失值的行或列 |
#删除包含缺失值的行或列 df=dropna() |
|
fillna() |
将DataFrame对象中的缺失值替换为指定的值 |
# 将缺失值替换为指定值 df.fillna(0) |
|
replace() |
将DataFrame对象中的指定值替换为新的值 |
# 替换值 df.replace(old_value, new_value) |
|
duplicated() |
检查DataFrame对象中是否存在重复值,并返回一个布尔型的Series |
# 检查是否存在重复值 ser=df.duplicated() |
|
drop_duplicates() |
删除DataFrame对象中的重复值,仅保留第一次出现的值 |
# 删除重复的值 a=np.array([1,2,3,4]) variance=np.var (a) |
|
sort_values() |
按照指定列的值对DataFrame对象进行排序,默认是升序的即ascending=True,若要降序需要显式声明ascending=False |
# 按照单列列的值排序 df.sort_values('column_name') # 按照多个列的值排序 df.sort_values(['column_name1', 'column_name2'], ascending=[True, False]) |
|
sort_index() |
按照DataFrame对象的行索引进行排序 |
# 按照索引排序 df.sort_index() |
|
groupby() |
按照指定的列进行分组操作 |
# 按照指定列进行分组 df.groupby('column_name') |
|
aggregate() |
对分组后的数据进行聚合操作,(聚合操作中的聚合函数可以是Pandas中的内置函数,如mean、std等,也可以是自定义函数) |
# 先进行分组 df.groupby('column_name') # 对分组后的数据进行聚合操作 df.aggregate('function_name') |
|
pivot_table() |
从原始的DataFrame对象中生成透视图表 |
# 生成透视表 df.pivot_table(values='value', index='index_column', columns='column_name', aggfunc='function_name') |
|
mean() |
计算每列的平均值 |
# 计算每列的平均值 mean = df.mean() |
|
median() |
计算每列的中位数 |
# 计算每列的中位数 median = df.median() |
|
mode() |
统计每列的众数 |
# 计算每列的众数 mode = df.mode() |
|
count() |
统计每列中非缺失值的数量 |
# 统计每列非缺失值的数量 count = df.count() |

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









