







 本文介绍了一种使用空洞卷积进行弱监督和半监督语义分割的方法,通过多率空洞卷积增强感受野,利用分类激活图生成定位图,并结合全卷积网络进行训练。
本文介绍了一种使用空洞卷积进行弱监督和半监督语义分割的方法,通过多率空洞卷积增强感受野,利用分类激活图生成定位图,并结合全卷积网络进行训练。
这是CVPR2018的一篇弱监督、半监督的语义分割的文章
弱监督Weakly-supervised Learning:所给样本只有弱标签,要学习出强标签。在这个分割图像上就是已经需要分割图像的类别,需要将该类在图像中分割出来
半监督Semi-supervised Learning:只有少量样本有标签,需要使用这少量的有标签样本和大量没有标签的样本进行学习。
Multi-dilated Convolution for Localization
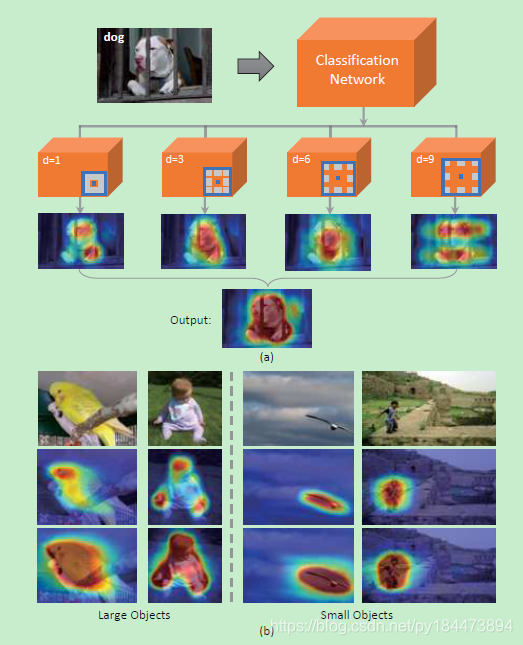
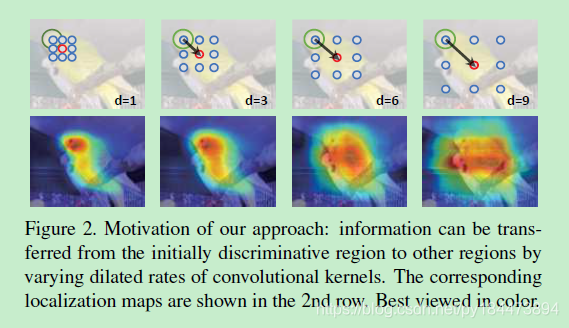
这篇文章使用了空洞卷积,文中提到说,传统的卷积可以精确的映射到要识别的物体身上,但是缺少对于相关物体的映射,但是增大卷积核又会导致运算量增大,所以提出了使用空洞卷积,在不增加计算量的情况下增大感受野,可以映射到相关物体的身上。为了更好的综合各个感受野,本文使用了多个rate的空洞卷积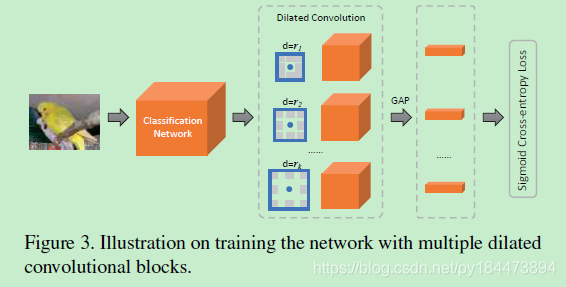
随后对于多个rate(d = 3, 6, 9)的空洞卷积层通过classification activation maps (CAM)得到 corresponding localization maps
虽然使用的rate都比较小,但是还是会有一些不相关的区域被映射上,所以为了平衡这个问题,本文将多个rate得到的corresponding localization maps进行加权平均,得到最终的final corresponding localization maps,就会减少不相关区域

Weakly- and Semi- Segmentation Learning
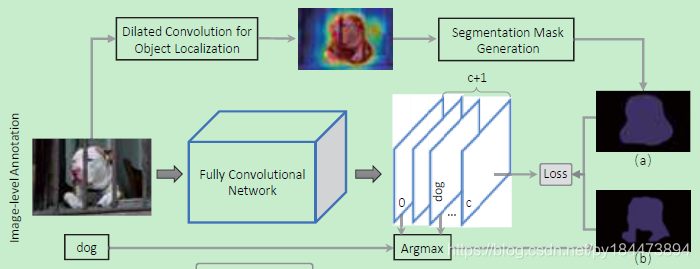
整个网络结构如图所示
loss有两个部分组成,一个是使用final corresponding localization maps生成的分割图(a),一个是使用分割网络FCN得到的最后score map中对应的class score map和背景图的score map进行agrmax得到的分割图(b)
运用(a)(b)组成联合的loss来进行弱监督学习,训练FCN
loss: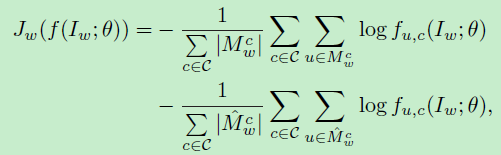
其中I为已知类别的需要分割的分割图,![]() 是经过FCN网络(参数为
是经过FCN网络(参数为![]() )得到的分割结果
)得到的分割结果
![]() 为通过final corresponding localization maps生成的分割图(a)
为通过final corresponding localization maps生成的分割图(a)
![]() 为通过分割网络FCN得到的最后score map中对应的class score map和背景图的score map进行agrmax得到的分割图(b)
为通过分割网络FCN得到的最后score map中对应的class score map和背景图的score map进行agrmax得到的分割图(b)
Semi-supervised Learning
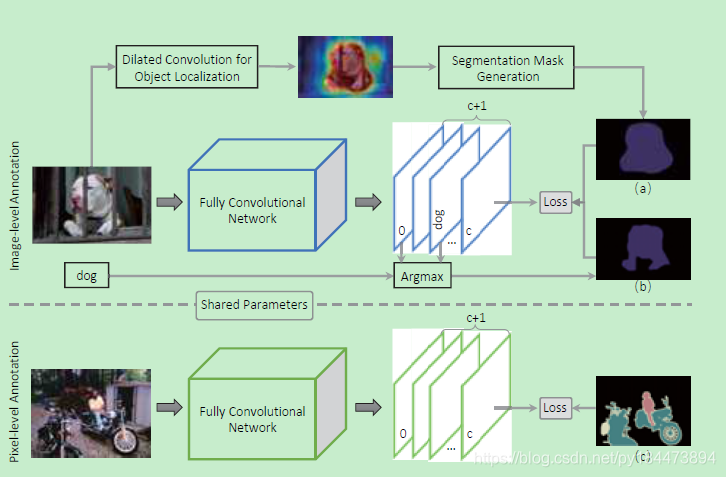
这篇文章采用的半监督学习方式就是将弱监督和少量完整标签的图像的强监督学习进行参数分享来达到弱监督的方式
loss: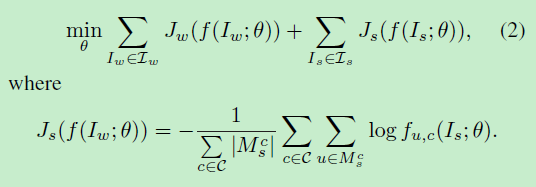
其中![]() 为人标注的像素级分割图
为人标注的像素级分割图

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









