






一,排序函数:
ROW_NUMBER():为每个分区内的行分配一个唯一的行号。
使用场景:分页显示数据,或者在删除重复记录时保留一个实例。
RANK():为每个分区内的行分配一个排名,如果有相同的值,排名会跳过。
使用场景:在成绩表中为学生分配名次。
DENSE_RANK():为每个分区内的行分配一个排名,如果有相同的值,排名不会跳过。
使用场景:当需要连续的排名,且不希望有排名跳跃时使用。
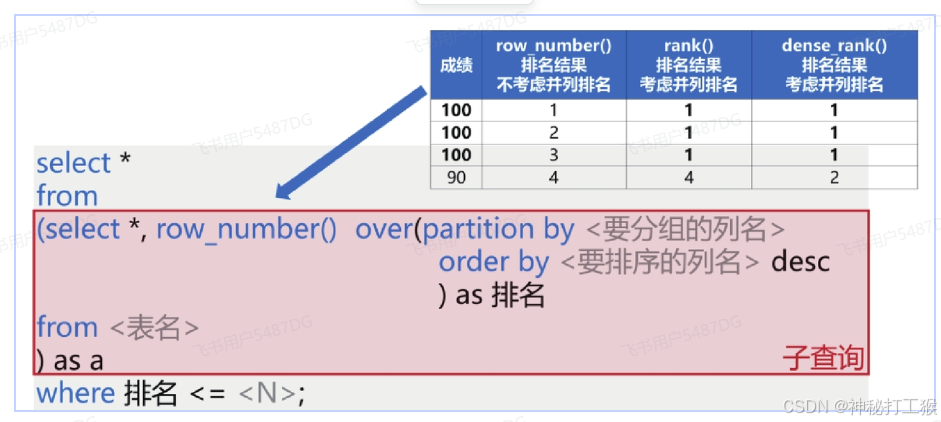
二,聚合函数:
SUM():计算窗口内的总和。
使用场景:计算累积销售额,或者每个月的总销售额。
AVG():计算窗口内的平均值。
使用场景:计算移动平均,如过去三个月的平均销售额。
COUNT():计算窗口内的行数。
使用场景:COUNT() 函数的使用场景非常广泛,统计记录总数,统计非空记录数,分组统计,
与开窗函数结合,检查数据完整性,统计唯一值。
MAX():找出窗口内的最大值。
使用场景:找出一段时间内的最低/最高温度。
MIN():找出窗口内的最小值。
使用场景:找出一段时间内的最低/最高温度。
三,偏移函数:
LAG():获取当前行之前的某一行的值。
使用场景:查看下一条记录的值,如下一个学生的分数。
LEAD():获取当前行之后的某一行的值。
使用场景:查看下一条记录的值,如下一个学生的分数。
FIRST_VALUE():返回窗口内的第一个值。
使用场景:在时间序列数据中,获取时间段的开始/结束值。
LAST_VALUE():返回窗口内的最后一个值。
使用场景:在时间序列数据中,获取时间段的开始/结束值。
四,其他函数:
PERCENT_RANK():返回百分比排名。
CUME_DIST():返回累积分布值。

















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









