






开窗函数(Window Function)是 SQL 中的一种强大功能,它允许在查询结果集的基础上进行分区和排序,然后对每个分区内的数据进行计算,并且计算结果是基于分区内的行的某种顺序,而不是像聚合函数那样将整个数据集压缩为单个结果。开窗函数不会改变查询结果集的行数,这与普通聚合函数不同。
```sql
<窗口函数> OVER
( [PARTITION BY <列名列表>] -- 分组
[ORDER BY <列名列表>] -- 排序
[ROWS BETWEEN <起始位置> -- 开窗
AND <结束位置>] )
```源数据
```sql
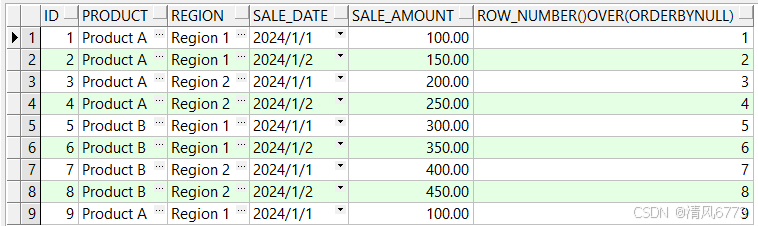
select t.* from sales t
```
开窗函数常见的有以下三大类:
1.排序函数
1. row_number
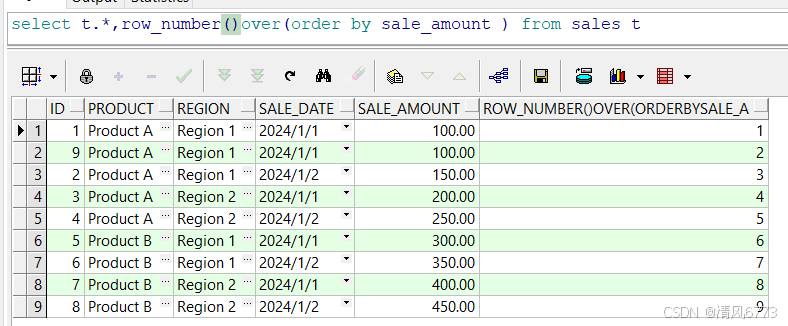
通过查询我们可以发现序号有序的进行排列没有出现相同序号和序号跳跃的情况
由此可见:row_number函数对数据进行排序,如果两个值相同,Oracle数据库会随机返回
一条排在前面
(本人一开始认为时通过rowid 再次进行排序进行数据的返回,多次执行sql验证的顺序不变,但后来想到数据库查询SQL是存在缓存的)
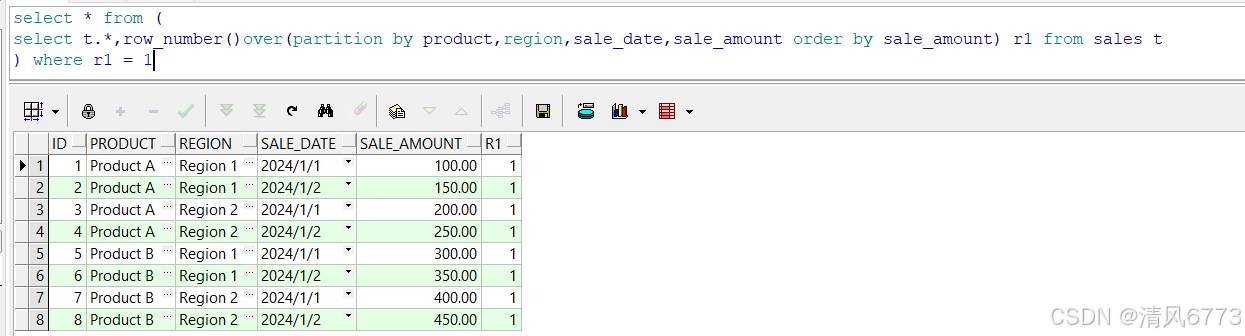
使用场景:
该函数通常用于去除重复数据,两条相同取其中一条的情况
```sql
select * from (
select t.*,row_number()over(partition by product,region,sale_date,sale_amount order by sale_amount) r1 from sales t
) where r1 = 1
```
2. dense_rank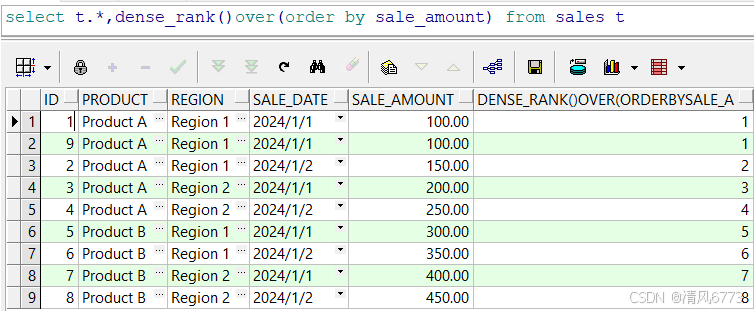
通过查询我们可以发现序号有序的进行排列且出现相同序号和序号跳跃的情况
由此可见:dense_rank函数对数据进行排序,如果两个值相同那么排序,序号会相同,且不会出现序号跳跃的情况
使用场景:
该函数通常用于成绩排名,销售业绩排名,产品销量排名,比赛排名
3. rank
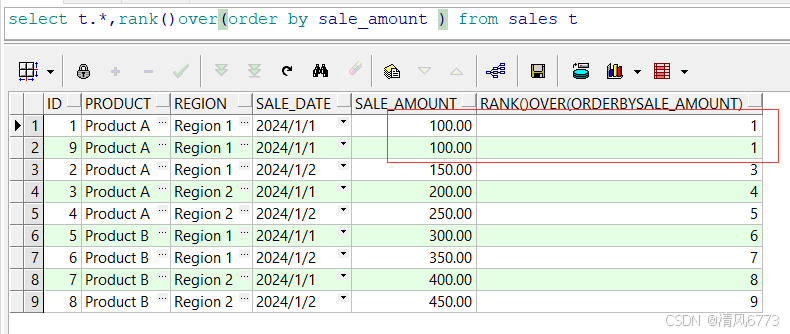
通过查询我们可以发现有两条相同的序号1并且没有序号2
由此可见:rank函数对数据进行排序,如果两个值相同那么排序的值也会时相同的,并且跳过接下来的序号
使用场景:
该函数通常在业务对排名数据有特殊要求时使用
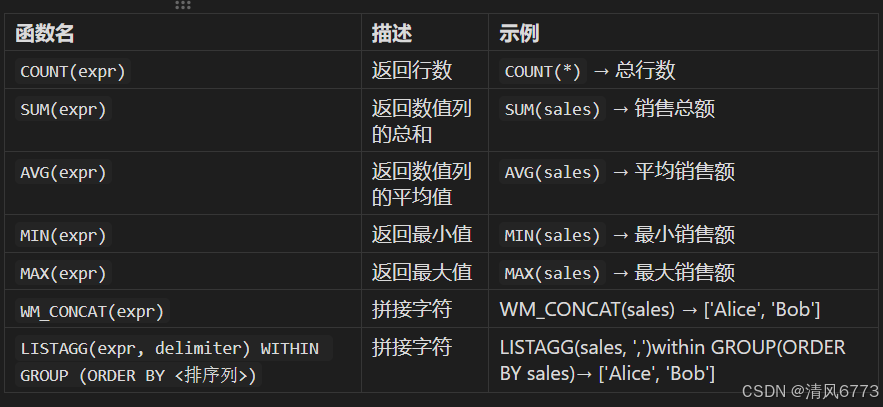
2.聚合函数
传统的聚合函数(如 `SUM`、`AVG`、`COUNT` 等)在使用时会将结果集按照指定的分组条件进行分组,然后对每个分组进行计算,最终将结果集压缩为每个分组的单一聚合值。而开窗函数中的聚合函数则是在不改变结果集行数的基础上,对数据进行分区和排序,然后在每个分区内进行聚合计算,为每一行数据返回一个聚合结果。
以下是一些常见的聚合函数(Oracle)
当我们使用开窗函数汇总是一般都需要携带第三个窗口参数,否则汇总出来的值和你所需要的值存在一定的差异如下图:
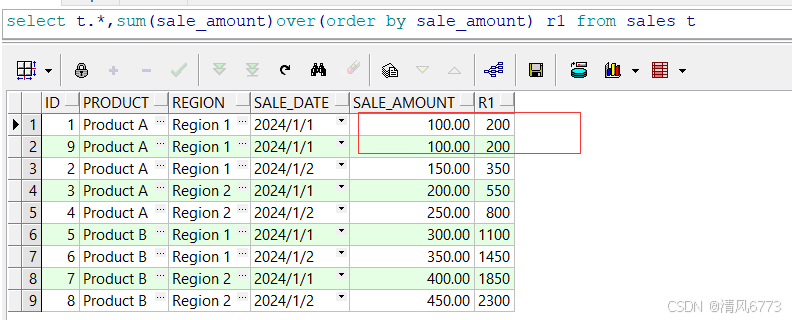 上图发现sale_amount 的值被额外汇总了,把下面那条相同的值也汇总进去了,这时候我们就需要用到开窗函数第三个参数了窗口子句
上图发现sale_amount 的值被额外汇总了,把下面那条相同的值也汇总进去了,这时候我们就需要用到开窗函数第三个参数了窗口子句

- **`ROWS` 和 `RANGE`**:
- **`ROWS`**:基于物理行的位置来定义窗口范围,它根据行号来确定哪些行参与计算。
- **`RANGE`**:基于逻辑值的范围来定义窗口范围,它根据指定列的值来确定参与计算的行。
- **`<起始位置>` 和 `<结束位置>`**:可以是以下几种取值:
- **`UNBOUNDED PRECEDING`**:表示从分区的第一行开始。
- **`N PRECEDING`**:表示当前行之前的第 `N` 行。
- **`CURRENT ROW`**:表示当前行。
- **`N FOLLOWING`**:表示当前行之后的第 `N` 行。
- **`UNBOUNDED FOLLOWING`**:表示到分区的最后一行结束。
```sql
select t.*,sum(sale_amount)over(order by sale_amount ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) r1 from sales t
```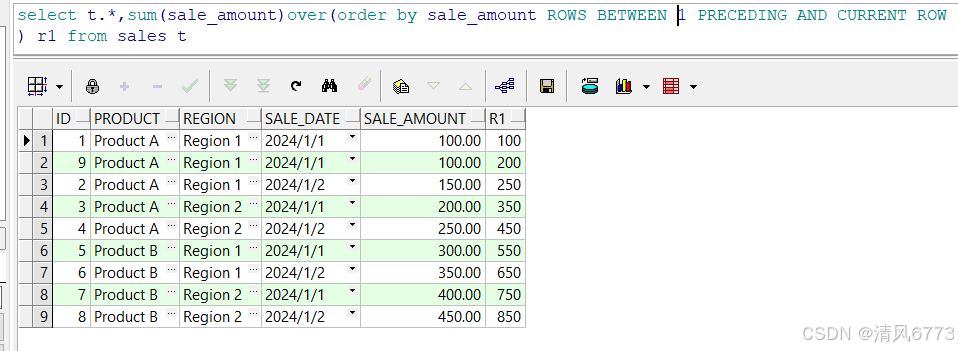
当我们使用窗口子句从第一行汇总到当前行时可以发现相同数据不会跨列进行汇总
注意事项
ORDER BY的影响:窗口子句通常需要和ORDER BY子句配合使用,因为窗口的范围是基于排序后的结果来确定的。ROWS和RANGE的区别:ROWS基于行的物理位置,而RANGE基于列的值。在大多数情况下,ROWS更容易理解和控制,但RANGE在处理逻辑值范围时更有用。- 性能考虑:使用复杂的窗口子句可能会影响查询性能,特别是在处理大量数据时,需要谨慎使用。
- 对数据进行开窗汇总时:要考虑重复值汇总的问题
3.偏移函数
偏移函数是 SQL 中开窗函数的一种,用于在结果集中基于当前行的位置进行偏移操作,从而获取其他行的数据。常见的偏移函数有 `LAG`、`LEAD`、`FIRST_VALUE` 和 `LAST_VALUE` 。下面分别介绍这些函数,
1. LAG 函数
LAG 函数用于从当前行向前(上一行或指定偏移量的行)获取数据。
LAG(<列名>, <偏移量>, <默认值>) OVER (
[PARTITION BY <列名列表>]
ORDER BY <列名列表>
)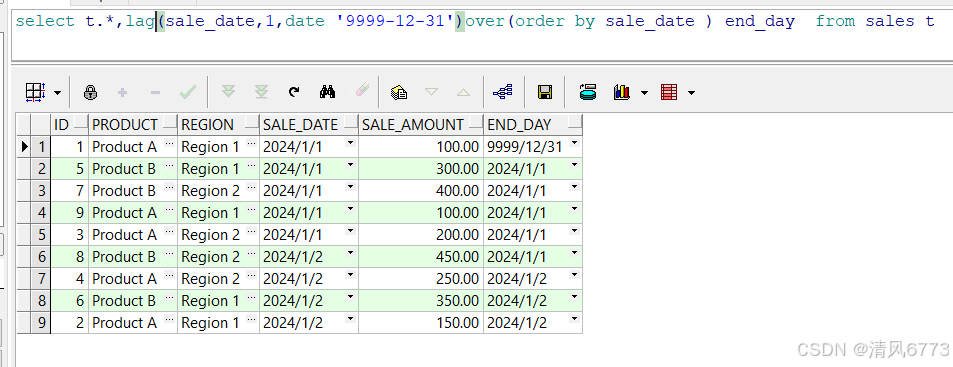
上图可以发现整体数据向上偏移了一行,当偏移不到数据是,取默认值第三个参数
2. LEAD 函数
LEAD 函数用于从当前行向后(下一行或指定偏移量的行)获取数据。
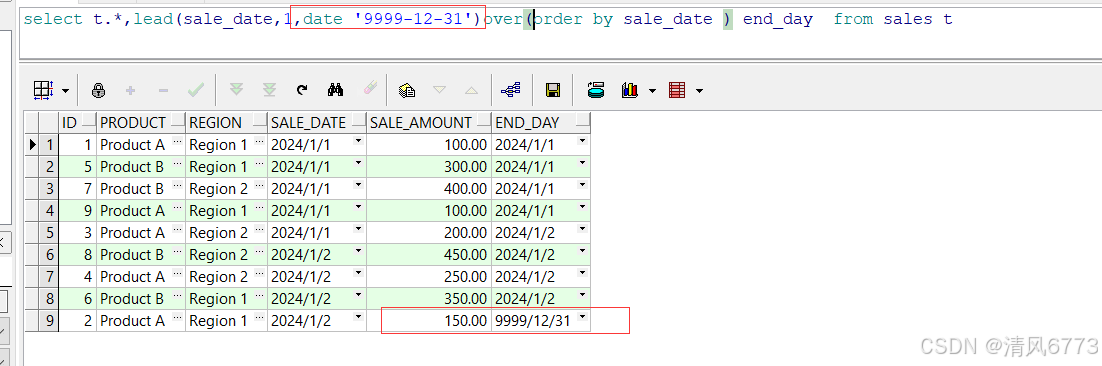
上图可以发现整体数据向下偏移了一行,当偏移不到数据是,取默认值第三个参数
偏移类函数还有FIRST_VALUE,LAST_VALUE等等,熟练的使用偏移函数可以更快的使用某些业务场景,如想要把一个基础模型加工成缓慢变化表供下游系统使用
select t.*,lead(sale_date,1,date '9999-12-31')over(partition by product order by sale_date ) end_day from sales t
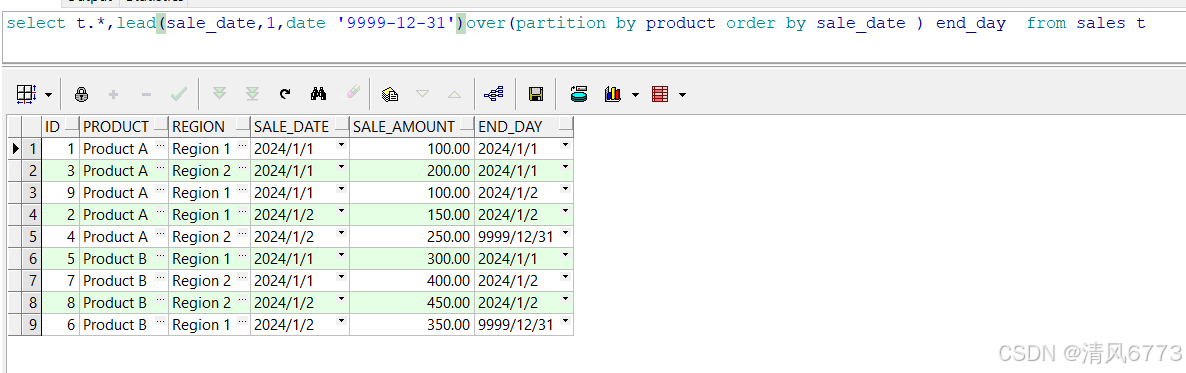
csdn没办法直接导入md文件,今天元宵节和家人吃元宵,某些地方的笔记笔记潦草,写的不好的地方欢迎大佬指正,祝大家元宵节快乐,
每日一名言:打卡第二天
《元宵》【明】唐寅
有灯无月不娱人,有月无灯不算春。
春到人间人似玉,灯烧月下月如银。
满街珠翠游村女,沸地笙歌赛社神。
不展芳尊开口笑,如何消得此良辰。

















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









