







Faster rcnn中的ROI pooliing问题
承接https://blog.youkuaiyun.com/pursuit_zhangyu/article/details/90903970
其实是翻译https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
然后,它为每个不同的目标物体使用两个不同的完全连接层:
- 拥有N+1个单位的完全连接层,整理N是类别的总数,多出来的1表示背景
- 拥有4N个单位的完全连接层。想进行回归预测,所以需要对N个可能的类别进行Δxcenter、Δycenter、Δwidth、Δheight四个值的预测
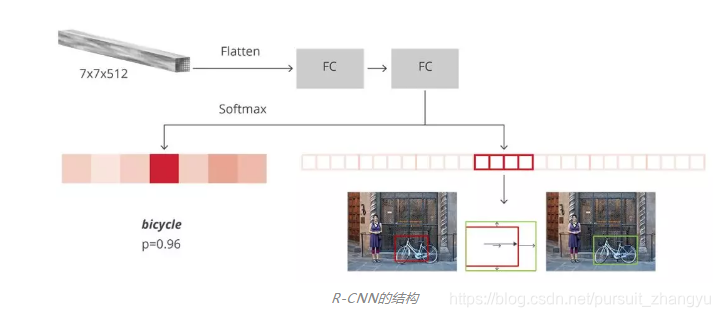
训练和目标
R-CNN的目标与RPN的目标几乎相同,但考虑到不同类别,我们计算了proposals和标准边界框之间的IoU。
那些大于0.5的proposals被认为是正确的边框,而分数在0.1和0.5之间的proposals被标记为“背景”。与我们在为RPN组装目标时所做的相反,我们忽略了没有交集的proposals。这是因为在这个阶段,我们假设这里的proposals很好,而且想要解决更难的案例。当然,所有这些可以调整的超参数可以更好地适合目标物的种类。
边界框回归的目标试计算proposals与其相应的标准框架之间的偏移量,而且这里仅针对那些基于IoU阈值分配了类别的proposals。
我们随机抽样了一个尺寸为64的迷你群组,其中有高达25%的前景proposals,75%的背景。
按照我们对RPNs损失做的那样,对于全部所选出的proposals,分类器的损失现在是一个多类交叉熵损失;对于那25%的前景proposals,用Smooth L1损失。由于为了边框回归的R-CNN完全连接网络的输出对每种类别只有一个预测,所以在获得这种损失时不需小心。在计算损失时,我们只要考虑正确的类别即可。
#-*-coding:utf-8-*-
import math
txtname = 'input.txt'
fopen = open(txtname, 'r')
lines = fopen.readlines()
dt = {}
n = 0
for line in lines:
_, wifimac, _ = line.split(' ')
n += 1
if wifimac not in dt:
dt[wifimac] = 1
else:
dt[wifimac] += 1
m = len(dt)
H = 0
for i in dt:
p = dt[i]/n
H += p*math.log(p, base=2)
print(H)
pytorch单卡多gpu训练
使用方式
使用多卡训练的方式有很多,当然前提是我们的设备中存在两个及以上的GPU:使用命令nvidia-smi查看当前Ubuntu平台的GPU数量(Windows平台类似),其中每个GPU被编上了序号:[0,1]:
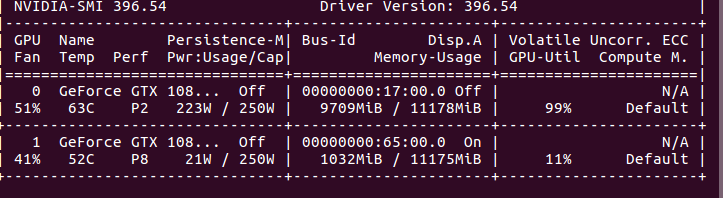
在我们设备中确实存在多卡的条件下,最简单的方法是直接使用torch.nn.DataParallel将你的模型wrap一下即可:
net=torch.nn.DataParallel(model)
这时,默认所有存在的显卡都会被使用。
如果我们机子中有很多显卡(例如我们有八张显卡),但我们只想使用0、1、2号显卡,那么我们可以:
net=torch.nn.DataParallel(model,device_ids=[0,1,2])
或者这样:

阿里天池
https://tianchi.aliyun.com/forum/postDetail?postId=3192
Tensorflow C++ API调用Python预训练模型
https://www.jianshu.com/p/0c415b90404e
https://spockwangs.github.io/blog/2018/01/13/train-using-tensorflow-c-plus-plus-api/
Win10+VS2017+PyTorch(libtorch) C++ 基本应用
https://blog.youkuaiyun.com/gulingfengze/article/details/92013360
linux Pytorch C++ 环境搭建
https://blog.youkuaiyun.com/jacke121/article/details/88709028
CenterNet
https://zhuanlan.zhihu.com/p/66048276
max_value = x if x > y else ypythonn-opencv
https://tianchi.aliyun.com/course/courseDetail?spm=5176.12282076.0..74c22042ItmabG&courseId=40998
牛客网的输入问题
python3
单行输入
nums = int(input())
s, k = list(map(int, input().split()))
list = list(map(int, input().split()))多行输入
num = int(input())
ls = []
for i in range(num):
line = list(map(int, input().split()))
ls.append([int(line[0]), int(line[1])])
print(ls)
python2
input().split(',')目标检测中的不平衡问题的综述
1.目标类别的不平衡
2.类别不平衡:前景和背景的不平衡、前景中不同类别输入包围框的个数不平衡
3.尺度不平衡:输入图像和包围框的尺度不平衡,不同特征层对最终结果贡献不平衡。
4.空间不平衡:不同样本对于回归损失的贡献不平衡,正样本IOU分布不平衡、目标在图像中的位置不平衡
5.目标函数不平衡:不同任务(比如回归和分类)对全局损失的贡献不平衡。
resnet的pytorch代码
# -*-coding:utf-8-*-
import torch.nn as nn
import torch
class Res2d(nn.Module):
def __init__(self, n_in, n_out, stride=1):
super(Res2d, self).__init__()
self.conv1 = nn.Conv2d(n_in, n_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(n_out)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(n_out, n_out, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(n_out)
if stride != 1 or n_out != n_in:
self.shortcut = nn.Sequential(
nn.Conv2d(n_in, n_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(n_out))
else:
self.shortcut = None
def forward(self, x):
residual = x
if self.shortcut is not None:
residual = self.shortcut(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return out
out1 = torch.ones(1, 3, 512, 512)
res = Res2d(n_in=3, n_out=3, stride=1)
res = res.forward(x=out1)
print(res.shape)
如何将矩阵保存为图片
https://blog.youkuaiyun.com/zhuoyuezai/article/details/79635120
yolo v3训练自己的数据集
https://blog.youkuaiyun.com/sinat_27634939/article/details/89884011
深度学习500问
https://github.com/scutan90/DeepLearning-500-questions
python数字图像处理(18):高级形态学处理
https://www.cnblogs.com/denny402/p/5166258.html
pooling 是怎么实现反向传播的?
https://blog.youkuaiyun.com/Jason_yyz/article/details/80003271
Pooling池化操作的反向梯度传播
CNN网络中另外一个不可导的环节就是Pooling池化操作,因为Pooling操作使得feature map的尺寸变化,假如做2×2的池化,假设那么第l+1层的feature map有16个梯度,那么第l层就会有64个梯度,这使得梯度无法对位的进行传播下去。其实解决这个问题的思想也很简单,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同的。
1、mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下 :

mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
2、max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示 :

最新的视觉跟踪SiamMask论文
https://github.com/foolwood/SiamMask
不知道是否可以实现对视频上个的某个人物的脸进行替换,就像漫威的返老还童技术
http://shartoo.github.io/medical_image_process/
以后有时间写一下
pytorch教程,写的真的好
https://blog.youkuaiyun.com/u014380165/article/category/7286599
pytorch的小函数
https://blog.youkuaiyun.com/qq_41044525/article/details/82112783
DenseNet算法详解
https://blog.youkuaiyun.com/u014380165/article/details/75142664
SeNet写的比较好的地址:
https://blog.youkuaiyun.com/xjz18298268521/article/details/79078551
resnext网络
https://www.cnblogs.com/bonelee/p/9031639.html
pytorch实现resnet
https://blog.youkuaiyun.com/weixin_42236288/article/details/82143316
全局平均池化(global-average-pooling)
把特征图全局平均一下输出一个值,也就是把W*H*D的一个张量变成1*1*D的张量
pytorch中的view函数
https://blog.youkuaiyun.com/york1996/article/details/81949843
numpy对某些维度求和
https://blog.youkuaiyun.com/sinat_30372583/article/details/79676330
激活函数
https://blog.youkuaiyun.com/qq_20481015/article/details/85648114
现在最新的网络结构HRNet
https://arxiv.org/abs/1904.04514
明天的任务resnet,incepetion,desnet,senet。
cuda编程
https://zhuanlan.zhihu.com/p/34587739
python中*args和**kwargs的理解
https://blog.youkuaiyun.com/lllxxq141592654/article/details/81288741
计算机视觉面经
https://mp.weixin.qq.com/s/M7He6Ws_HKRHntFFzYFFig
https://zhuanlan.zhihu.com/p/59270912
SSD
https://zhuanlan.zhihu.com/p/33544892
One-stage和two-stage两者有什么特点。
(1)two-stage方法,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高;(2)one-stage方法,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。不同算法的性能如图1所示,可以看到两类方法在准确度和速度上的差异。
ssd里面涉及到了空洞卷积(dilated convolution)
可以去看一下如何理解空洞卷积(dilated convolution)?
default box 的设置
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是  ,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
其中  指的特征图个数,但却是
指的特征图个数,但却是  ,因为第一层(Conv4_3层)是单独设置的,
,因为第一层(Conv4_3层)是单独设置的,  表示先验框大小相对于图片(300*300)的比例,而
表示先验框大小相对于图片(300*300)的比例,而  和
和  表示比例的最小值与最大值,paper里面取0.2和0.9。对于第一个特征图,其先验框的尺度比例一般设置为
表示比例的最小值与最大值,paper里面取0.2和0.9。对于第一个特征图,其先验框的尺度比例一般设置为  。对于后面的特征图,先验框尺度按照上面公式可以知道:
。对于后面的特征图,先验框尺度按照上面公式可以知道:
可以得到各个特征图的尺度为 。对于长宽比,一般选取
 ,对于特定的长宽比,按如下公式计算先验框的宽度与高度(后面的 均指的是先验框实际尺度,而不是尺度比例):
,对于特定的长宽比,按如下公式计算先验框的宽度与高度(后面的 均指的是先验框实际尺度,而不是尺度比例):

默认情况下,每个特征图会有一个  且尺度为 的先验框,除此之外,还会设置一个尺度为
且尺度为 的先验框,除此之外,还会设置一个尺度为  且 的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。注意最后一个特征图中的
且 的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。注意最后一个特征图中的。因此,每个特征图一共有
 个先验框
个先验框  但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为
但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为  的先验框。每个单元的先验框的中心点分布在各个单元的中心,即
的先验框。每个单元的先验框的中心点分布在各个单元的中心,即  ,其中
,其中  为特征图的大小。
为特征图的大小。
是面的是代码里面的设置。
https://github.com/balancap/SSD-Tensorflow/blob/master/nets/ssd_vgg_300.py
default_params = SSDParams(
img_shape=(300, 300),
num_classes=21,
no_annotation_label=21,
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],
anchor_size_bounds=[0.15, 0.90],
# anchor_size_bounds=[0.20, 0.90],
anchor_sizes=[(21., 45.),
(45., 99.),
(99., 153.),
(153., 207.),
(207., 261.),
(261., 315.)],
# anchor_sizes=[(30., 60.),
# (60., 111.),
# (111., 162.),
# (162., 213.),
# (213., 264.),
# (264., 315.)],
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
anchor_steps=[8, 16, 32, 64, 100, 300],
anchor_offset=0.5,
normalizations=[20, -1, -1, -1, -1, -1],
prior_scaling=[0.1, 0.1, 0.2, 0.2]
)
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。在Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本(其实应该是先验框对应的预测box,不过由于是一一对应的就这样称呼了),反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的  大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框 大于阈值,那么先验框只与IOU最大的那个先验框进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大 小于阈值,并且所匹配的先验框却与另外一个ground truth的 大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大 肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了。图8为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框 大于阈值,那么先验框只与IOU最大的那个先验框进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大 小于阈值,并且所匹配的先验框却与另外一个ground truth的 大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大 肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了。图8为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
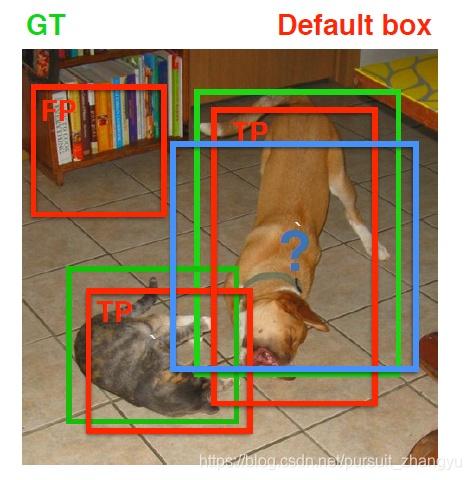
图8 先验框匹配示意图
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(2)损失函数
训练样本确定了,然后就是损失函数了。损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:

其中  是先验框的正样本数量。这里
是先验框的正样本数量。这里  为一个指示参数,当
为一个指示参数,当  时表示第
时表示第  个先验框与第
个先验框与第  个ground truth匹配,并且ground truth的类别为
个ground truth匹配,并且ground truth的类别为  。
。  为类别置信度预测值。
为类别置信度预测值。  为先验框的所对应边界框的位置预测值,而
为先验框的所对应边界框的位置预测值,而  是ground truth的位置参数。对于位置误差,其采用Smooth L1 loss,定义如下:
是ground truth的位置参数。对于位置误差,其采用Smooth L1 loss,定义如下:
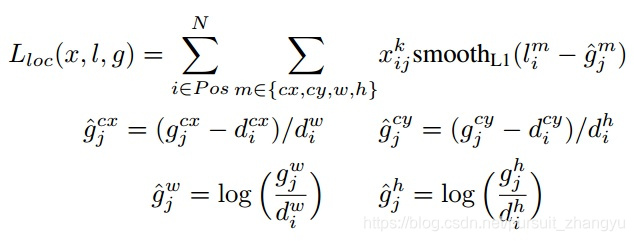
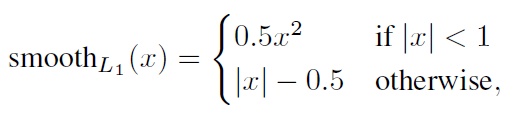
由于  的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的 进行编码得到
的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的 进行编码得到  ,因为预测值 也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
,因为预测值 也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
对于置信度误差,其采用softmax loss:
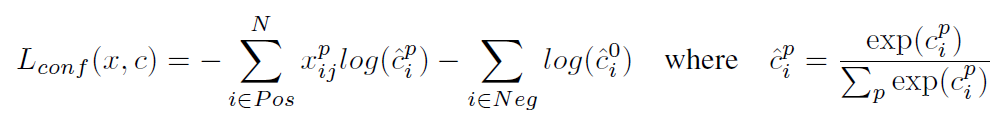
权重系数  通过交叉验证设置为1。
通过交叉验证设置为1。
为什么要使用smooth l1 loss
请问faster rcnn和ssd 中为什么用smooth l1 loss,和l2有什么区别?
为了从两个方面限制梯度:
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。
考察如下几种损失函数,其中  为预测框与 groud truth 之间 elementwise 的差异:
为预测框与 groud truth 之间 elementwise 的差异:


损失函数对 的导数分别为:

观察 (4),当 增大时  损失对 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
损失对 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
根据方程 (5), 对 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
对 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
最后观察 (6),  在 较小时,对 的梯度也会变小,而在 很大时,对 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 完美地避开了 和 损失的缺陷。其函数图像如下:
在 较小时,对 的梯度也会变小,而在 很大时,对 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 完美地避开了 和 损失的缺陷。其函数图像如下:
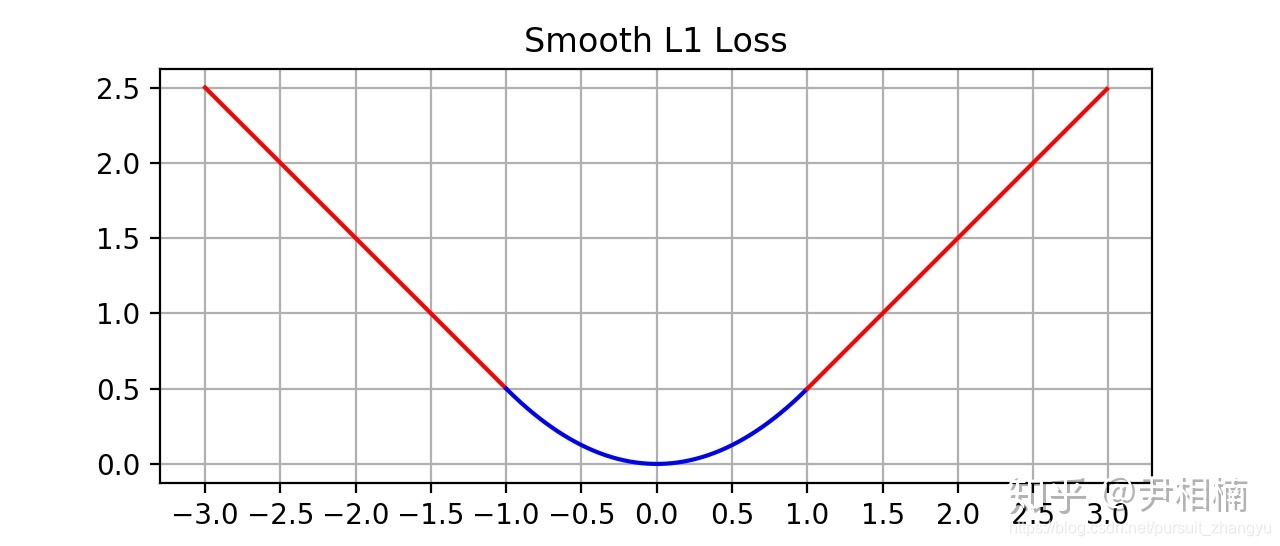
由图中可以看出,它在远离坐标原点处,图像和 loss 很接近,而在坐标原点附近,转折十分平滑,不像 loss 有个尖角,因此叫做 smooth loss。
(3)数据扩增
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如下图所示:


图9 数据扩增方案
其它的训练细节如学习速率的选择详见论文,这里不再赘述。
预测过程
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
性能评估
Soft NMS
BAT机器学习面试1000题系列
https://blog.youkuaiyun.com/sinat_35512245/article/details/78796328
激活函数,BN,loss函数,这个可以做一下记录啊
还有LUNA16数据集的处理流程
wps公式设置
https://jingyan.baidu.com/article/f96699bbacddcb894e3c1b8c.html

















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









