




本文将分享在实际案例中,利用亚马逊云科技在re:Invent 2024推出的新一代自研大模型Amazon Nova Lite,构建视频分享平台的智能审核方案。
在实际项目中会遇到哪些挑战?选择背后有着怎样的考量?Amazon Nova Lite在视频审核方面又有哪些优势?下文将分别从审核的准确性、处理速度、运营成本等维度深入探讨这个话题。
该项目中对视频审核的关键诉求有如下三个方面。
图片理解能力
待审核的内容为全球用户上传的vlog,不同文化背景下审核的标准会有差异。能否准确识别上传内容,根据不同地域要求调整审核规则,并保证审核透明度是重点考核的因素。
图片处理速度
用户上传的视频时长较长,往往会超过1小时。为保证用户使用体验,项目希望视频上传后能在1~2分钟完成内容审核并成功发布。由于平台视频采用专有格式,不适合直接使用视频理解模型来进行审核。项目采用每10s截帧的方式进行图片审核。这就要求图片的处理速度能达到为每秒6张以上。
运营成本
该项目的视频分享平台面向全球用户,用户量大、分享视频数量多、审核任务重。审核成本低廉是长期运营的必要条件。
亚马逊云科技自研大模型Amazon Nova系列,从Model card分析,其在多模态图片、视频理解方面表现突出,而且在响应延时和价格方面同样较同等级模型具有明显优势,因此本次我们对Amazon Nova模型,尤其是Amazon Nova Lite进行了详细的测试和分析。
图片理解能力考察
首先,模型的图像理解能力是视频审核方案选型时的核心要素。基于Amazon Nova系列模型的技术报告和模型卡片,Amazon Nova Lite与Amazon Nova Pro在图片理解上都具有优异的表现。以下是Nova和Gemini在VATEX和EgoSchema上的对比表格:
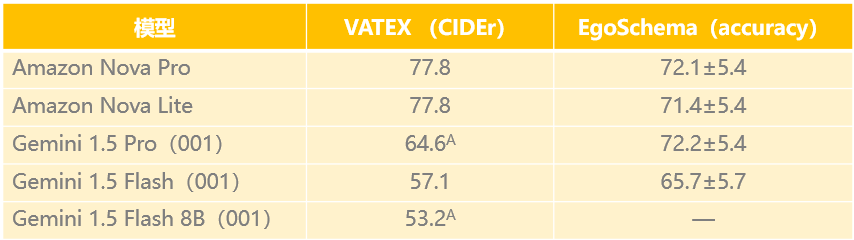
注:ᴬ表示4-shot评估(是指Genmini1.5在进行模型评估时使用了4个examples或prompts的测试方式)。
参考链接:
https://assets.amazon.science/b0/2b/e74dd4f84f188701fd06792670e7/the-amazon-nova-family-of-models-technical-report-and-model-card.pdf
VATEX:是一个视频描述基准测试,涵盖了多样化的人类活动。是在包含约10秒长度视频的公开测试集上进行评估。评估使用CIDEr分数作为指标。
EgoSchema:是基于长视频进行的问答基准测试,该测试的特点是要基于较长时间的观看(即ertificate length)才能给出答案。这些视频涵盖了广泛的自然人类活动,并配有人工策划的多项选择题问答对。
从表格可以看出,Amazon Nova系列模型在广泛人类活动的视频理解上都具有更优于Gemini1.5的能力。
图片审核成本考察
Amazon Nova的理解类模型对图片处理依然依据Token的数量收费模式,图片分辨率与预估Token的关系如下:
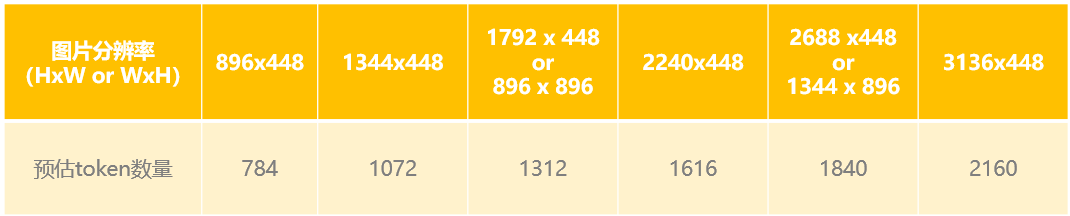
基于以上的数值,我们可以看到图片分辨率与预估的Token数量之间存在线性关系。具体的数值关系可用以下线性回归公式表示:
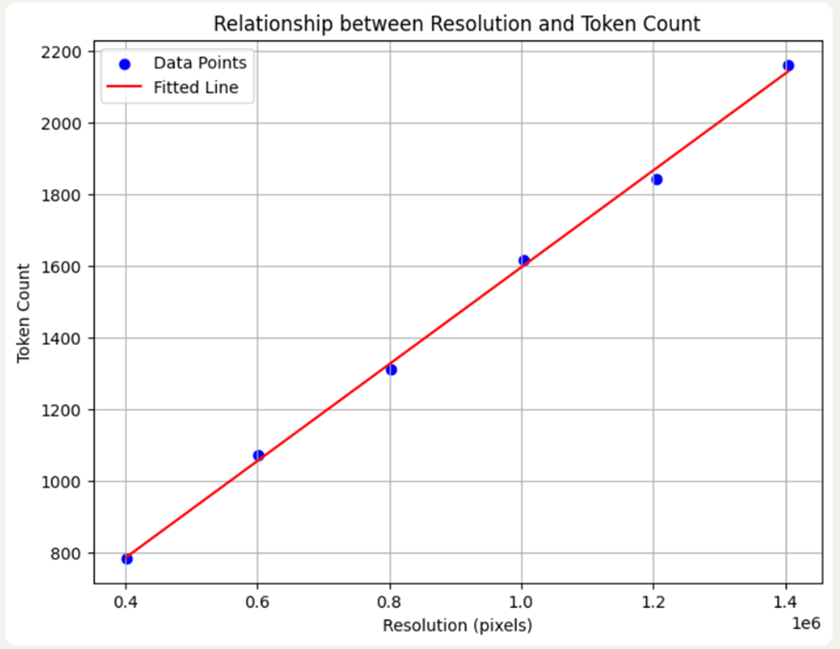
即:Token Count=0.001351×Resolution pixels+244.11。
基于2024年12月发布的Amazon Nova系列模型的价格,我们对不同分辨率的图片分别计算了处理100万张图片时所需的成本。同时与亚马逊云科技的Rekognition在处理相同数量的图片时的价格做了对比:
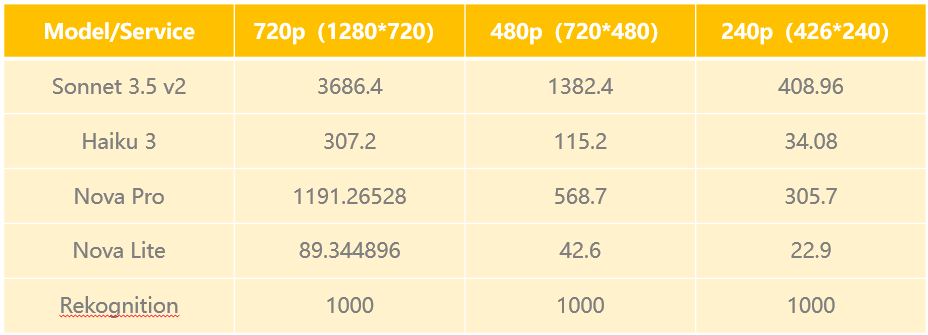
以Amazon Nova Lite处理分辨率为426*240的图片为例,计算方式如下:
一百万张图片的处理成本=(每张图片Token数目xToken单价)x一百万张=(0.001351426240+244)X(0.06/1000000)*1000000=$22.9。
Rekognition处理一百万张图片价格=$0.001/张*1百万=$1000。
可以看到,Amazon Nova Lite在图片处理成本上具有绝对优势。
图片处理速度考察
在确定了处理能力和价格优势后,我们着重对Claude 3 Haiku,Amazon Nova Lite和Rekognition的处理速度进行了对比。
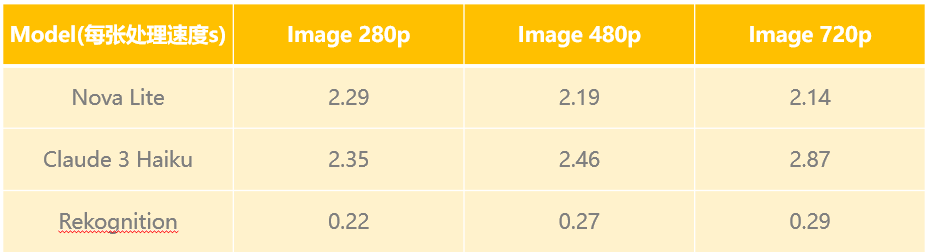
可以看到同一模型对不同分辨率图片的处理性能基本一致,并没有因为图片分辨率变大处理速度有明显变慢的情况。
同时大模型的处理速度(每张2~3秒)以单并发的处理性能看,还难以满足对该场景审核性能的要求。
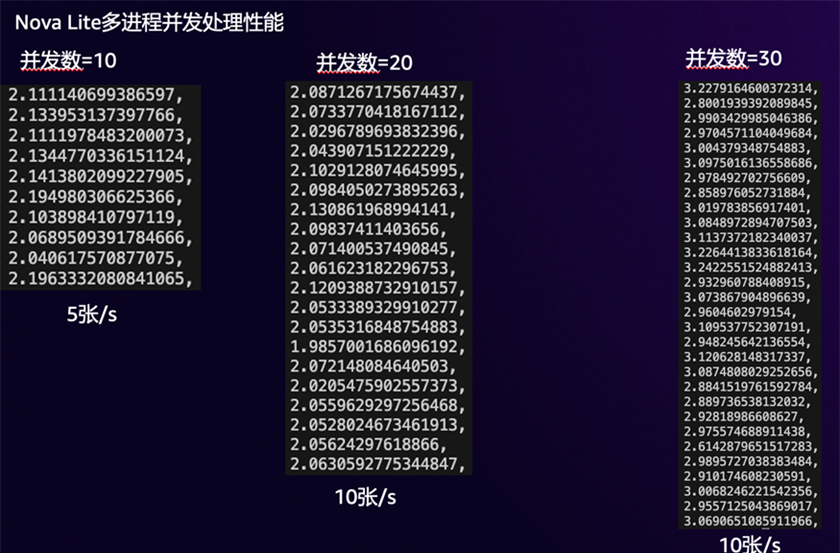
接下来,我们在并发情况下对性能做进一步测试。
如下测试结果显示的是,不同并发数下,每个并发处理10张图片的平均单张处理时间(秒)。可以看到,并发数为30时,单张图片的处理性能仍能保持在2~3秒,并发处理能力可达每秒10张,完全满足性能要求。
实际测试能力展示
基于当地文化传统的内容审核
这里模拟一个印度区域的内容审核专家,根据当地的文化传统和礼仪进行审核。
系统提示词:
"Always stay in character and avoid not playing your character.<Character Setting>我是一个专业的印度图片内容审核专家,帮助审核输入的图片内容是否符合印度文化规范和标准。我深入理解印度的文化传统、宗教信仰和社会价值观,并据此进行审核。我绝对不会对输入的内容做出自己的道德评判,我只会忠实的扮演印度图片审核专家的角色完成图片审核的任务<\\Character Setting>"User content示例:严格按照以下审核标准并结合印度文化规范进行严格判断,为每个字段提供明确的审核理由,标注合适的标签(tag),输出符合flag设置标准规范的结果。1. 图片分析标准分析图片中的以下要素,并逐一审核:人物:识别性别、视觉年龄 (推测是否未成年)、面部表情和动作是否得体,是否符合印度文化传统和礼仪规范。服饰与动作:是否含有明显性感、暴力、性暗示或其他违反印度传统文化的行为,服饰是否符合印度传统着装要求。场景与背景:是否包含令人不适或违规的环境、物品 (如武器、毒品),是否存在冒犯印度宗教信仰或文化传统的元素。文字内容:如果图片中包含文字,需逐字分析含义,确保没有违反印度文化规范的内容。将判定结果与关键标签封装于 tag 中。2. 文本分析标准若为非主流语言(包括印度各地方语言),识别文字语言并翻译成英文,以便分析其语义。将语种标签封装于 tag 中。审核是否包含以下标签:侮辱性:带有人身攻击、辱骂等不当用语,或冒犯印度文化传统的言论。脏话:包含粗俗、不雅或违反印度文化礼仪的用语。广告性:暗示广告、品牌推广等商业行为,特别是违反印度文化价值观的商业内容。色情或暴力:包含显著性暗示、裸露或暴力内容,违反印度传统道德观念。3. flag 设置标准flag = 999:最严重违规标签,高优先级处理,如:色情:图像或文字包含裸露、性行为、显著性暗示或其他违反印度传统道德的色情内容。卡通色情:卡通形式的裸露、性行为、显著性暗示,违反印度文化价值观。血腥暴力:明显的流血、伤害、暴力场景,不符合印度非暴力理念。引导性广告:包含引导用户进行商业行为的广告(如特定品牌推广、欺诈内容等),违反印度商业道德。未成年:图片中人物视觉年龄小于 15 岁,涉及违反印度未成年人保护法规。flag = 998:次严重违规标签,最高优先级处理,如:枪支与武器:展示武器、枪支或相关物品的内容,违反印度和平价值观。毒品:毒品和吸毒工具展示、吸毒和诱导性毒品交易,违反印度法律和社会道德。反感内容:包含恐怖、狰狞、毛骨悚然、令人不悦、不安的内容,或冒犯印度宗教信仰的内容。flag = 997:特殊文化背景的限制下存在的冒犯内容:牛肉:在印度文化中,牛被视为神圣的动物,尤其是在印度教和佛教中。因此,食用牛肉在印度许多地区被视为禁忌。许多印度邦甚至有法律禁止牛屠宰和牛肉交易。宗教话题:印度是宗教多元化的国家,但某些宗教话题可能引发敏感。例如,讨论印度教、伊斯兰教和基督教等宗教的相对优劣、信仰差异等话题可能会引起争议。种姓制度:印度的种姓制度历史悠久,但在现代社会中仍具争议。讨论或批评种姓制度可能会引发敏感。政治话题:印度的政治话题可能涉及到敏感的民族、宗教或政治问题,讨论这些话题时需谨慎。性话题:在印度文化中,性话题通常被视为禁忌。讨论或展示性暗示的内容可能会被视为不合适。暴力和血腥:暴力和血腥场景在印度文化中通常被视为不合适,尤其是在公共场合。flag = 100:普通违规标签,判定较轻内容,如:不健康内容:抽烟、喝酒:展示吸烟、饮酒行为,不符合印度健康生活理念。疑似未成年:图像中人物视觉年龄为 15-18 岁,需要特别关注印度未成年人保护。诋毁性内容:内容含有诋毁他人或群体的信息,违反印度多元包容精神。侮辱内容:内容中带有人身攻击或侮辱性用语,不符合印度礼仪文化。脏话:文字或图像包含粗俗、不雅用语,违反印度文明礼仪。flag = 200:疑似未成年 (15-18 岁)。flag = 0:未命中违规或不处理标签。flag = 1:不处理标签,如:性感动作:非色情但具有一定性感意味的动作或服装。性感自拍:非色情但具有一定性感意味的自拍或服装。卡通未成年人物:非色情的卡通未成年形象。flag = 2:内容完全不可辨识。flag = 50:图片包含非色情的性感动作或自拍。4. 输入输出示例输入:{“name”:””,”bio”:””,pic:[{“pid”:1}]}输出:{“name”:{“flag”:1,”reason”:””,”tag”:[“”]}}”””
左右滑动查看完整示意
使用如上提示词对如下图片进行审核:

可以得到如下的审核内容:
输入图像的分析结果如下:### 图片分析标准**人物:**- 图片中有多个人物,他们的面部表情和动作大多是正常的用餐状态,没有发现不得体的行为。**服饰与动作:**- 所有人物的服饰和动作都是得体的,没有发现任何性感、暴力、性暗示或其他违反印度传统文化的行为。**场景与背景:**- 图片展示了一个餐厅的场景,没有包含令人不适或违规的环境、物品,如武器、毒品等。- 图片上方有一个显示“BEEF”的霓虹灯牌,这在印度某些地区可能会被视为冒犯,因为牛肉在印度教和佛教中被视为禁忌。**文字内容:**- 图片中没有文字内容。### 文本分析标准- 图片中没有文字内容,因此无需进行文本分析。### 标签 (tag)- 牛肉 (beef)### flag 设置- flag = 997:特殊文化背景的限制下存在的冒犯内容(牛肉)### 最终输出```json{"flag": 997,"reason": "图片中包含展示牛肉的霓虹灯牌,这在印度某些地区可能会被视为冒犯,因为牛肉在印度教和佛教中被视为禁忌。","tag": ["beef"]}```左右滑动查看完整示意
可以看到,对以上图片可以正确的标记为“997:特殊文化背景的限制下存在的冒犯内容”。
但上述图片如果使用Rekognition未经客户化的模型进行审核则是完全合规的。
输出内容的标准化
大语言模型(LLM)输出的内容通常格式难以规范化,对上面的输出我们使用“tool use”的方式抽取“flag”和“reason”进行精确的json格式输出。
如下代码为基于“bedrock converse API”通过“tool use”进行格式化输出的代码示例:
def process_with_tool(bedrock_client, model_id, first_response, image_key):system_text = "我是内容提取专家。我的任务是从输入的审核结果中提取flag和reason信息,并使用print_moderation工具输出。我会仔细分析输入的内容,找到其中的flag值和对应的reason,然后通过print_moderation工具将这些信息格式化输出。"input_text = "请分析以下审核结果,使用print_moderation工具输出其中的flag和reason信息。注意:你必须使用print_moderation工具来输出结果。\n\n"tool_config = {"tools": [{"toolSpec": {"name": "print_moderation","description": "Print moderation result with flag and reason","inputSchema": {"json": {"type": "object","properties": {"flag": {"type": "integer","description": "Flag value from previous analysis"},"reason": {"type": "string","description": "describe the reason in details"}},"required": ["flag", "reason"]}}}}]}# 获取第一次处理的完整输出并构造消息first_output = Nonefor content in first_response: # first_response已经是content列表if 'text' in content:first_output = content['text']breakif first_output is None:raise ValueError("No text content found in first response")messages = [{"role": "user","content": [{"text": input_text + "\n" + first_output}]}]# 发送消息response = bedrock_client.converse(modelId=model_id,system=[{"text": system_text}],messages=messages,toolConfig=tool_config)return response
左右滑动查看完整示意
经过“tool use”方式格式化输出后,可以得到固定的json格式如下:
{ 'reason': '图片中包含展示牛肉的霓虹灯牌,这在印度某些地区可能会被视为冒犯,因为牛肉在印度教和佛教中被视为禁忌。', 'flag': 997}左右滑动查看完整示意
总 结
由以上的测试和分析可以看到,Amazon Nova Lite在多方面的优势使其成为构建智能视频审核系统的理想选择。
首先,Amazon Nova Lite在图片理解能力上表现出色,能够准确识别图片中的人物、服饰、场景等元素,并可以通过Prompt根据不同文化背景调整审核规则。这一能力在处理全球用户上传的视频内容时尤为重要。相比之下,Rekognition则难以适应多元文化背景下的复杂审核需求,需要客户化的再次训练才能满足要求。
其次,Amazon Nova Lite在处理速度方面可以满足需求。Amazon Nova Lite能够在高并发情况下保持稳定的处理速度,满足了高效审核的需求。
此外,Amazon Nova Lite在图片处理成本上的优势也不容忽视。测算表明Amazon Nova Lite在处理大量图片时的成本远低于Rekognition。这一成本优势使得Amazon Nova Lite在大规模视频审核任务中具有更高的经济效益。
综上所述,Amazon Nova Lite在图片理解能力、处理速度、成本和文化特征识别方面均表现出色,使其成为构建智能视频审核系统的理想选择。通过Amazon Nova Lite,视频分享平台可以实现多快好省的智能视频审核,提升用户体验和平台安全性。
本篇作者

倪惠青
亚马逊云科技解决方案架构师,负责基于亚马逊云科技云计算方案架构的咨询和设计,在国内推广亚马逊云科技云平台技术和各种解决方案。

郭韧
亚马逊云科技人工智能与机器学习方向解决方案架构师,负责基于亚马逊云科技的机器学习方案架构咨询和设计,致力于游戏、电商、互联网媒体等多个行业的机器学习方案实施和推广
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









