



K8s与无服务器:用API部署事件驱动
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Kubernetes Api Deployment, Event-Driven Architectures, Serverless Compute Choices, Developer Autonomy, Platform Engineering]
导读
许多组织同时在亚马逊云科技无服务器服务和Kubernetes上运行其工作负载。虽然组织及其平台团队希望给予开发人员使用他们偏好技术快速前进的能力,但他们可能面临支持两个不同平台(用于部署应用程序到Amazon EKS和无服务器服务)的挑战,以及处理低效流程和不协调工具的问题。在本次会议中,了解如何使用ACK等工具通过Kubernetes API部署无服务器、事件驱动的架构,如何扩展现有的Kubernetes平台以部署可组合的无服务器架构,以及如何让开发人员轻松访问他们偏好的技术选择。
演讲精华
以下是小编为您整理的本次演讲的精华。
在现代应用程序开发的不断演进的环境中,组织一直在寻求创新的方式,为最终客户创造价值,并保持领先于竞争对手。在这一追求的核心是采用架构模式来促进模块化、卸载非差异化的重型工作的运营模型、自动化和标准化的软件交付流程,以及管理和治理的共同责任。此外,集成专门构建和解耦的数据库,以及能够扩展到数十亿用户、响应毫秒级用户请求和处理PB级数据的能力已成为当务之急。
正如Emily Shea、亚马逊云科技 Serverless的市场推广团队领导人所精辟阐述的那样,客户广泛采用了两种不同的运营模型来构建他们的现代应用程序。第一种方法围绕无服务器或亚马逊云科技原生服务,利用固执己见的亚马逊云科技 API和自动化功能。这种模式强调自主开发团队、低基础设施管理开销,以及为新应用程序(包括运营费用)降低总体拥有成本的共同努力。客户倾向于采用这种运营模型的服务通常包括ECS、Fargate、用于无服务器功能的Lambda、App Runner,以及EventBridge和Step Functions等应用程序集成服务,以及更广泛的亚马逊云科技原生和无服务器服务生态系统。
第二种运营模型围绕Kubernetes及其生态系统。倾向于这种方式的客户优先考虑Kubernetes API和自动化工具,通常强调集中式平台团队和整个组织的标准化实践。他们更有可能拥有内部开发人员平台,应用程序开发人员可以访问自助服务功能。此外,他们非常重视利用围绕Kubernetes的社区和开源生态系统。这些客户经常使用的亚马逊云科技服务包括用于运行Kubernetes集群的EKS、在EC2实例上运行Kubernetes,以及用于运行容器的RoSA。
Emily Shea阐明了大多数大型组织所面临的现实——计算选择的异构混合,而不是严格标准化于单一技术。这种多样性可能源于收购、技术偏好或针对特定计算选择优化特定工作负载的需求,如使用Amazon Lambda来处理需要快速扩展的工作负载。
为了说明这一点,Emily举了英国政府的驾驶和车辆许可机构(DVLA)的例子,该机构负责维护全国驾驶员和车辆的登记册,并每年收取约60亿英镑的收入。DVLA最近着手对其驾驶员服务应用程序进行大规模现代化,不仅涉及更新展示层,还包括重构和现代化后端,以有效利用云并为应用程序的未来发展做好准备。
DVLA的架构展示了Kubernetes和无服务器组件的和谐融合。他们利用Kubernetes,特别是Amazon Elastic Kubernetes Service (EKS),用于标准组件,如用于UI的Ruby on Rails和一个健壮的Java技术栈,其中包含100多个组件和库,以自助服务的方式提供给100多名使用该平台的开发人员。然而,当涉及到应用程序处理后端时,他们认识到无服务器和事件驱动方法的适用性,因为涉及异步流程和工作流,如处理驾驶执照申请、处理照片上传和纳入人工审批步骤。
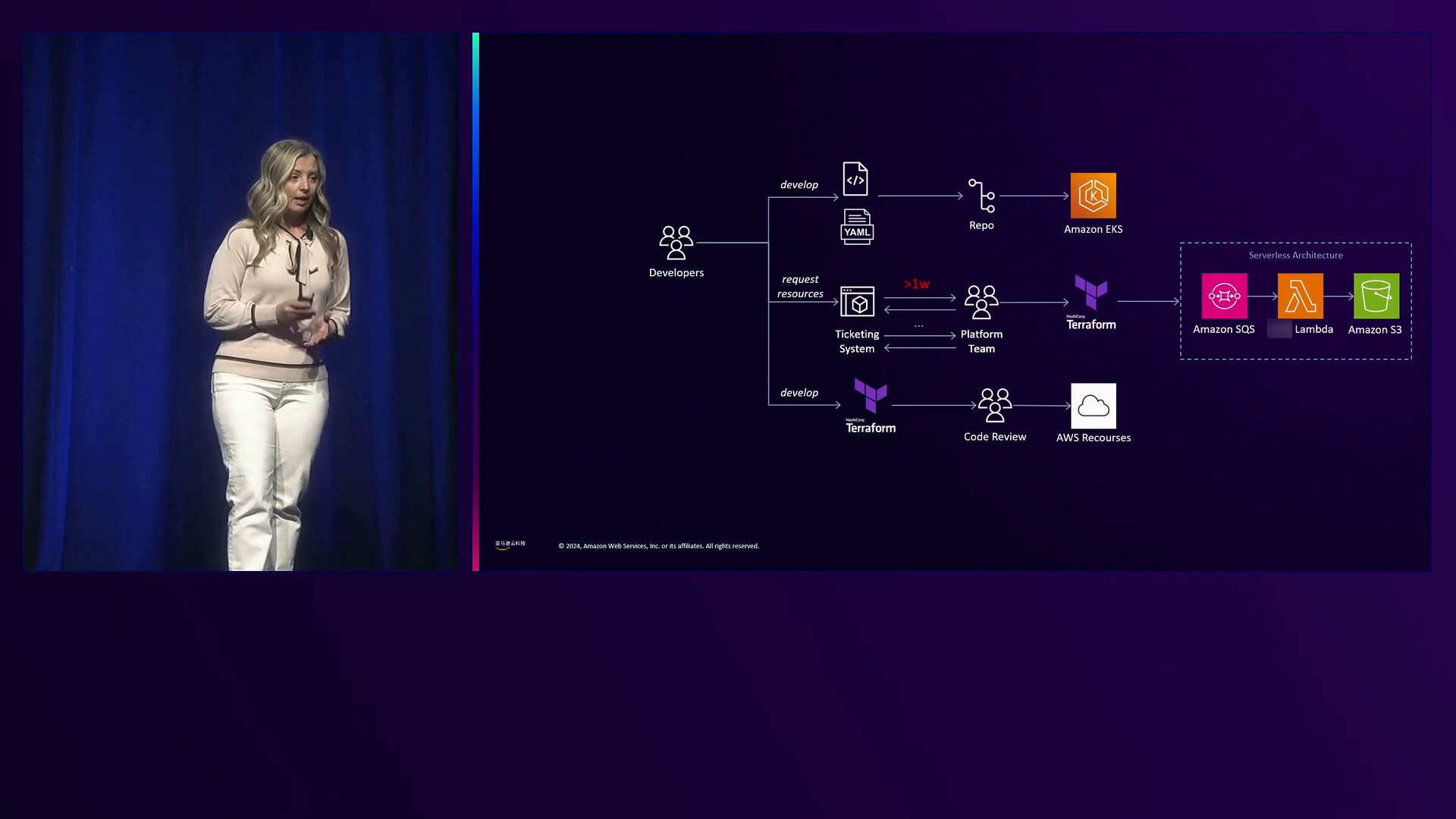
Christina Andonov是亚马逊云科技的一名解决方案架构师,她分享了作为前平台工程师的经历,当时她在为开发人员提供所需的亚马逊云科技资源时遇到了挑战。她的团队使用Terraform来管理他们的Kubernetes集群,并为开发人员提供工具将应用程序部署到这些集群。但是,当开发人员需要S3存储桶或Lambda函数等亚马逊云科技依赖项时,就需要一个工单流程。这个过程涉及开发人员开具工单,然后Christina的团队成员会复制并粘贴Terraform代码来创建所请求的资源,如S3存储桶,并向开发人员提供存储桶位置。工单数量相当可观,需要一个Christina称之为“英雄轮值”的轮换制度,尽管她承认在那些星期里感觉远非英雄。Christina提到他们每周都会收到相当数量的工单,以至于需要一个轮换制度。
Lambda函数的请求尤其具有挑战性,因为它们通常需要大量的来回沟通才能理解触发机制、结果存储位置和其他细节,从而进一步延长了流程。Christina承认,请求Lambda函数的工单可能需要一周以上的时间,因为涉及来回沟通,等她弄清楚开发人员想让她构建什么时,那就成了她的“有趣的一周”。
认识到需要改进,Christina和一群志同道合的人决定解决这个问题,不仅针对Kubernetes依赖项或无服务器架构,而是针对整个组织。他们与各个团队进行了咨询,包括数据平台、数据库以及安全和合规团队,并共同决定构建一个全新的Terraform平台。该团队首先将高级用户(如数据平台、数据库以及安全和合规团队)纳入平台,然后再向开发人员开放平台。
然而,他们很快意识到Terraform管道经常会失败,有时甚至没有明显的原因——这个问题已经如此普遍,以至于他们的大脑已经学会了忽略它。Christina将失败的Terraform管道的体验比作房间角落里一把凌乱的椅子,她的大脑多年来已经开始忽略它。
对于新加入平台的开发人员来说,遇到失败的Terraform管道是一个重大障碍,因为他们缺乏独立排查和解决问题所需的多年Terraform经验。因此,开发人员会回到工单系统,寻求“英雄”们的帮助来修复他们的管道。
虽然该平台提供了诸多好处,如与更广泛的平台团队的改善协作以及增强的安全和合规状况,但它未能实现其主要目标之一:通过排除平台团队来提高开发人员的工作效率。
加入亚马逊云科技后,Christina继续与客户互动,发现许多组织都面临类似的挑战。她试图了解平台激增的原因,并得到了一个普遍的回应:组织希望赋予开发人员自主权。Christina观察到,初创公司往往赋予开发人员相当大的自主权,有时甚至会提供亚马逊云科技账户的管理员密钥。随着组织的成熟,它们引入了标准、工具,在某些情况下还统一了单一运行时。然而,随着组织的发展和收购公司,被收购的实体通常带来了与组织标准化的运行时相反的运行时,从而延续了异构性的循环。
Christina认识到,解决方案不在于标准化单一计算选择,而在于根据工作负载特征选择适当的计算,有些工作负载更适合Lambda,有些则更适合Kubernetes。
回顾之前的经历教训,Christina意识到,虽然Terraform平台提供了诸多好处,但它并没有解决排除平台团队的具体问题。此外,该团队最初考虑过构建自定义Kubernetes控制器,但由于能够开发和支持此类控制器的团队成员有限,因此存有疑虑。
当时,该团队评估了开源的亚马逊云科技 Controllers for Kubernetes (ACK)项目,该项目为各种亚马逊云科技服务提供了预构建的控制器。然而,当时该项目只有13个控制器,该团队对亚马逊云科技未来开发计划存有疑虑。
现在作为亚马逊云科技员工,Christina可以阐明ACK取得的进展。早些时候,EKS服务团队认识到最初方法的局限性,因此接手了所有ACK控制器。截至re:Invent 2024大会,ACK已达到50个通用可用性(GA)控制器,并获得企业支持,使客户能够通过这些控制器在Kubernetes上部署无服务器架构。
然而,仅有ACK是不够的,无法部署无服务器架构。Christina和她的团队认识到还需要其他机制,例如为开发人员提供适当的界面,将资源组合成逻辑分组,并在它们之间传递资源引用和值。这一认识导致了另一个开源项目Craw (Cube Resource Orchestrator)的开发,亚马逊云科技在re:Invent 2024大会前约两周对其进行了开源。
Craw旨在运行在任何Kubernetes集群上,无论是内部部署还是本地集群,被视为采用Kubernetes资源模型来部署亚马逊云科技资源(包括无服务器架构)的最后一块拼图。
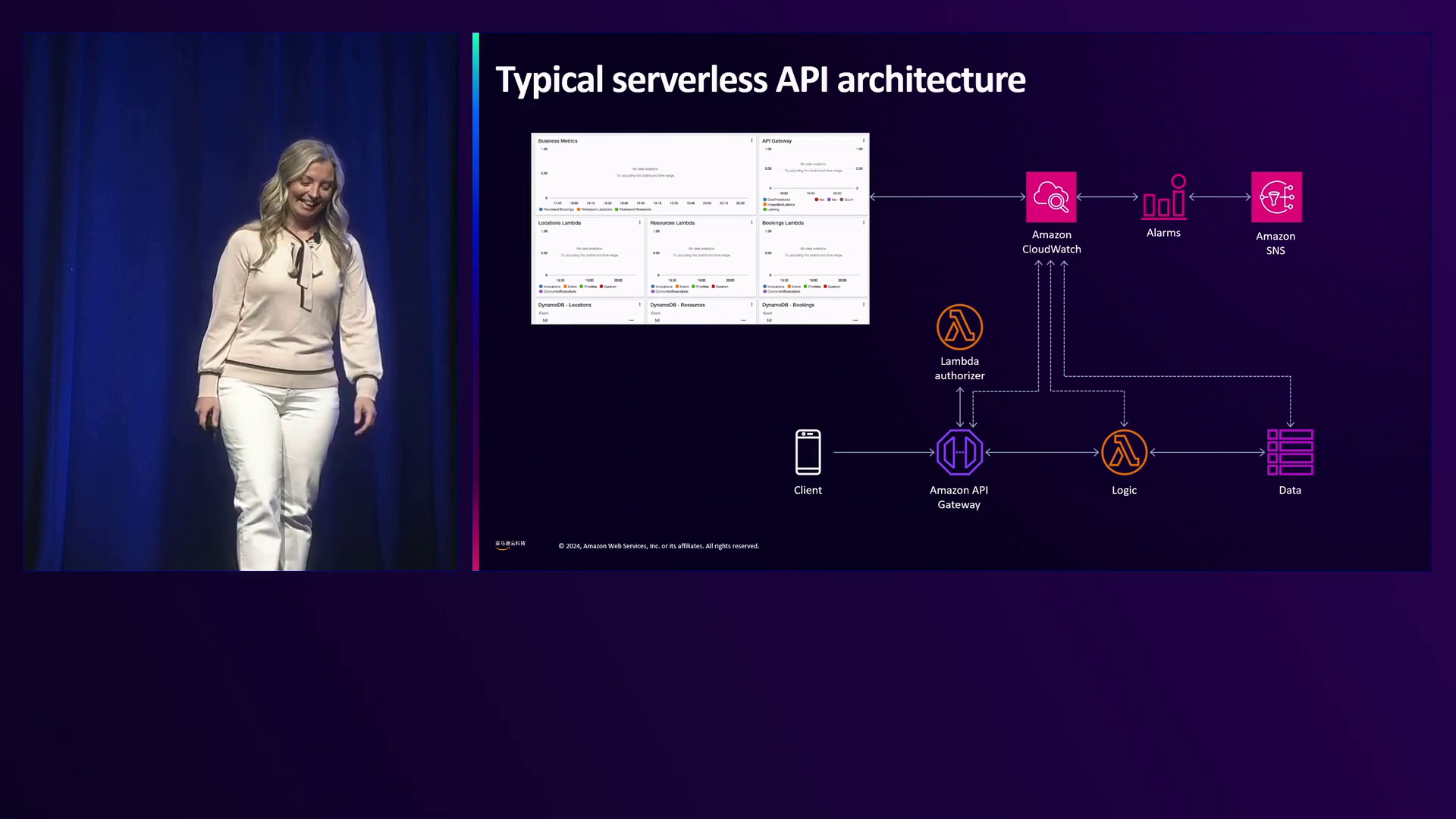
为了展示Craw的功能,Christina介绍了Gedrias,亚马逊云科技的另一位解决方案架构师,他分享了一个数据处理示例,将Apache Spark与Amazon Elastic Kubernetes Service (EKS)结合使用,并通过S3事件触发Amazon Step Functions工作流。
Gedrias概述了演示工作负载的要求,包括每个工作负载的命名空间隔离以确保分离、在S3上实现最小特权以防止数据工程师访问未经授权的存储桶或脚本,以及允许数据工程师部署工作负载而无需额外权限或管理员模型。
该演示工作负载模拟了一个场景,其中数据对象到达S3存储桶,在Amazon EventBridge中触发事件。EventBridge然后基于规则启动Step Functions工作流,并传递有关传入数据对象的信息。工作流协调数据处理,在EKS上指定的命名空间中启动虚拟EMR集群上的Apache Spark作业。
Spark作业从S3拉取数据,使用指定的脚本对数据进行分析,并将输出数据保存回S3存储桶。与此同时,Step Functions工作流将传入数据复制到数据湖(另一个S3存储桶),以便存档或进一步处理,并遵守数据保留规则。
一旦Spark作业完成,工作流从S3输出存储桶读取结果(存储在S3存储桶的输出前缀中的JSON格式),并将它们存储在Amazon DynamoDB数据库中,该数据库直接在Step Functions工作流中实现,无需额外的Lambda代码。任何需要处理后数据的API或服务都可以访问此DynamoDB数据库。最后,工作流向Amazon EventBridge自定义事件总线发送事件,通知订阅者(如Amazon Simple Notification Service (SNS))数据处理已完成。在演示中,SNS接收事件并向指定的收件人电子邮件地址发送通知。
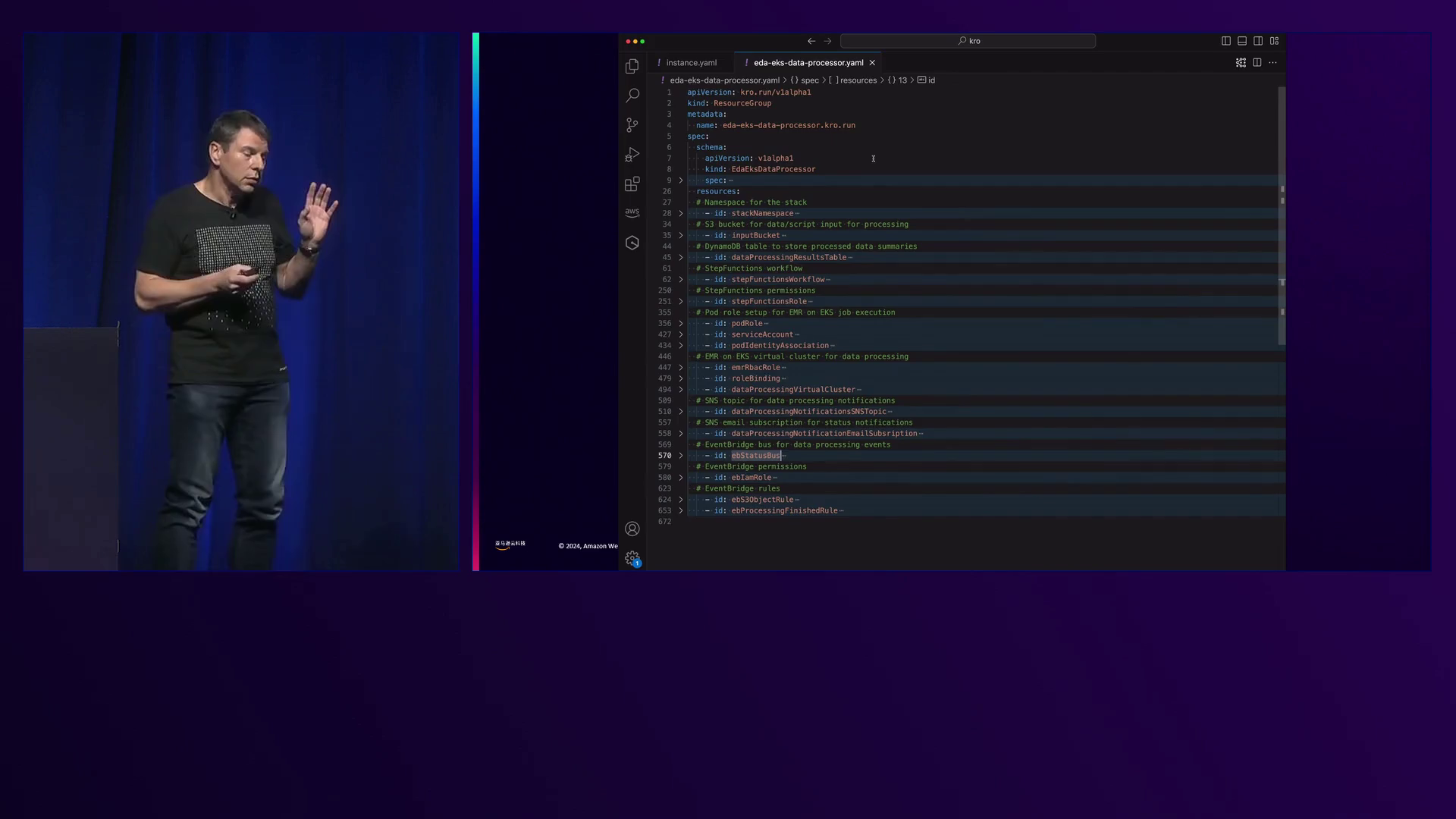
Gedrias展示了使用Craw通过Kubernetes API部署整个堆栈的代码。从数据工程师的角度来看,代码由大约20行YAML组成,指定输入存储桶、Spark脚本名称、通知电子邮件地址和一些默认值。
对于平台工程师,代码定义了一个Craw资源组,其中包含所有所需资源,如命名空间、输入存储桶、DynamoDB表架构、Step Functions工作流定义(使用Amazon States Language (ASL)约170行JSON内联在YAML中)、EMR在EKS虚拟集群、SNS主题和订阅。值得注意的是,指定的策略实现了最小特权访问,将权限锁定在特定存储桶、输入前缀、临时处理、输出,甚至脚本,只允许数据工程师使用特定的脚本名称。
Gedrias使用ArgoCD部署了资源组,并浏览了演示环境,显示了初始状态,其中存储桶为空,DynamoDB表中只有2条记录,2个摘要,一个用于1月数据,一个用于2月数据。QuickSight仪表板已加载了一些数据,显示了两个供应商的2个月数据,分别有430万条记录和130万条记录,以及按供应商的平均费用、支付类型分布和最昂贵行程的可视化。
Gedrias随后将3月、4月和5月的纽约出租车数据示例文件上传到输入S3存储桶,触发了三个并行的Step Functions工作流执行。随着演示的进行,输入文件在处理后从S3存储桶中删除,副本存储在数据湖存储桶中。DynamoDB表中填充了3条额外的摘要记录,QuickSight仪表板使用处理后的数据进行了更新,现在显示了两个供应商分别有1100万和370万条行程记录的5个月数据。
最后,Gedrias收到三封确认数据处理工作负载成功完成的通知电子邮件,演示了端到端的编排和通过Kubernetes API的部署。
Christina之前提到的数据处理示例和微服务示例都可在Craw存储库的示例部分找到,为客户提供了一个全面的资源来探索和实现这些架构。
总之,Emily Shea在会议结束时强调了几个关键要点。首先,她承认组织在构建现代应用程序时会出现异构技术选择,根据特定工作负载的要求,容器/Kubernetes和无服务器/Lambda都有其存在的位置。
其次,她强调了客户可以使用的令人兴奋的新工具,如开源的亚马逊云科技 Controllers for Kubernetes (ACK)和最近发布的Craw项目,这些工具可以通过Kubernetes API部署无服务器资源,为组织内部提供无缝的开发体验。
最后,Emily强调了赋予开发人员API和工具的重要性,这些工具可以最大限度地减少开销,减轻平台团队的负担,从而提高开发人员的工作效率和自主权。
本次会议展示了亚马逊云科技客户如何利用Kubernetes和无服务器架构的优势为其现代应用程序,使用ACK和Craw等工具通过Kubernetes API部署事件驱动的无服务器工作负载。这种方法允许开发团队使用首选的计算选择,同时使平台团队能够提供治理和标准,正如DVLA和所展示的演示示例所示。
下面是一些演讲现场的精彩瞬间:
Emily Shea是亚马逊云科技无服务器产品市场推广团队的负责人,她介绍了自己以及同事Christina和Gedrias,他们是亚马逊云科技的高级解决方案架构师。

演讲者强调了开发人员在Terraform管道意外失败时所面临的挫折,这会导致延迟并需要依赖专家寻求帮助。
Gidrius向Christina阐明了无服务器架构的真正本质,挑战了她以Kubernetes为中心的观点。
演讲者解释了他们计划演示一个基于著名的纽约出租车数据集的分析数据平台用例,使用Spark on Kubernetes和亚马逊云科技服务如EMR、Step Functions、Lambda和S3来创建事件驱动架构。

详细阐述了平台工程师如何使用Amazon CloudFormation模板定义和供应云资源,包括命名空间、输入存储桶、DynamoDB表、Step Functions工作流以及其他服务如EKS集群和SNS主题。
演讲者展示了Amazon Compute Optimizer和Amazon Cloud Control API的二维码,提供了代码样例和工具,用于构建具有不同计算选择的现代应用程序。

总结
现代应用程序开发世界正在快速发展,组织正在采用多种运营模式和计算选择。本文探讨了在大型企业中集成Kubernetes和无服务器架构所面临的挑战和解决方案。
客户正在朝着两条不同的道路发展:采用亚马逊云科技本地方法,利用Lambda、ECS和Fargate等服务,或者采用Kubernetes生态系统,利用EKS和开源工具。然而,许多组织发现自己处于异构环境中,团队根据工作负载需求、收购或技术偏好采用不同的计算选择。
为了解决这种复杂性,亚马逊云科技推出了开源项目亚马逊云科技 Controllers for Kubernetes (ACK)和Cube Resource Orchestrator (Craw)。ACK提供了通过Kubernetes部署亚马逊云科技资源(包括无服务器架构)的API,而Craw则能够在Kubernetes集群内对资源进行分组和抽象、传递值以及执行逻辑操作。
演示展示了一个数据处理示例,其中EKS上的EMR集群处理来自S3存储桶的数据,由Amazon Step Functions编排。工作流将数据复制到数据湖,使用Apache Spark进行处理,并将结果存储在DynamoDB中,展示了Kubernetes和无服务器组件的无缝集成。
总之,本次会议强调了为开发人员提供API和自助服务平台的重要性,使他们能够为工作负载利用最佳计算选择,同时促进平台团队和开发团队之间的协作。通过ACK和Craw等工具将Kubernetes和无服务器架构相结合,有望加速创新并提高现代应用程序开发的开发人员生产力。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









