



探索在亚马逊云上训练基础模型的多种方式
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, HyperPod, Foundational Models Training, Amazon Web Services Infrastructure, Distributed Training Orchestration, Accelerated Computing Instances, Self-Healing Resilient Clusters]
导读
训练大规模基础模型面临着独特的挑战。本次会议将深入探讨构建和扩展这些模型的复杂性。从选择最佳计算资源(包括GPU、Amazon Trainium和Amazon Inferentia),到使用Amazon S3、Amazon FSx for Lustre或NVMe优化数据管道,以及通过弹性结构适配器最大化网络性能。会议还将介绍Amazon SageMaker HyperPod如何帮助您节省高达40%的训练成本。您将获得克服挑战并在基础模型训练中实现最佳性能的实用指导,并了解客户如何利用亚马逊云科技 AI芯片为多代理个人AI训练他们的基础模型。
演讲精华
以下是小编为您整理的本次演讲的精华。
探索在亚马逊云科技上训练基础模型的过程始于对多年来模型复杂度和参数数量呈指数级增长的讨论。演讲者解释说,这种增长是由于需要更好地理解复杂问题并同时处理多项任务,如语言和数学。早期的模型,如1957年的感知器,让位于更先进的模型,如具有6200万个参数的AlexNet。然而,到2024年,拥有3万亿个参数的模型已成为现实,这一趋势预计将继续下去,以便更好地理解我们周围的世界。
训练这些庞大的模型需要巨大的计算能力,以每秒浮点运算次数(petaflops)来衡量。虽然2017年GPT的计算需求约为10,000 petaflops,但最近的GPT-4模型需要数千亿petaflops来训练。演讲者强调,这些模型可能需要数天甚至数月的时间才能完全训练,突出了任务日益复杂的特点。
为了支持训练这些基础模型,亚马逊云科技提供了一个全面的生成式AI堆栈,从基础设施层开始。该层包括GPU实例,如P4D、P4de、P5以及新推出的采用NVIDIA H100 GPU和第二代EFA(Elastic Fabric Adapter)的P5E实例,用于超低延迟网络。此外,亚马逊云科技还提供Amazon EC2 Capacity Blocks,允许客户在需要进行训练时预留容量,不需要时则释放。基础设施层还包括用于训练的Trinium实例、用于推理的Inferentia芯片、用于机器学习操作的Amazon SageMaker以及EFA网络。
在基础设施层之上是诸如Amazon Bedrock之类的服务,可以促进推理解决方案的构建和部署,以及Amazon Q套件服务,可以自动从内容中提取见解。演讲者主要关注用于分布式训练大型语言模型的基础设施组件。
演讲者提供的架构概览说明了参与训练过程的各种亚马逊云科技服务。计算节点(可能是P5或P4D实例)位于亚马逊云科技服务账户中,而用户可以在登录节点提交作业。数据存储在客户账户中的S3(简单存储服务)和FSx for Lustre文件系统中,并通过VPC(虚拟私有云)对等连接与服务账户节点通信。Prometheus监控系统从计算节点抓取指标,这些指标可以在Amazon Managed Grafana仪表板上可视化。
演讲者演示了如何在一小时内使用HyperPod服务设置一个包含1,967个P5节点的大型集群,并运行分布式训练作业。HyperPod提供了几个增强训练过程的功能,包括自动恢复功能,以确保在节点发生故障时可以从最后一个已知检查点恢复作业。它还提供了SSH访问节点、自定义训练环境的灵活性以及多用户支持。演讲者展示了一个仪表板,显示了1,967个节点的ECC错误、XID错误、热错误和缺失GPU的指标。
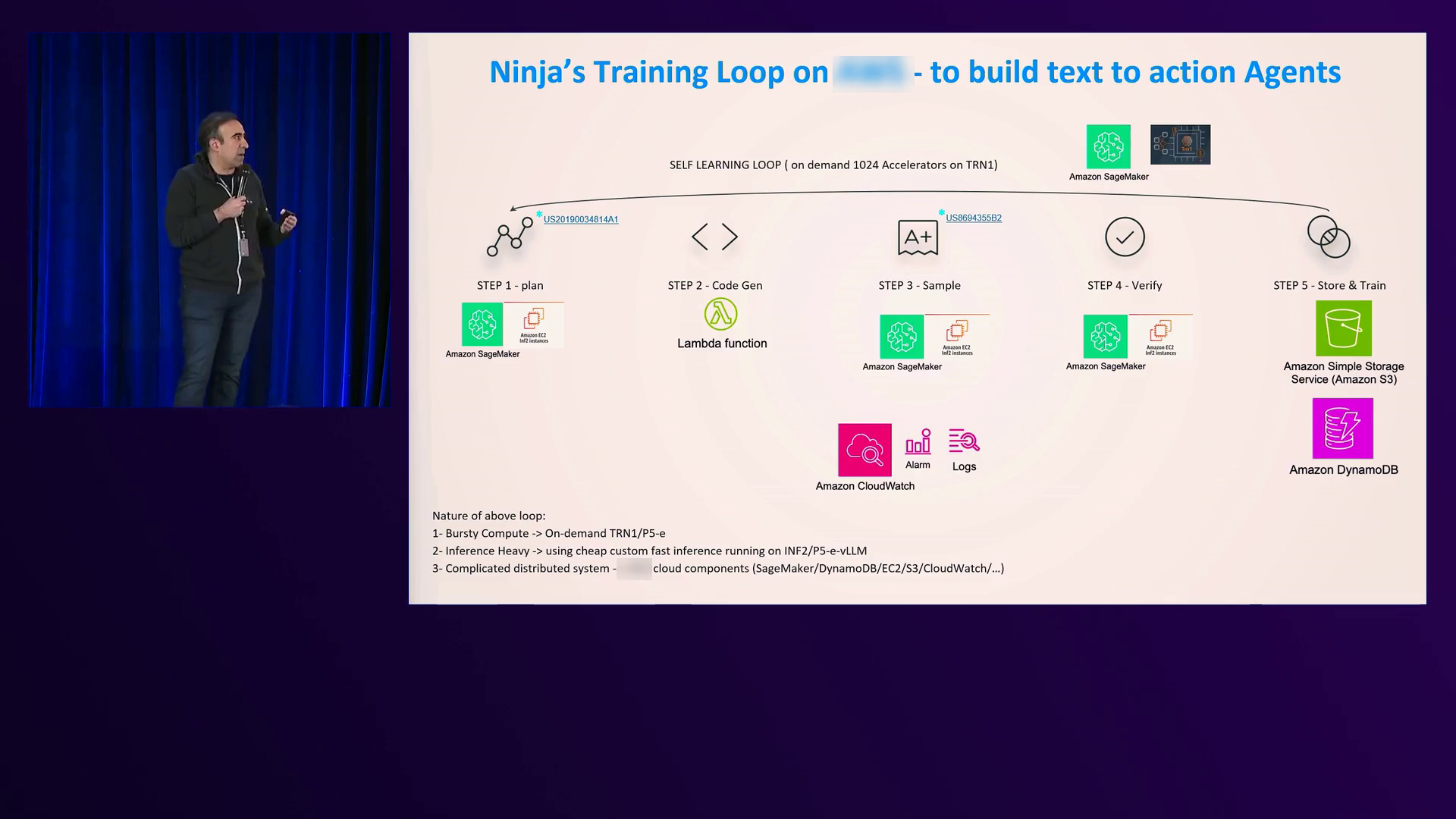
然后,演讲者介绍了NinjaAI的首席执行官Babak Patalavan,他讨论了他的公司如何利用亚马逊云科技以经济高效的方式训练和服务他们的“超级代理”AI系统。NinjaAI提供订阅访问一个编排器,根据输入意图激活不同的AI模型和代理。该系统利用他们自己的LLaMA模型,其核心模型基于LLaMA 4或5b,并集成了外部模型,如GPT-4、Anthropic的Claude、Google的PaLM等。
Patalavan解释了NinjaAI训练系统的六个步骤:创建计划、生成代码、创建样本、验证执行、选择经过验证的样本以及微调模型。这个过程允许他们的系统动态生成代码来实时编排正确的AI代理,而不是依赖预先编程的工作流程。Patalavan强调,这种方法是通过利用亚马逊云科技基础设施实现的,包括SageMaker、Lambda、CloudWatch、DynamoDB和S3等服务。
NinjaAI开发了一种“超级代理”方法,结合了多个大型语言模型(如GPT-4、Claude和PaLM)的输出。该系统使用他们自己的模型(包括基于Nematron的评论模型)对这些输出进行评论,并产生一个改进的复合输出。他们新的“Apex”超级代理利用了GPT-4、Claude、Gemini Pro,并使用Claude作为评论模型,在Arena Hard提示的基准测试中取得了94.3/500的出色成绩,超过了OpenAI的InstructGPT(92分)。此外,Apex超级代理在Misguided Attentions基准测试的13个棘手提示上也优于单个模型,如GPT-4、Claude、LLaMA 4或5b和Gemini 1.5 Pro。
Patalavan表示,亚马逊云科技服务对于NinjaAI的训练和推理管道至关重要,使其变得可承受。他强调使用CloudWatch来调试部署问题、使用DynamoDB通过快速存储用户提示实现个性化,以及将SageMaker作为最终编排器来链接训练事件。他还提到使用S3进行经济高效的模型权重存储。Patalavan鼓励观众尝试他们的系统并提供反馈,强调持续改进的重要性。
演讲者随后概述了“Awesome Distributed Training”仓库,这是一个宝贵的资源,用于跨各种亚马逊云科技服务(包括HyperPod、EKS(Elastic Kubernetes Service)和Amazon Batch)设置分布式训练工作流。该仓库提供了分步指南,用于创建VPC、HyperPod架构、EKS集群和Batch环境。它提供了优化的Docker文件、常见问题解答和小抄,用于解决常见错误和设置环境变量。
该仓库还包括运行流行的分布式训练框架(如Nemo、Mosaic ML、PyTorch和TensorFlow)的配方和示例,使用分布式数据并行(DDP)和完全分片数据并行(FSDP)等技术。它涵盖了使用Mosaic ML运行稳定扩散、在EKS或Batch上运行Nemo以及并行化工作负载等场景。此外,该仓库还提供了使用Prometheus和Grafana仪表板设置可观察性的指导,以及使用Amazon Insight在Slurm或Kubernetes集群上进行性能分析的分析。
总之,这个视频探讨了亚马逊云科技用于训练大型基础模型的全面堆栈,展示了P5 GPU实例、用于快速集群供应的HyperPod、用于编排的SageMaker以及其他组件。它还强调了NinjaAI创新的“超级代理”方法,该方法结合并微调多个大型语言模型,利用亚马逊云科技基础设施在Arena Hard和Misguided Attentions等基准测试中取得了最先进的成绩。演讲者强调,利用亚马逊云科技服务可以实现这些复杂模型的经济高效和可扩展训练,同时还提供了通过“Awesome Distributed Training”仓库设置分布式训练工作流的资源和最佳实践。
下面是一些演讲现场的精彩瞬间:
演讲者深入探讨了模型复杂性的演变、亚马逊云科技上的AI堆栈以及在云平台上编排机器学习训练的工具和服务。

亚马逊云科技使客户能够轻松开始使用其容量预留服务,在入职会议后一小时内即可创建和运行工作负载。
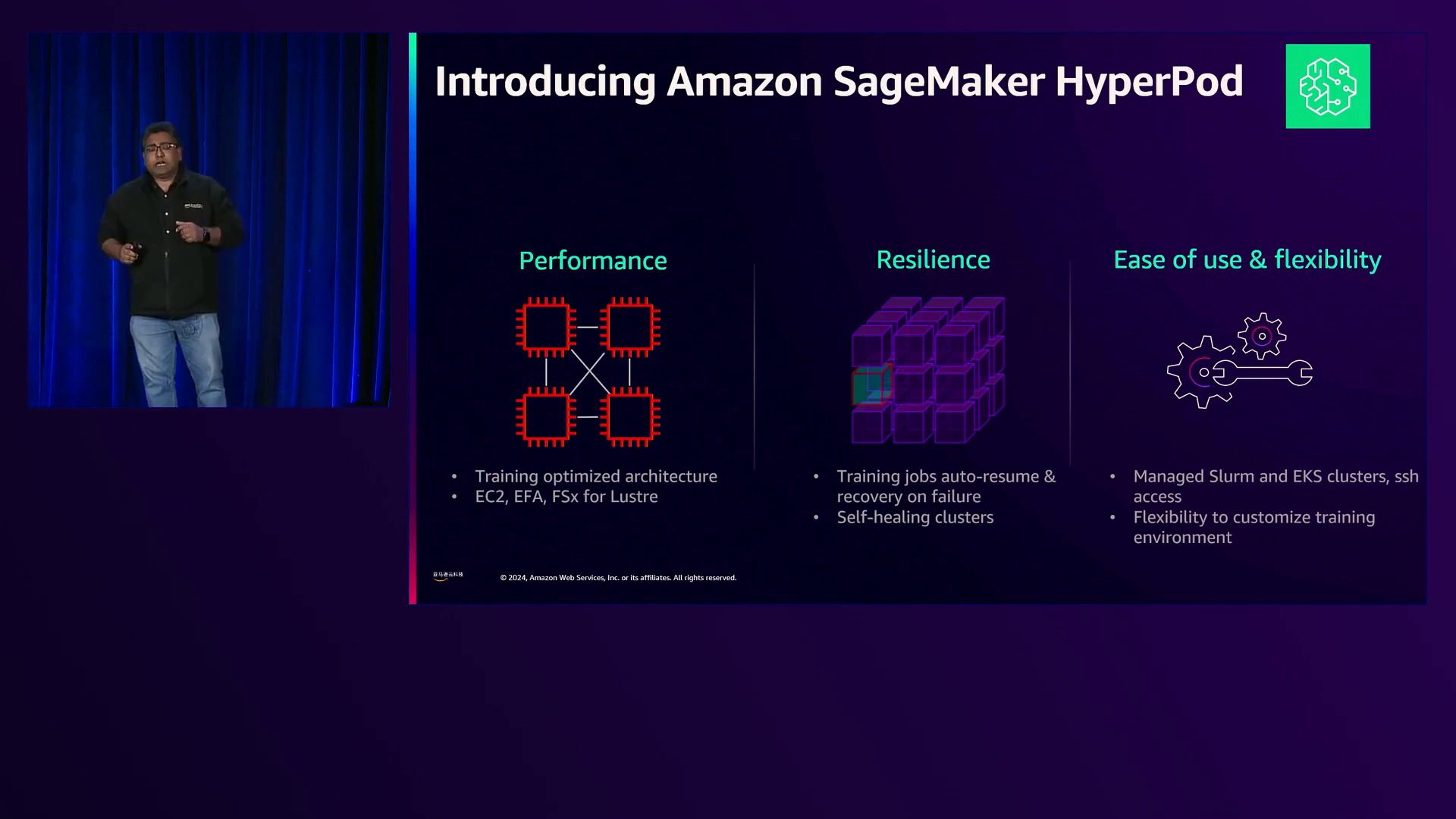
Hyper Pod’s的恢复能力,具有自动恢复作业和自我修复集群的功能,确保即使GPU发生故障也能持续不间断地进行训练。
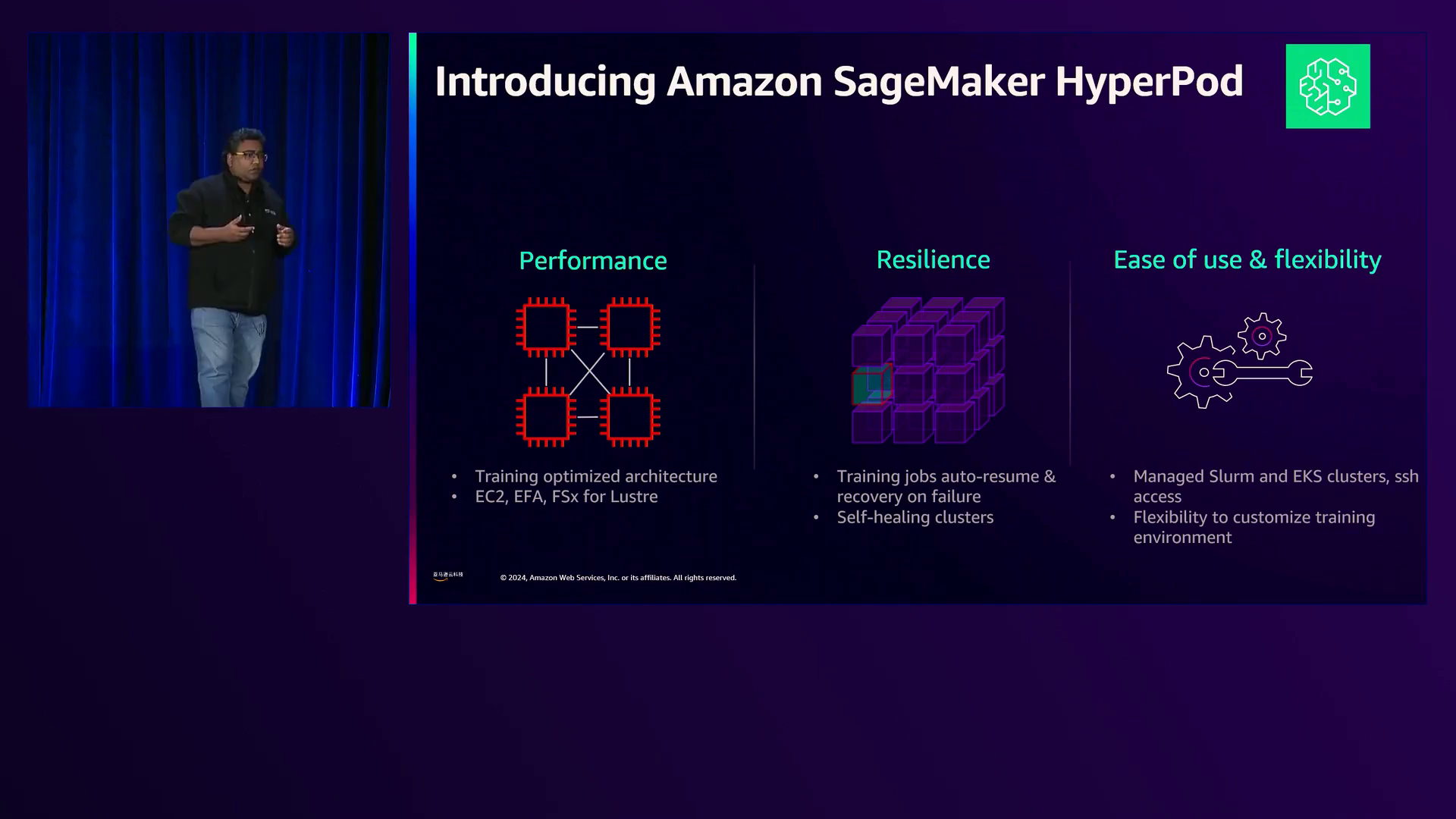
Hyperport提供无缝的SSH访问计算节点,便于在EKS集群上自定义和管理训练环境。
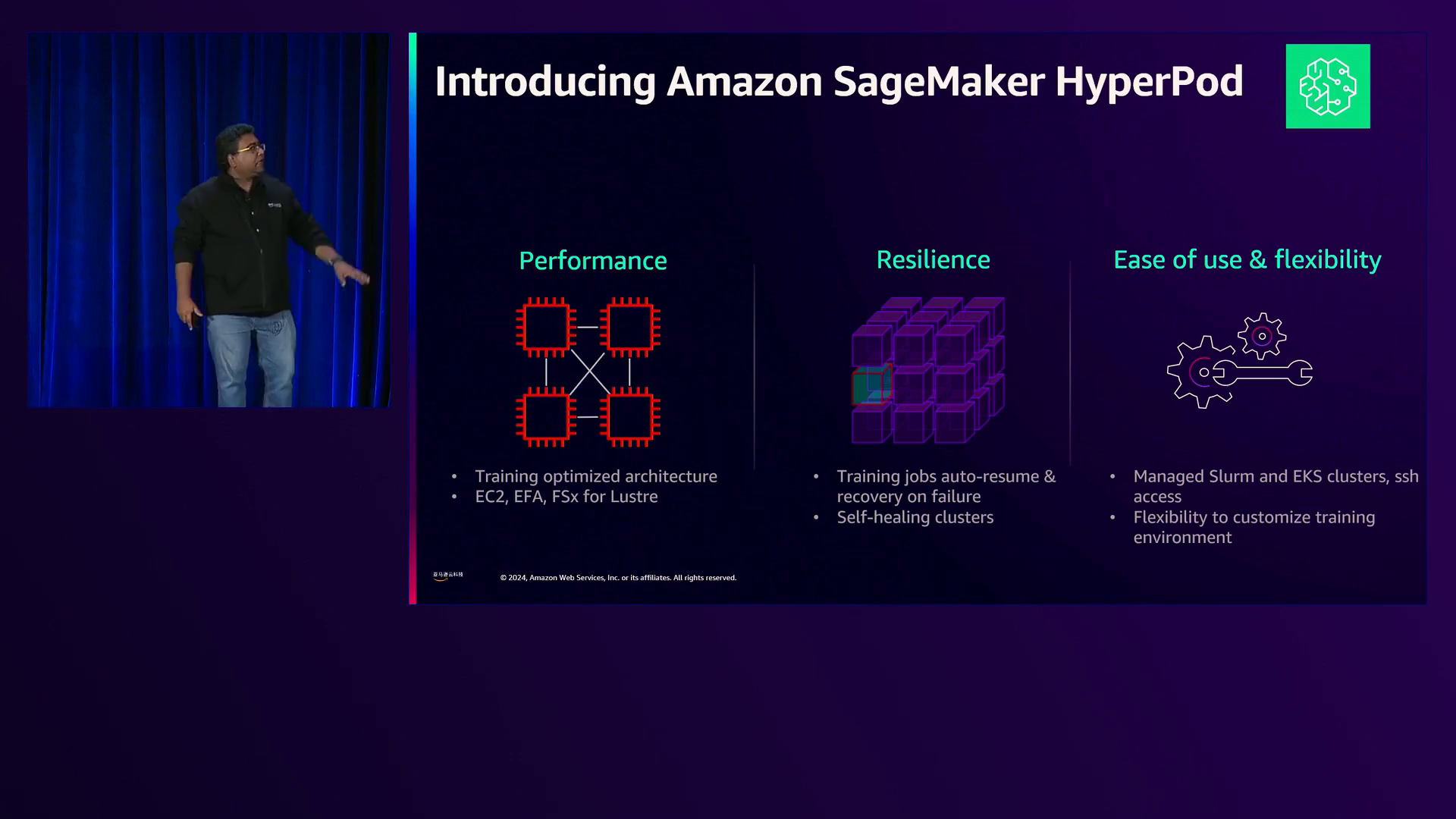
解释了hyperport集群中计算节点的架构和管理,强调了研究人员、工程师和运营团队之间职责的分离。

NinjaAI实时生成和微调代码,以编排复杂的架构,确保准确性和预期功能。
演讲者讨论了Nickel测试,这是一种在集群上验证网络配置的常用方法,以及用于监控Slurm或Kubernetes集群的可观察性工具,如Prometheus和Grafana仪表板。

总结
在这场引人入胜的演讲中,我们深入探讨了在亚马逊云科技上训练基础模型的迷人世界。演讲者带领我们一起见证了模型复杂性的演进,从早期的感知器模型到2024年令人瞩目的3T参数,参数数量呈现出指数级增长。这种复杂性的激增需要巨大的计算能力,为了容纳这些先进模型的训练,所需的petaflops数量也在飙升。
亚马逊云科技上的生成式AI堆栈提供了一个全面的解决方案,包括GPU、Trinium、Inferentia、SageMaker、UltraClusters、EFA网络、EC2容量块和Nitro加速等基础设施组件。在此之上,还有Amazon Bedrock用于推理,以及Amazon Q Business、Q Developers、Q Insight和Q Connect等应用程序,用于从内容中提取见解。
亚马逊云科技提供了各种实例,包括最近推出的配备NVIDIA H100 GPU和第二代EFA的P5E实例,以提高性能。HyperPod服务简化了设置和运行分布式训练工作负载的过程,使客户能够在几分钟内启动并运行集群,并具有弹性、易用性和灵活性等关键特性。
演讲最后以NinjaAI的一个引人注目的故事作为结尾,这家初创公司利用亚马逊云科技基础设施来实现对世界上最佳AI模型和代理的民主化访问。他们的创新方法包括实时生成代码来编排各种模型和代理的激活,从而产生复合效应,提高准确性和质量。NinjaAI的“超级代理”在Arena Hard和Misguided Attentions等基准测试中取得了最先进的性能,超过了GPT-4和SoNet等行业巨头,同时保持了经济实惠和高速度。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









