



亚马逊云的数据:3家人工智能创新企业成功的关键
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Canva, Data Curation, Model Training, Storage Performance, Data Scale, Attribution Engine]
导读
组织正在彻底改变他们使用数据来做决策的方式。在这个客户案例分享中,您将了解Anthropic、Bria AI和Canva是如何在亚马逊云科技上构建和管理可扩展且具有成本效益的数据基础,以训练他们的生成式AI模型。探索他们的架构方法、设计模式,以及优化性能的最佳实践,以实现高水平的总体吞吐量、跨大型数据资产管理元数据目录,并负责任地存储AI生成的内容。深入了解如何将数据环境与容器化应用程序集成、大规模数据准备、数据加载和检查点技术,以及负责任地构建生成式AI。
演讲精华
以下是小编为您整理的本次演讲的精华。
本次会议由Andrew Kutsey揭开序幕,他强调组织面临着来自销售交易、客户互动、物联网流和图像目录等渠道的海量原始数据。他指出,团队通常需要针对特定业务问题、分析难题或机器学习模型调优,从这些数据中提取精心策划、重点突出的视角,而不是整个庞大的数据集。
Kutsey阐述了数据策划的概念,即构建和装饰专门为特定任务量身定制的数据集,将数据视为一种产品。与一次性使用大量数据存储不同,有目的地策划出针对特定用例的数据集合,例如产品经理希望了解功能采用情况,或者机器学习研究人员需要用于模型训练的数据。
在谈到性能优化时,Kutsey指出,无论计算资源位于何处,客户通常都希望充分利用其存储(如Amazon S3或亚马逊云科技文件服务)与计算资源之间的可用带宽。他列举了在S3环境中需要考虑的三个基本方面:优化请求速率性能(每秒请求数)、请求吞吐量(每个请求传输的字节数)和首字节延迟(客户端收到第一个字节所需的时间)。
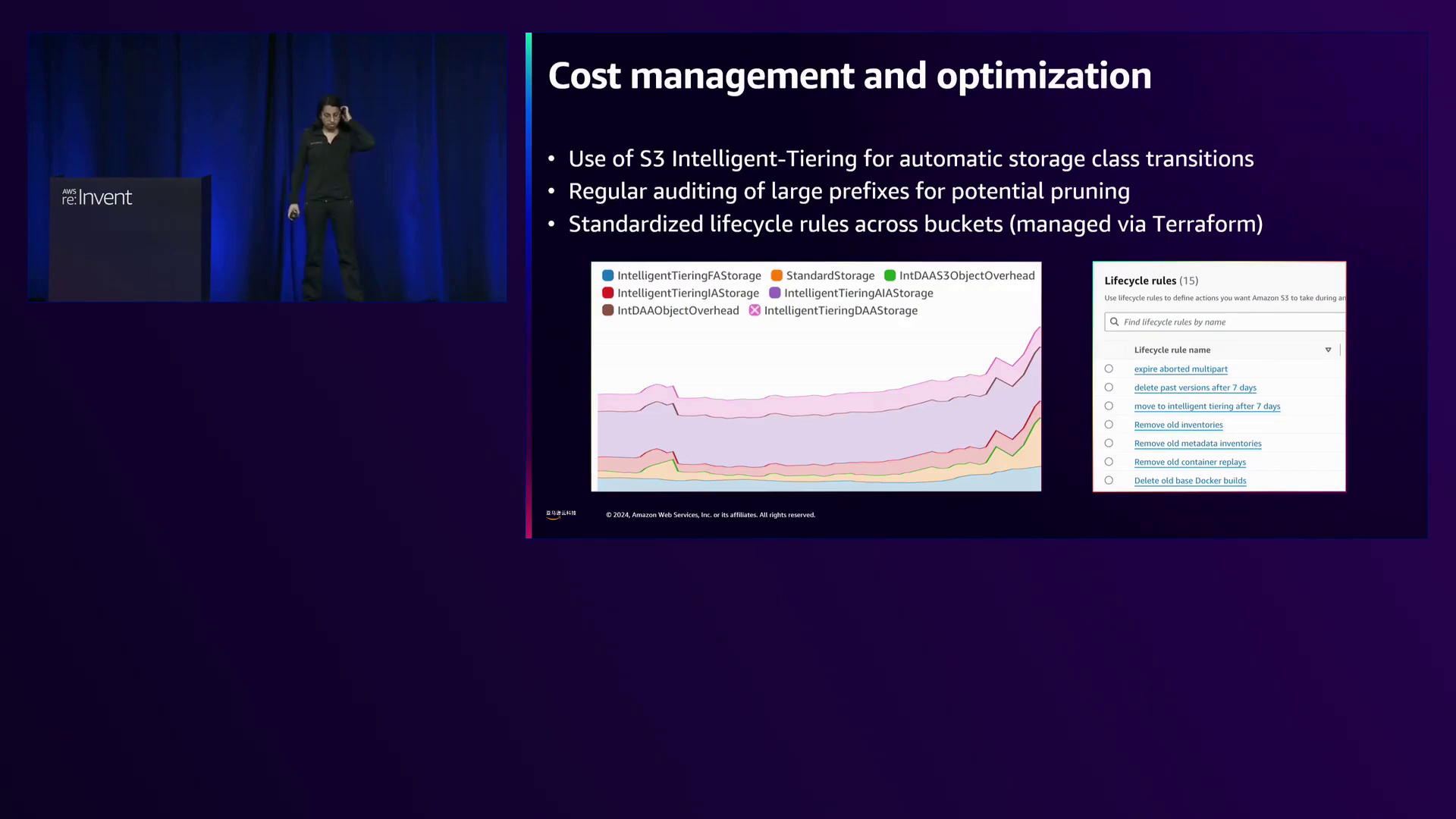
Kutsey强调了规模的重要性,表示亚马逊云科技团队一直专注于确保存储服务能够无缝处理从数百万到数十亿对象的扩展,而无需客户付出大量努力。他举例说明S3 Intelligent-Tiering可根据访问模式的变化自动在访问层之间移动数据,在工作负载从千兆字节扩展到兆兆字节时优化成本,无需人工干预或在成本和性能之间权衡。
来自Canva的Josh Smith深入探讨了该公司的信任和安全举措。他透露Canva拥有超过2亿月活跃用户,他们已创建超过300亿个设计,导致存储在S3中的内容爆炸式增长,达到300多PB的数据量,这带来了工程挑战。
为确保Canva为包括独立内容创作者、非营利组织、教育机构和企业在内的多元化用户群体提供安全的平台,Smith强调内容审核的重要性。Canva采用集中式审核平台,与包括Amazon Rekognition在内的各种服务挂钩,以检测和缓解不安全内容。值得注意的是,Canva每天通过Rekognition单独进行约7000万次内容检查。
然而,Smith警告说,模型只能提供置信度水平,而不能保证,在某些情况下仍需要人工审核员。此外,用户经常直接报告可疑内容,有时会发现类似内容的集群,需要进一步调查。
为此,Canva开发了内部工具用于内容审查和标记,包括使用感知哈希识别相似内容的系统。Smith举了一个例子,展示了他的狗的两张视觉相似的图像,一张狗鼻子上有一个绿点,由于这一细微变化,两张图像的MD5哈希值差异巨大。相比之下,感知哈希产生的哈希值之间只有小距离(在这种情况下,差异仅两个字符),从而能够有效识别相似内容。
为了扩展这种方法,Canva实现了一种将感知哈希分块并存储在DynamoDB中的算法,只需一个简单的GetItem调用即可高效检索相似图像。Smith指出,虽然块数是一个可调参数(更多块需要更多DynamoDB查询),但他们最初块数过多,需要进行优化。
在信任方面,Smith透露Canva的立场是赋予用户对其数据使用和同意做出决定的权力。尊重用户偏好并遵守GDPR和COPPA等法规对于维护信任至关重要。为此,Canva开发了ML数据集服务,该服务与存储法律规则的隐私偏好服务相连接,用于数据处理。
ML数据集服务根据用户同意和法律要求,从媒体、视频和文档服务等源服务中联合策划数据集。这种方法确保数据科学家可以专注于自己的任务,而无需担心隐私合规性,因为该服务会在偏好或法规发生变化时自动刷新数据集。
来自Bria AI的Barr Fingerman讨论了他们用于从许可数据训练大型视觉基础模型的“基础模型机器”。他透露,人工智能开发人员通常会花费50-60%的时间进行内容审核、数据策划、处理幻觉和后处理,以防止模型出现问题。
Bria AI与Getty和Vato Alami等数据提供商合作,获取不含亵渎、商标和其他问题的经过许可的高质量数据,为模型提供坚实的基线。然而,Fingerman承认,模型可能仍然难以掌握某些概念,例如在没有明确训练品牌的情况下生成一款品牌“Nike”的鞋子。
为了处理PB级的多模态数据,Bria AI使用超过1000个GPU实例(在亚马逊云科技 G5实例上的NVIDIA A10 GPU)构建了数据管道。这些管道采用专有算法,包括多模态LLM和计算机视觉分类器,从图像和视频中提取见解,然后插入数据目录。
Bria AI的数据目录利用Amazon Glue、Athena和Iceberg表,实现高效查询和分析。Fingerman强调了Iceberg表的优势,如表格式化、分区以加快查询速度,以及在更新算法或分类器时可无缝回滚的能力。
Fingerman举例说明如何查询目录,例如查找具有特定纵横比、美学评分的图像,或排除透明背景以用于模型训练。他还演示了如何使用感知哈希识别并删除来自不同数据提供商的重复图像。
对于视频模型训练,Bria AI评估了“情感评分”指标,以识别具有显著运动的视频,这对于学习帧之间的过渡函数至关重要。通过随机抽样不同评分区间的1000个视频,他们校准了理想的情感评分阈值。
转向模型训练,Fingerman透露Bria AI利用大量NVIDIA H100 GPU,有些模型需要在PB级数据上训练数周或数月。为优化性能,他们采用了分而治之的方法,在更便宜的G5实例上预计算操作,然后使用S3的快速文件模式通过SageMaker将数据流式传输到训练集群。
这种方法实现了4倍的成本降低和加速,通过将计算卸载到更便宜的GPU并避免使用外部存储或共享文件系统。训练集群中的每个GPU都作为独立单元运行,提前获取指定的数据分片,以实现最佳收敛。
对于归属和版税支付,Bria AI采用与其数据目录相同的Iceberg表和Athena架构。Fingerman展示了一个显示归属记录的Web应用程序,揭示对于单个图像模型,他们在去年alone累积了超过20亿条归属记录,预计到2024-2025年,随着规模扩大,这一数字将增长十倍。
来自Anthropic的Nuvadha Sarma强调该公司广泛使用Amazon S3,每两周就会处理200PB的数据集(相当于230英里高的DVD堆叠)用于他们最新的模型。以前,他们曾面临每周长达一周的数据处理周期,但通过优化,现在只需一两天即可处理这些海量数据集。
Sarma强调Anthropic致力于避免在数据处理方面做出任何妥协,不像其他方法那样对数据进行分片或为了效率而牺牲数据完整性。这种不折不扣的态度使他们能够在保持数据完整性的同时实现规模扩展。
对于高性能I/O操作(如洗牌),Anthropic利用S3 Express One Zone,允许他们根据需要执行任意数量的IOPS,不受Hadoop、EBS或EFS等共享文件系统的限制。跨区域存储桶复制使他们能够将数据与不同区域的计算资源放在一起,而网关端点有助于降低数据传输成本。
对于Anthropic那些在训练后很少访问但体积庞大的大型语言模型检查点,S3 Intelligent-Tiering在管理成本方面发挥了关键作用。Intelligent-Tiering可自动将不常访问的数据降级,从而优化存储成本,无需人工干预。
Sarma深入探讨了Anthropic针对模型检查点优化的S3键结构,旨在平衡用户友好性和S3性能。Metadata遵循标准文件系统结构,而检查点采用反向键结构,前缀包括运行类型、运行名称、检查点类型和检查点编号。这种方法将写入分散到多个热前缀,避免性能瓶颈和503错误。
Anthropic利用S3的存储弹性,根据工作负载需求动态扩展和缩减IOPS,避免过度配置成本。Sarma透露,他们可以在单个区域内维持1500GB/秒的出口速率,这一速度足以在不到一秒钟内传输整个Netflix目录,或在不到30秒内传输国会图书馆的全部内容。
为优化吞吐量,Anthropic使用亚马逊云科技通用运行时(CRT) S3客户端,相比为每个操作创建新连接,它提供了更好的连接管理并分摊了TLS启动成本。同时还采用了异步I/O,提前将数据排入队列,隐藏延迟抖动并确保向计算资源提供稳定的数据流。
Anthropic的数据策略专注于全面的全球去重策略,这得益于S3的高性能能力。与可能在分片边界丢失数据的分片方法不同,全球去重(包括针对文本数据的语义去重技术)通过考虑整个数据集可以获得更好的结果。
对于图像和视频等多模态数据,由于文件尺寸较大而带来挑战,Anthropic依赖及时数据准备,将大量文件存储在S3中,并利用其性能按需检索和处理这些文件,无需复杂的预处理管道。
Sarma还讨论了Anthropic管理模型检查点的方法,利用S3库存报告驱动一个基于需要它们的指数可能性随时间推移而删除检查点的过程,从而节省成本。这种分层检查点系统包括临时检查点(30天后删除)、周期性快照(每x个token存储一次)和永久快照(随着运行进行而指数存储)。
总之,本次会议展示了Canva、Bria AI和Anthropic如何利用亚马逊S3等亚马逊云科技存储服务推动创新的边界。从在尊重隐私偏好的同时策划高质量数据,到优化大规模存储性能并构建高效数据管道,这些公司展示了亚马逊云科技解决方案在开启数据驱动创新的新前景方面的变革潜力。
下面是一些演讲现场的精彩瞬间:
Andrew Kutsey是亚马逊S3的产品经理,他自我介绍并主持本次会议。

会议邀请了来自Canva、Briai和Anthropic的嘉宾,探讨数据如何推动创新。
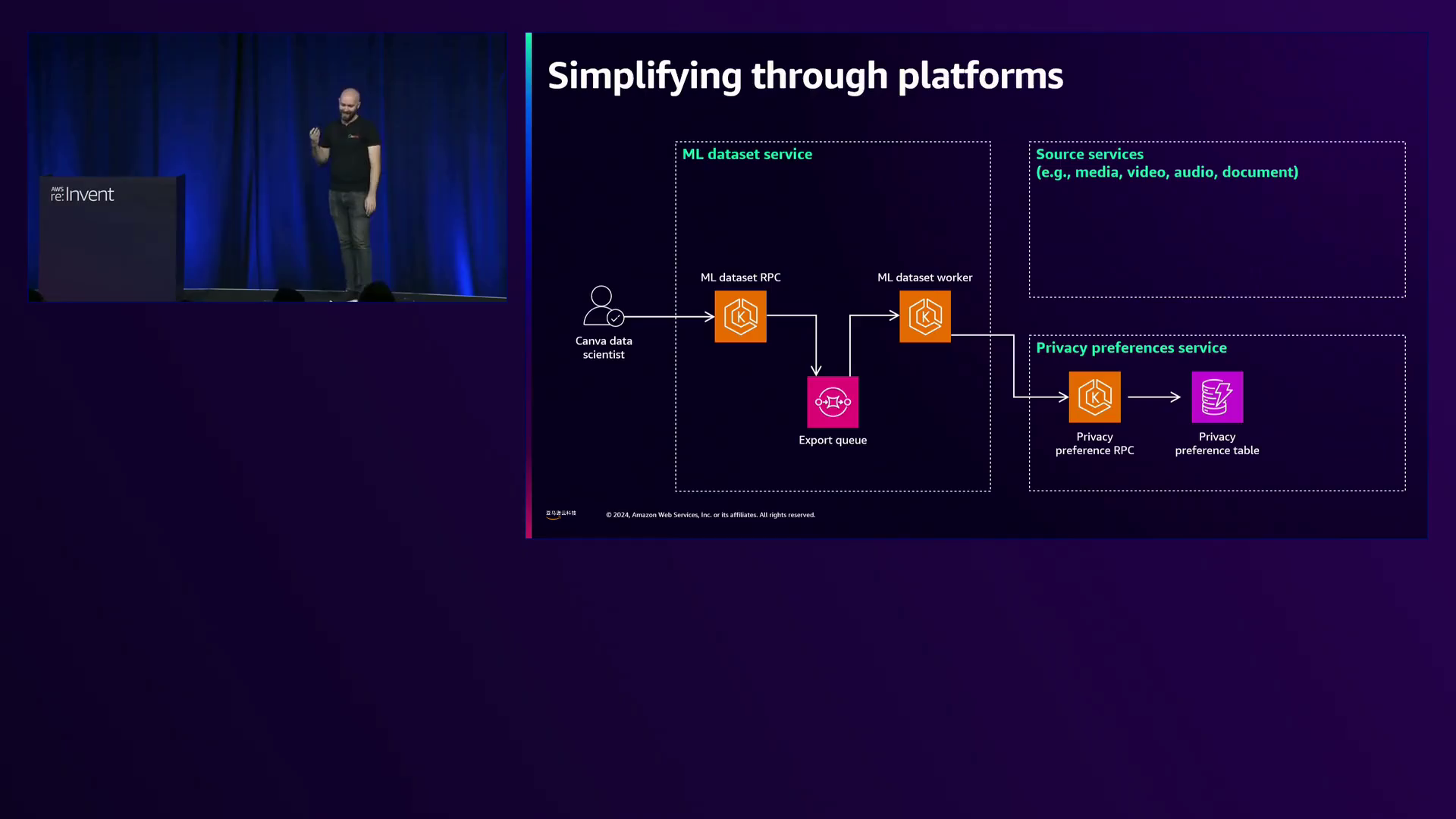
亚马逊云科技机器学习数据集服务通过从各种来源联合数据、根据用户同意和法律要求进行过滤,并在偏好或法规发生变化时刷新数据集,确保了数据隐私和合规性,让数据科学家能够专注于机器学习任务。

亚马逊每两周处理大约200PB的大型数据集,相当于230英里高的DVD堆叠,展示了其运营的惊人规模。

亚马逊优化了S3结构,用于存储模型检查点,在用户友好的文件系统结构和高效的S3操作之间取得平衡,实现了大规模模型训练和恢复的顺畅过程。
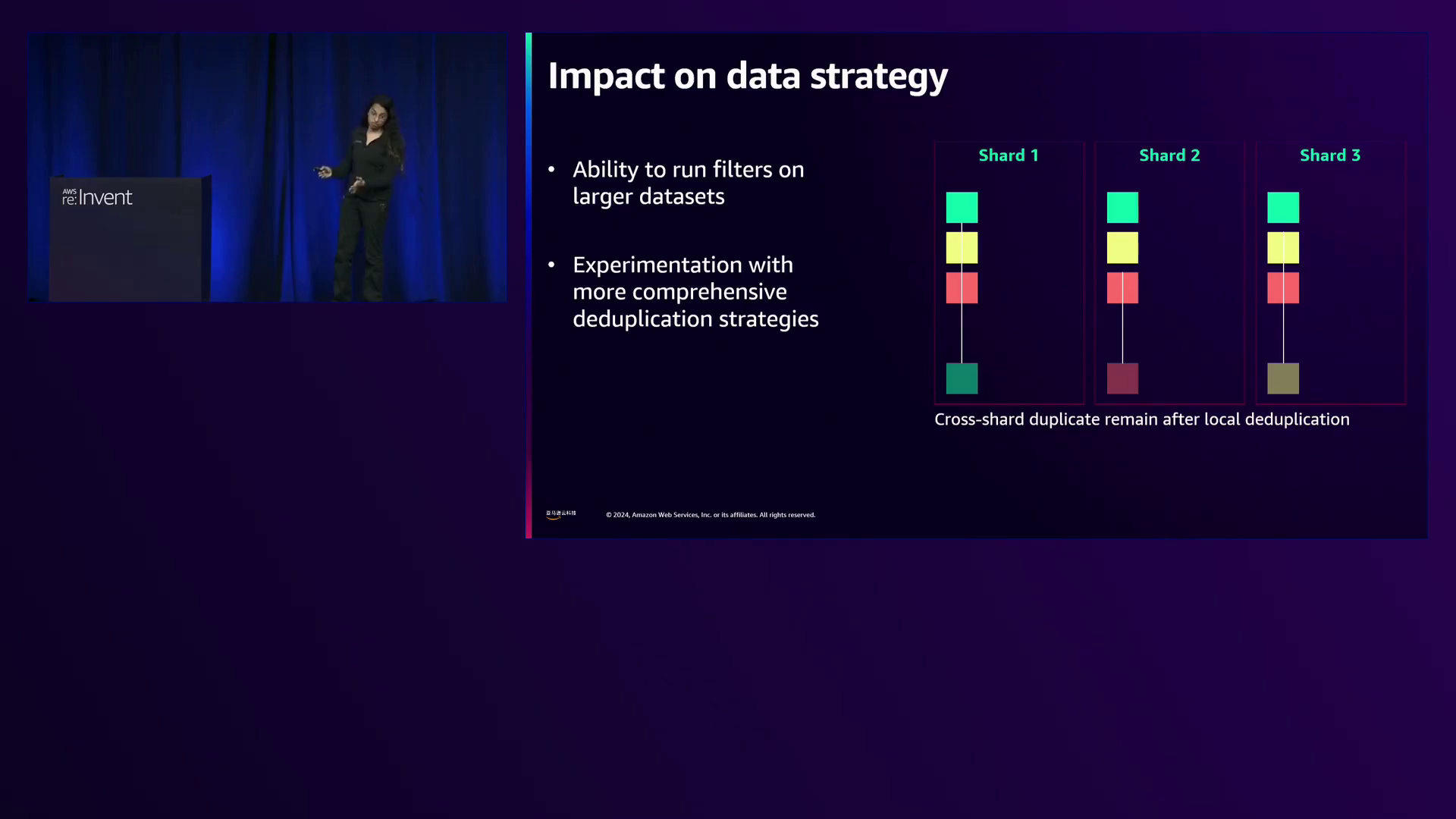
强调了全局去重对于有效的数据扩展和改进模型性能的重要性,同时强调了分片级别重复的挑战和语义重复技术的好处。
总结
在这个引人入胜的叙述中,我们深入探讨了在亚马逊云科技领域内数据管理、性能优化和可扩展性的错综复杂世界。这一旅程始于Andrew Kutsey——亚马逊S3的产品经理,他介绍了本次会议的核心主题:数据质量、存储性能和弹性可扩展性。
来自Canva的Josh Smith阐明了他们确保数据可信赖性和安全性的方法。他揭示了Canva的内容审核平台,利用了亚马逊Rekognition等亚马逊云科技服务,以及他们创新的ML数据集服务,该服务在为训练模型策划数据的同时尊重用户的隐私偏好。
来自Bria AI的Barr Fingerman展示了他们的“基础模型机器”,这是一个强大的基础设施,用于摄取数百万亿字节的授权数据、从头开始训练基础模型,并向数据提供商支付版税。他强调了亚马逊云科技服务(如EKS、S3、Glue和Athena)在简化数据管道、编目和版权归属跟踪方面的关键作用。
来自Anthropic的Nuvadha Sarma分享了他们令人惊叹的旅程,每两周处理200PB的数据,用于训练前沿语言模型。他重点介绍了亚马逊云科技服务(如S3 Express One Zone、跨存储桶复制和S3智能分层)在实现他们前所未有的规模和性能方面的变革性影响。
在结束语中,演讲者强调了数据管理、隐私合规性和基础设施优化对于发挥人工智能和机器学习创新的全部潜力的至关重要性。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









