



比例数据可视化
【实验名称】绘制板块层级图
【实验目的】
1.掌握数据文件读取
2.掌握数据处理的方法
3. 实现板块层级图的绘制
【实验原理】
板块层级图(treemap)是一种基于面积的可视化方式,通过每一个板块(通常为矩形)的尺寸大小进行度量。外部矩形代表父类别,而内部矩形代表子类别。我们也可以通过板块层级图简单的呈现比例关系,不过它更擅于呈现树状结构的数据。
读取绘图所用的数据,并对数据进行处理将数据处理成我们可以使用的形式,绘制板块层级图,设置标签和标题。
【实验环境】
OS:win11
python:v3.13
【实验步骤】
一、安装所需库
1、输入命令:pip install pandas

2、输入命令:pip install matplotlib

3.输入命令:pip install seabor

4.输入命令:pip install squarify

二、读取数据
在这里我们使用pandas库中的read_csv函数来读取这3个数据文件。

三、数据处理
我们需要根据源表对目标表进行匹配查询,使用 merge 函数进行操作。

原代码版本老旧,不适应目前版本。
加入了判断条件,使得确保在合并前的必要列存在
# 确保在合并前的必要列存在
if 'aisle_id' not in aisles_df.columns:
raise ValueError("aisles_df 中缺少 'aisle_id' 列。")
if 'department_id' not in departments_df.columns:
raise ValueError("departments_df 中缺少 'department_id' 列。")
# 合并数据框
order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left')
order_products_prior_df = pd.merge(order_products_prior_df, departments_df, on='department_id', how='left')
# 创建临时数据框
temp = order_products_prior_df[['product_name', 'aisle', 'department']]
temp = pd.concat([
order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'),
order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department')
], axis=1).reset_index()
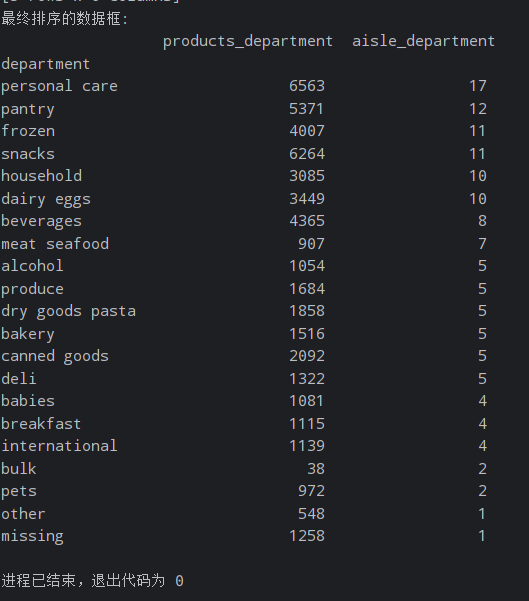
实现结果:
四、绘制板块层级图

上述参考代码使用了viridis色图进行渲染,由于我的版本于现在不兼容,故做出了一系列修改,即使用 plasma 色图来完成该操作:
# 设置颜色映射
cmap = matplotlib.cm.plasma # 使用 'plasma' 色图
mini, maxi = temp2.products_department.min(), temp2.products_department.max()
norm = matplotlib.colors.Normalize(vmin=mini, vmax=maxi)
# 获取颜色列表
colors = [cmap(norm(value)) for value in temp2.products_department]
colors[0] = "#4F5B93" # 使用有效的颜色代码
# 创建标签
labels = [
"%s\n%d aisle num\n%d products num" % (label, aisle_num, product_num)
for label, aisle_num, product_num in zip(temp2.index, temp2.aisle_department, temp2.products_department)
]
# 创建图形
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, aspect="equal")
# 绘制矩形图
squarify.plot(
temp2.aisle_department,
color=colors,
label=labels,
ax=ax,
alpha=0.7
)
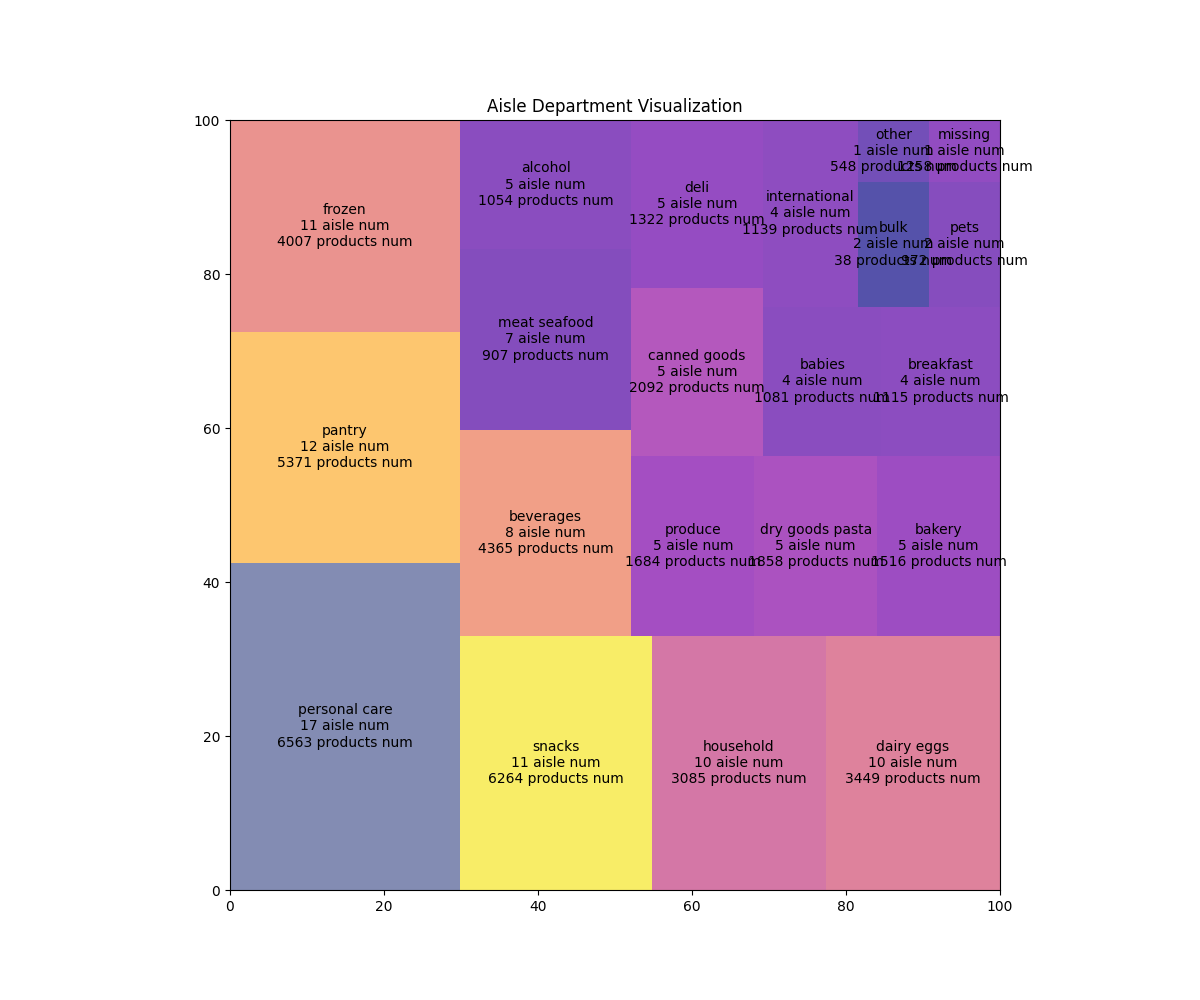
运行结果:
设置 x、y 轴的属性
# 添加图表标题
fig.suptitle("How are aisles organized within departments", fontsize=20)
# 添加数据标签
img = plt.imshow([temp2.products_department], cmap=cmap)
img.set_visible(False) # 隐藏对于imshow的原始图
fig.colorbar(img, orientation="vertical", shrink=0.96) # 添加颜色条
fig.text(0.76, 0.9, 'numbers of products', fontsize=14) # 添加说明文本
# 添加标题
plt.title("Aisle Department Visualization")
plt.show()
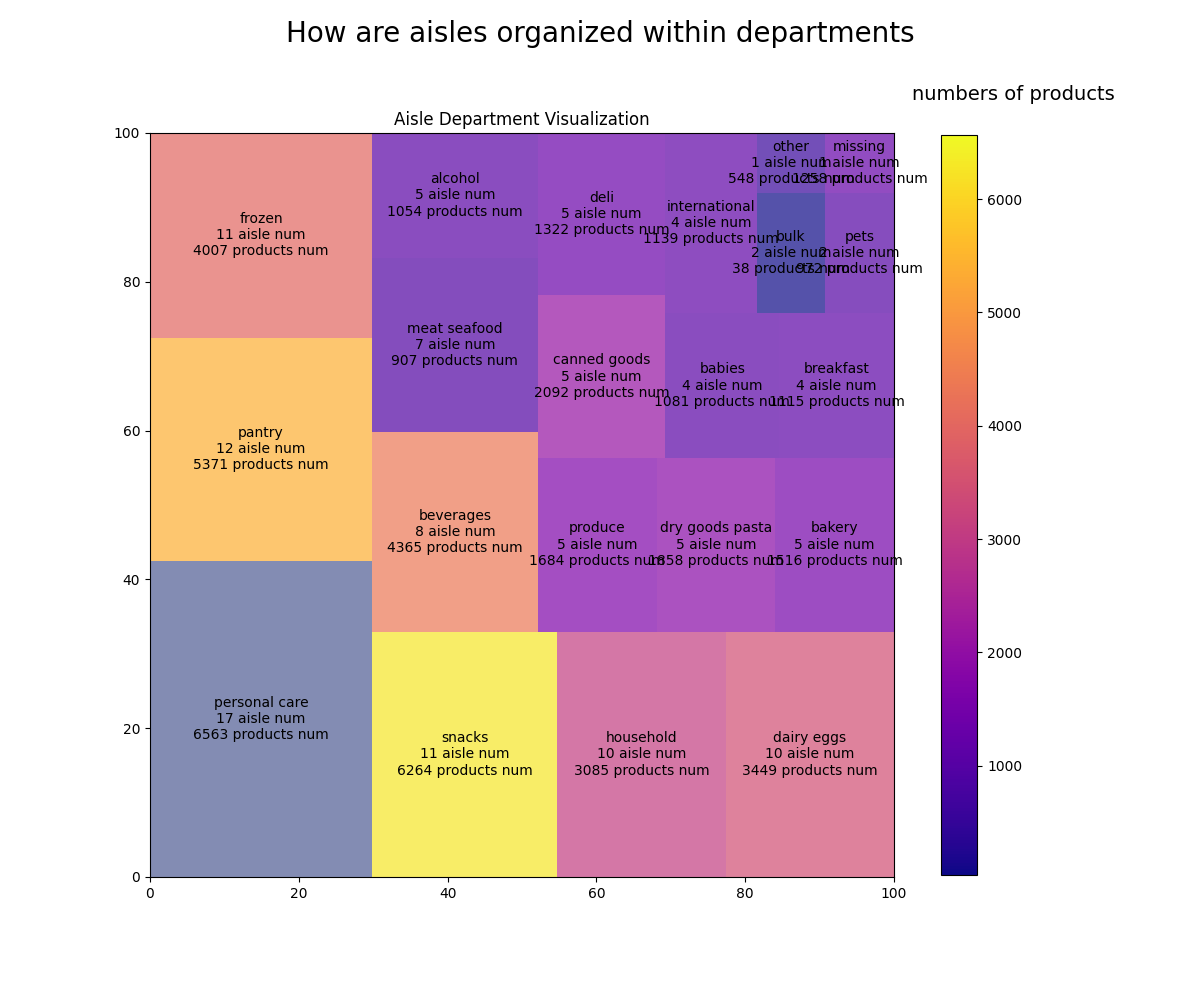
板块层级图效果如下:
完整代码实现:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import squarify
# 加载数据框(请根据自己的文件路径修改)
departments_df = pd.read_csv("E:\\technology\\The_fourth_theaper\\departments.csv")
aisles_df = pd.read_csv("E:\\technology\\The_fourth_theaper\\aisles.csv")
products_df = pd.read_csv("E:\\technology\\The_fourth_theaper\\products.csv")
# 确保在合并前的必要列存在
if 'aisle_id' not in aisles_df.columns:
raise ValueError("aisles_df 中缺少 'aisle_id' 列。")
if 'department_id' not in departments_df.columns:
raise ValueError("departments_df 中缺少 'department_id' 列。")
# 合并数据框
order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left')
order_products_prior_df = pd.merge(order_products_prior_df, departments_df, on='department_id', how='left')
# 创建临时数据框
temp = order_products_prior_df[['product_name', 'aisle', 'department']]
temp = pd.concat([
order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'),
order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department')
], axis=1).reset_index()
# 设置索引为部门
temp = temp.set_index('department')
# 按 'aisle_department' 降序排序
temp2 = temp.sort_values(by='aisle_department', ascending=False)
# 设置颜色映射
cmap = matplotlib.cm.plasma # 使用 'plasma' 色图
mini, maxi = temp2.products_department.min(), temp2.products_department.max()
norm = matplotlib.colors.Normalize(vmin=mini, vmax=maxi)
# 获取颜色列表
colors = [cmap(norm(value)) for value in temp2.products_department]
colors[0] = "#4F5B93" # 使用有效的颜色代码
# 创建标签
labels = [
"%s\n%d aisle num\n%d products num" % (label, aisle_num, product_num)
for label, aisle_num, product_num in zip(temp2.index, temp2.aisle_department, temp2.products_department)
]
# 创建图形
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, aspect="equal")
# 绘制矩形图
squarify.plot(
temp2.aisle_department,
color=colors,
label=labels,
ax=ax,
alpha=0.7
)
# 添加图表标题
fig.suptitle("How are aisles organized within departments", fontsize=20)
# 添加数据标签
img = plt.imshow([temp2.products_department], cmap=cmap)
img.set_visible(False) # 隐藏对于imshow的原始图
fig.colorbar(img, orientation="vertical", shrink=0.96) # 添加颜色条
fig.text(0.76, 0.9, 'numbers of products', fontsize=14) # 添加说明文本
# 添加标题
plt.title("Aisle Department Visualization")
plt.show()
【实验总结】
环境准备
我首先在Windows 11上安装了Python 3.13,并通过命令行安装了所需的库,包括pandas、matplotlib、seaborn和squarify。这一步比较顺利,没有遇到重复安装或者版本冲突的问题。
数据读取
使用pandas的read_csv函数,我读取了三个数据文件(departments、aisles和products)。在这一过程中,我掌握了如何通过正确的方式加载不同的数据集,为后续的数据处理打下了基础。
数据处理
我使用merge函数将产品数据与类别进行匹配。这一阶段遇到的一个问题是,初始代码因为使用了老旧的版本而导致某些列名找不到。因此,我加入了判断条件,确保在合并前必要的列确实存在。这一措施极大地减少了可能出现的错误,增强了代码的鲁棒性。
绘制板块层级图
在最后一步,我使用matplotlib和squarify绘制了一个层级图。由于我的版本与参考代码中使用的色图不兼容,我选择了修改为plasma色图。这一阶段让我学会了如何根据数据的特征自定义可视化效果。在图形中,我成功展示了不同类别和产品数量的关系。
遇到的问题与解决办法
数据合并错误:如前所述,初始代码的兼容性问题导致无法找到某些列。为此,我进行了代码更新,加入了列存在性的检查,以确保数据合并能够顺利进行。
可视化效果不佳:最开始的色图不适合我的数据版本,经过修改后使用了plasma色图,这改善了视觉效果并使得数据的呈现更加清晰。
收获与总结
通过这个实验,我不仅学习到如何处理和可视化数据,还掌握了调试程序和解决问题的方法。我意识到在数据分析的过程中,细节至关重要,尤其是数据结构的了解和确保数据完整性。同时,这次实验增强了我在数据处理中解决实际问题的能力,也让我更深入地理解了数据可视化的重要性和实用性。

















 3853
3853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









