




3.1.1 从 N-gram 到 RNN (续)
(3) 循环神经网络 (RNN) 与长短时记忆网络 (LSTM)
前一节的神经网络语言模型虽然引入了词嵌入解决了泛化问题,但它和 N-gram 模型一样,上下文窗口是固定大小的。为了预测下一个词,它只能看到前 n−1n-1n−1 个词,再早的历史信息就被丢弃了。这显然不符合我们人类理解语言的方式。
为了打破固定窗口的限制,循环神经网络 (Recurrent Neural Network, RNN) 应运而生,其核心思想非常直观:为网络增加“记忆”能力 。
RNN 的工作原理
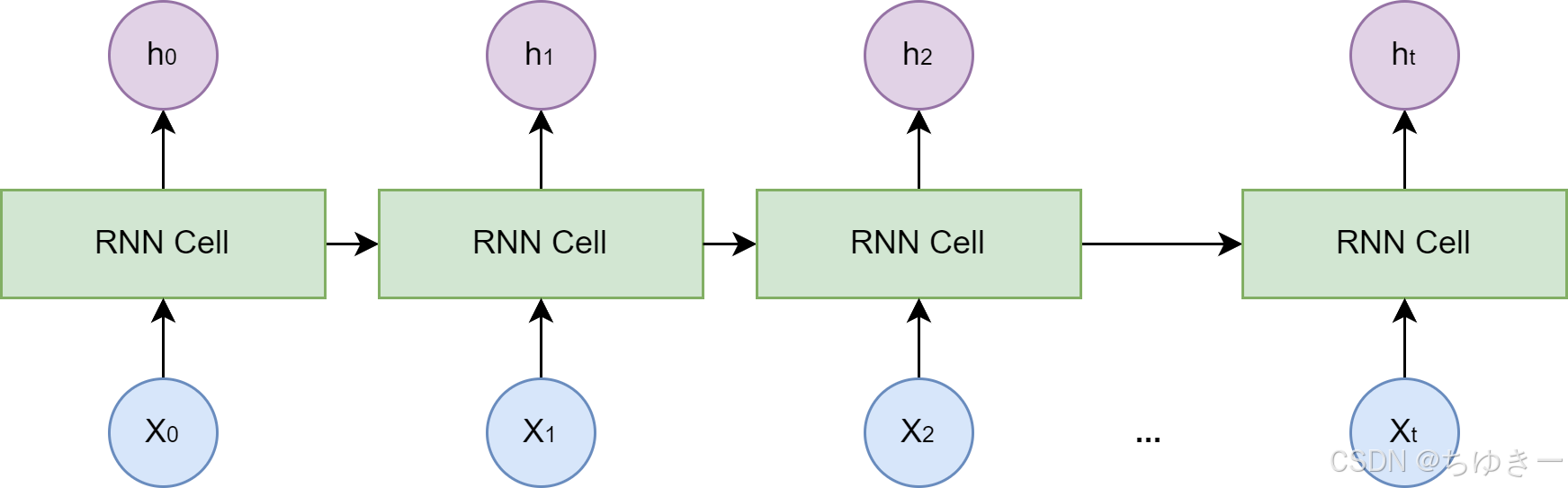
RNN 的设计引入了一个隐藏状态 (hidden state) 向量,我们可以将其理解为网络的短期记忆。
在处理序列的每一步,网络都会:
-
读取当前的输入词。
-
结合它上一刻的记忆(即上一个时间步的隐藏状态)。
-
生成一个新的记忆(即当前时间步的隐藏状态)传递给下一刻。
这个循环往复的过程,使得信息可以在序列中不断向后传递 。
长期依赖问题 (Long-term Dependency Problem)
然而,标准的 RNN 在实践中存在一个严重的问题。在训练过程中,模型需要通过反向传播算法根据输出端的误差来调整网络深处的权重。对于 RNN 而言,序列的长度就是网络的深度。
当序列很长时,梯度在从后向前传播的过程中会经过多次连乘,这会导致梯度值:
-
快速趋向于零 (梯度消失):模型无法有效学习到序列早期信息对后期输出的影响。
-
变得极大 (梯度爆炸)。
这意味着 RNN 难以捕捉长距离的依赖关系 。
LSTM:为记忆加把锁
为了解决长期依赖问题,长短时记忆网络 (Long Short-Term Memory, LSTM) 被设计出来 。
LSTM 是一种特殊的 RNN,其核心创新在于引入了细胞状态 (Cell State) 和一套精密的门控机制 (Gating Mechanism)。
-
细胞状态:可以看作是一条独立于隐藏状态的信息通路,允许信息在时间步之间更顺畅地传递。
-
门控机制:由几个小型神经网络构成,学习如何有选择地让信息通过。
这些门包括:
-
遗忘门 (Forget Gate):决定从上一时刻的细胞状态中丢弃哪些信息 。
-
输入门 (Input Gate):决定将当前输入中的哪些新信息存入细胞状态 。
-
输出门 (Output Gate):决定根据当前的细胞状态,输出哪些信息到隐藏状态 。
3.1.2 Transformer 架构解析
RNN 及 LSTM 通过引入循环结构来处理序列数据,这在一定程度上解决了捕捉长距离依赖的问题。然而,这种循环的计算方式也带来了新的瓶颈:它必须按顺序处理数据。
第 ttt 个时间步的计算,必须等待第 t−1t-1t−1 个时间步完成后才能开始。这意味着 RNN 无法进行大规模的并行计算,在处理长序列时效率低下,这极大地限制了模型规模和训练速度的提升 。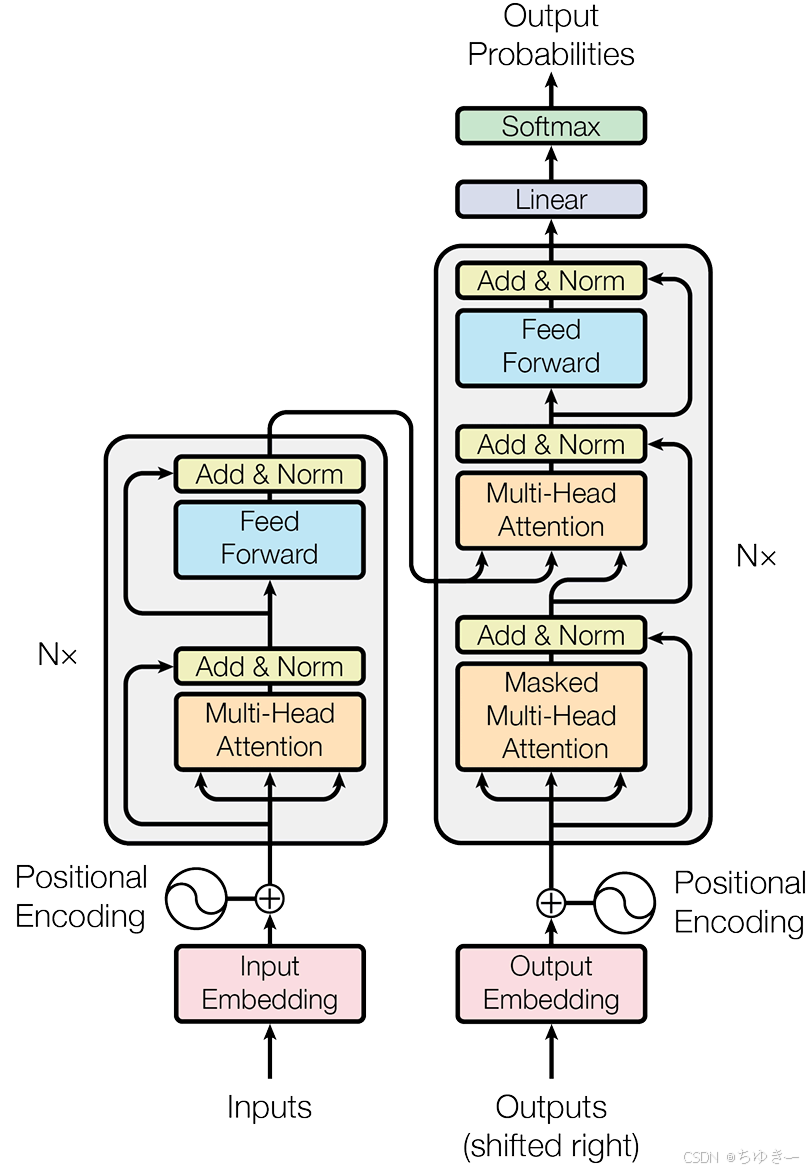
Transformer 在 2017 年由谷歌团队提出。它完全抛弃了循环结构,转而完全依赖一种名为注意力 (Attention) 的机制来捕捉序列内的依赖关系,从而实现了真正意义上的并行计算。
(1) Encoder-Decoder 整体结构
最初的 Transformer 模型是为端到端任务(如机器翻译)而设计的。在宏观上,它遵循了一个经典的 编码器-解码器 (Encoder-Decoder) 架构 。
我们可以将这个结构理解为一个分工明确的团队
-
编码器 (Encoder):任务是“理解”输入的整个句子。它会读取所有输入词元,最终为每个词元生成一个富含上下文信息的向量表示。
-
解码器 (Decoder):任务是“生成”目标句子。它会参考自己已经生成的前文,并“咨询”编码器的理解结果,来生成下一个词。
动手实现 Transformer:搭建骨架
为了真正理解 Transformer 的工作原理,最好的方法莫过于亲手实现它。我们将采用一种“自顶向下”的方法:首先搭建出 Transformer 完整的代码框架,定义好所有需要的类和方法,然后像拼图一样逐一实现细节。
以下是基于 PyTorch 的 Transformer 核心骨架代码:
import torch
import torch.nn as nn
import math
# --- 占位符模块,将在后续小节中实现 ---
class PositionalEncoding(nn.Module):
"""位置编码模块"""
def forward(self, x):
pass
class MultiHeadAttention(nn.Module):
"""多头注意力机制模块"""
def forward(self, query, key, value, mask):
pass
class PositionwiseFeedForward(nn.Module):
"""位置前馈网络模块"""
def forward(self, x):
pass
# --- 编码器核心层 ---
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention() # 待实现
self.feed_forward = PositionwiseFeedForward() # 待实现
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 1. 多头自注意力
# 残差连接与层归一化将在后续详细解释
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
# --- 解码器核心层 ---
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention() # 待实现:对自己
self.cross_attn = MultiHeadAttention() # 待实现:对编码器输出
self.feed_forward = PositionwiseFeedForward() # 待实现
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 1. 掩码多头自注意力 (对自己)
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 交叉注意力 (对编码器输出)
# 注意:这里 Query 来自解码器(x),Key 和 Value 来自编码器输出(encoder_output)
cross_attn_output = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
# 3. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
💡 注解:
观察 EncoderLayer 和 DecoderLayer 的 forward 函数,你会发现 Transformer 的层级结构非常标准:Attention -> Add & Norm -> FeedForward -> Add & Norm。
唯一的区别在于解码器多了一个 Cross-Attention 层,这正是它“咨询”编码器信息的地方。

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









