



以下从代码整体架构出发,拆解书写步骤,并对关键代码做详细解释,帮你理解如何一步步实现 “基于 OpenCV Haar + MediaPipe 的人脸情绪检测” 功能:


一、书写步骤拆解
1. 环境与依赖准备(前置思考)
- 确定需求:要用 OpenCV 做摄像头采集、人脸检测,MediaPipe 提取关键点,Pillow 处理中文绘制,所以需要导入这些库。
- 提前安装依赖:pip install opencv-python mediapipe pillow numpy ,确保代码运行环境就绪。
2. 基础工具函数编写
- 中文字体适配(get_chinese_font 函数):
不同系统中文字体路径不同,通过遍历常见路径,优先加载本地中文字体(如 simhei.ttf ),找不到则用默认字体兜底,保证中文标签能正常显示。
- 中文绘制逻辑(Chinese_plot_box 函数):
把 OpenCV 的 BGR 图像转成 Pillow 支持的 RGB 格式,用 ImageDraw 绘制带中文标签的矩形框,解决 OpenCV 原生对中文支持差的问题。
3. 核心功能类设计(face_emotion 类)
- 初始化(__init__ 方法):
打开摄像头并设置分辨率,初始化 MediaPipe 人脸网格模型、OpenCV Haar 级联检测器,定义截图计数器,还维护了 MediaPipe 到 dlib 关键点的映射(虽然后续简化了映射逻辑,但保留了扩展思路 )。
- 关键点转换(get_dlib_style_landmarks 方法):
从 MediaPipe 468 个关键点里,筛选出情绪识别常用的关键点(嘴唇、眼睛、眉毛区域),转换为类似 dlib 68 点的精简格式,让后续比例计算逻辑更清晰。
- 主逻辑运行(learning_face 方法):
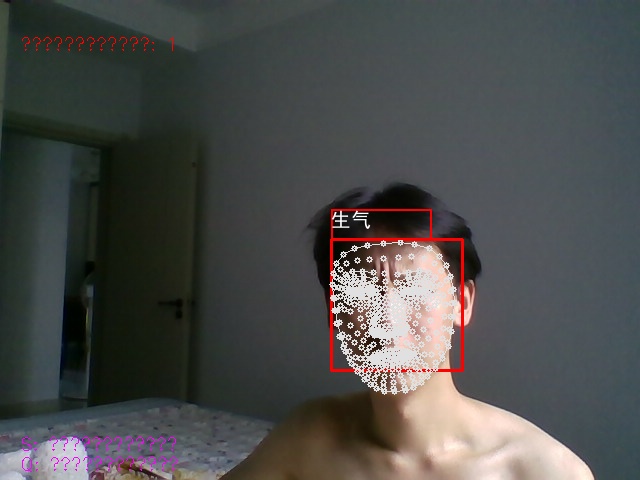
持续从摄像头取帧 → 用 Haar 级联检测人脸 → MediaPipe 提取关键点 → 计算嘴巴、眉毛、眼睛的几何特征 → 根据特征判断情绪 → 绘制结果并提供截图、退出功能。
4. 程序入口(if __name__ == "__main__")
实例化 face_emotion 类并调用 learning_face 方法,启动整个人脸情绪识别流程。
二、关键代码详细解释
1. 中文字体加载(get_chinese_font 函数)
def get_chinese_font(size):
font_paths = [
"./font/simhei.ttf", # 项目目录自定义字体
"/usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc", # Linux 常见字体
"/System/Library/Fonts/PingFang.ttc", # Mac 常见字体
"C:/Windows/Fonts/simhei.ttf" # Windows 常见字体
]
for path in font_paths:
if os.path.exists(path):
return ImageFont.truetype(path, size, encoding="utf-8")
return ImageFont.load_default() # 兜底方案
- 作用:跨平台加载中文字体,避免因系统差异导致中文显示为方框或乱码。
- 逻辑:按优先级遍历字体路径,找到存在的字体就用 ImageFont.truetype 加载;全找不到则返回默认字体(可能无法完美显示中文,但保证程序不崩溃 )。
2. 中文绘制(Chinese_plot_box 函数核心片段)
def Chinese_plot_box(image, label, x, sizes, colour=None, line_thickness=None):
cv2img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # OpenCV → Pillow 格式转换
pilimg = Image.fromarray(cv2img)
draw = ImageDraw.Draw(pilimg)
font = get_chinese_font(sizes) # 拿到合适的中文字体
# 计算矩形框厚度、坐标
tl = line_thickness or round(0.002 * (image.shape[0] + image.shape[1]) / 2) + 1
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
draw.rectangle([int(x[0]), int(x[1]), int(x[2]), int(x[3])], outline=(255, 0, 0), width=tl)
if label:
text_width = draw.textlength(label, font=font) # 计算文本宽度
text_height = font.getbbox(label)[3] - font.getbbox(label)[1] # 计算文本高度
t_size = (text_width, text_height)
# 调整矩形坐标,避免 y 轴方向逻辑错误
rect_x0, rect_y0 = int(x[0]), int(x[1])
rect_x1, rect_y1 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
if rect_y1 < rect_y0:
rect_y1 = rect_y0 # 保证矩形下边界不高于上边界
# 绘制带背景的文本
draw.rectangle([rect_x0, rect_y0, rect_x1, rect_y1],
outline=(255, 0, 0), fill=(255, 0, 0), width=1)
draw.text((rect_x0, rect_y0), label, (255, 255, 255), font=font)
image = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR) # 转回 OpenCV 格式
return image
- 核心目的:在 OpenCV 图像上绘制带中文标签的矩形框,解决 OpenCV putText 对中文支持差的问题。
- 关键细节:
-
- 格式转换:OpenCV 图像是 BGR 通道,Pillow 处理 RGB ,所以需要 cvtColor 转换。
-
- 文本尺寸计算:用 textlength 算宽度,getbbox 算高度(不同 Pillow 版本可能有差异,但逻辑通用 )。
-
- 坐标安全校验:通过 if rect_y1 < rect_y0 避免绘制矩形时出现 “下边界在上边界上方” 的错误。
3. 人脸检测与关键点处理(learning_face 方法核心片段)
def learning_face(self):
while self.cap.isOpened():
flag, im_rd = self.cap.read() # 从摄像头取帧
if not flag:
break
# 1. Haar 级联检测人脸
gray = cv2.cvtColor(im_rd, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
# 2. MediaPipe 提取关键点
rgb_frame = cv2.cvtColor(im_rd, cv2.COLOR_BGR2RGB)
results = face_mesh.process(rgb_frame)
# 3. 处理检测结果(有脸 + 有关键点)
if len(faces) > 0 and results.multi_face_landmarks:
for (x, y, w, h) in faces:
# 绘制人脸框
im_rd = cv2.rectangle(im_rd, (x, y), (x + w, y + h), (0, 0, 255), 2)
self.face_width = w # 记录人脸宽度,用于比例计算
# 遍历关键点,转换格式并计算特征
for face_landmarks in results.multi_face_landmarks:
# 绘制 MediaPipe 关键点(可视化调试用)
mp_drawing.draw_landmarks(
image=im_rd,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=drawing_spec,
connection_drawing_spec=drawing_spec)
# 转换关键点为 [x,y] 列表
landmarks = [(int(lm.x * w), int(lm.y * h))
for lm in face_landmarks.landmark]
# 4. 计算情绪特征(嘴巴、眉毛、眼睛)
# 嘴巴宽高比
mouth_left, mouth_right, mouth_top, mouth_bottom = landmarks[61], landmarks[291], landmarks[13], landmarks[14]
mouth_width = (mouth_right[0] - mouth_left[0]) / self.face_width
mouth_height = (mouth_bottom[1] - mouth_top[1]) / self.face_width
# 眉毛特征(高度、间距、倾斜度)
left_brow, right_brow = [landmarks[244], landmarks[174], landmarks[158], landmarks[157], landmarks[177]], [landmarks[46], landmarks[424], landmarks[413], landmarks[414], landmarks[433]]
brow_sum, frown_sum, line_brow_x, line_brow_y = 0, 0, [], []
for lb, rb in zip(left_brow, right_brow):
brow_sum += (lb[1] - y) + (rb[1] - y)
frown_sum += rb[0] - lb[0]
line_brow_x.extend([lb[0], rb[0]]), line_brow_y.extend([lb[1], rb[1]])
# 眉毛倾斜度计算(最小二乘法拟合直线)
brow_k = 0
if len(line_brow_x) > 1 and len(line_brow_y) > 1:
z1 = np.polyfit(line_brow_x, line_brow_y, 1)
brow_k = -round(z1[0], 3)
# 眼睛睁开程度
left_eye, right_eye = [landmarks[386], landmarks[385], landmarks[384], landmarks[398], landmarks[380], landmarks[374]], [landmarks[159], landmarks[158], landmarks[157], landmarks[173], landmarks[145], landmarks[133]]
eye_sum = 0
for le in left_eye[:3]: # 上眼睑
for le2 in left_eye[3:]: # 下眼睑
eye_sum += le2[1] - le[1]
for re in right_eye[:3]:
for re2 in right_eye[3:]:
eye_sum += re2[1] - re[1]
eye_hight = (eye_sum / 12) / self.face_width
# 5. 情绪判断逻辑
emotion = "自然"
if mouth_height >= 0.03:
emotion = "震惊" if eye_hight >= 0.056 else "高兴"
else:
emotion = "生气" if brow_k <= -0.3 else "自然"
# 6. 绘制结果
cv2.putText(im_rd, emotion, (x, y + h + 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
im_rd = Chinese_plot_box(im_rd, label=emotion,
x=[x, y - 30, x + 100, y], sizes=20)
# 显示人脸数量
cv2.putText(im_rd, f"人脸数量: {len(faces)}", (20, 50),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1)
else:
cv2.putText(im_rd, "未检测到人脸", (20, 50),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1)
# 操作提示、截图、退出逻辑...
cv2.imshow("人脸情绪识别", im_rd)
- 流程拆解:
-
- 取帧与预处理:cap.read() 读摄像头,转灰度图给 Haar 级联,转 RGB 给 MediaPipe。
-
- 人脸与关键点检测:Haar 找人脸框,MediaPipe 提取 468 个关键点,再筛选出情绪相关的精简点。
-
- 特征计算:
-
-
- 嘴巴:通过左右嘴角、上下嘴唇关键点算宽高比,判断是否 “张嘴”。
-
-
-
- 眉毛:统计眉毛关键点的高度和间距,用最小二乘法拟合直线算倾斜度,判断是否 “皱眉 / 挑眉”。
-
-
-
- 眼睛:统计上下眼睑关键点的垂直距离,算睁开程度,区分 “惊讶 / 高兴”。
-
-
- 情绪判断:用多条件分支,结合嘴巴、眉毛、眼睛的特征,输出 “自然、高兴、震惊、生气” 等结果。
-
- 可视化与交互:用 cv2.putText 和 Chinese_plot_box 绘制结果,提供截图(s 键)和退出(q 键)功能。
4. 程序启动(入口代码)
if __name__ == "__main__":
my_face = face_emotion()
my_face.learning_face()
- 作用:Python 脚本标准入口,确保直接运行脚本时才启动人脸情绪识别流程,避免被其他模块导入时意外执行。
三、核心设计思路总结
- 多库协同:用 OpenCV 做基础采集和简单人脸检测,MediaPipe 做高精度关键点提取,Pillow 解决中文绘制,各司其职。
- 兼容与适配:通过字体遍历、坐标校验等逻辑,解决跨平台(Windows/Linux/Mac)和库版本差异问题。
- 简化与扩展:把 MediaPipe 468 点精简为类似 dlib 68 点的格式,既简化计算,又保留了扩展为更复杂情绪识别(如 7 分类)的可能性。
理解这些步骤后,你可以根据实际需求调整:比如优化关键点映射、扩展更多情绪分类(结合机器学习模型 )、或替换更精准的人脸检测模型(如 OpenCV DNN 模型 )。



















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











