import requests#获取数据
from bs4 import BeautifulSoup
import traceback#我本来还下载了一下,后来才发现这个是python基本库
import re
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()#这是对获取网页内容过程中做的一个判断,如果有误则报错,如果无误,顺利运行,一般不用管它
r.encoding = r.apparent_encoding
return r.text
except:
print("getHTMLText函数出错")#这部分代码常常被复用,基本上获取页面信息都用这部分代码
def getStockList(lst, stockURL):#获取股票信息列表,lst是列表保存的列表类型,存储了所有股票的信息,stockURL是获取股票列表的URL网站
html = getHTMLText(stockURL)
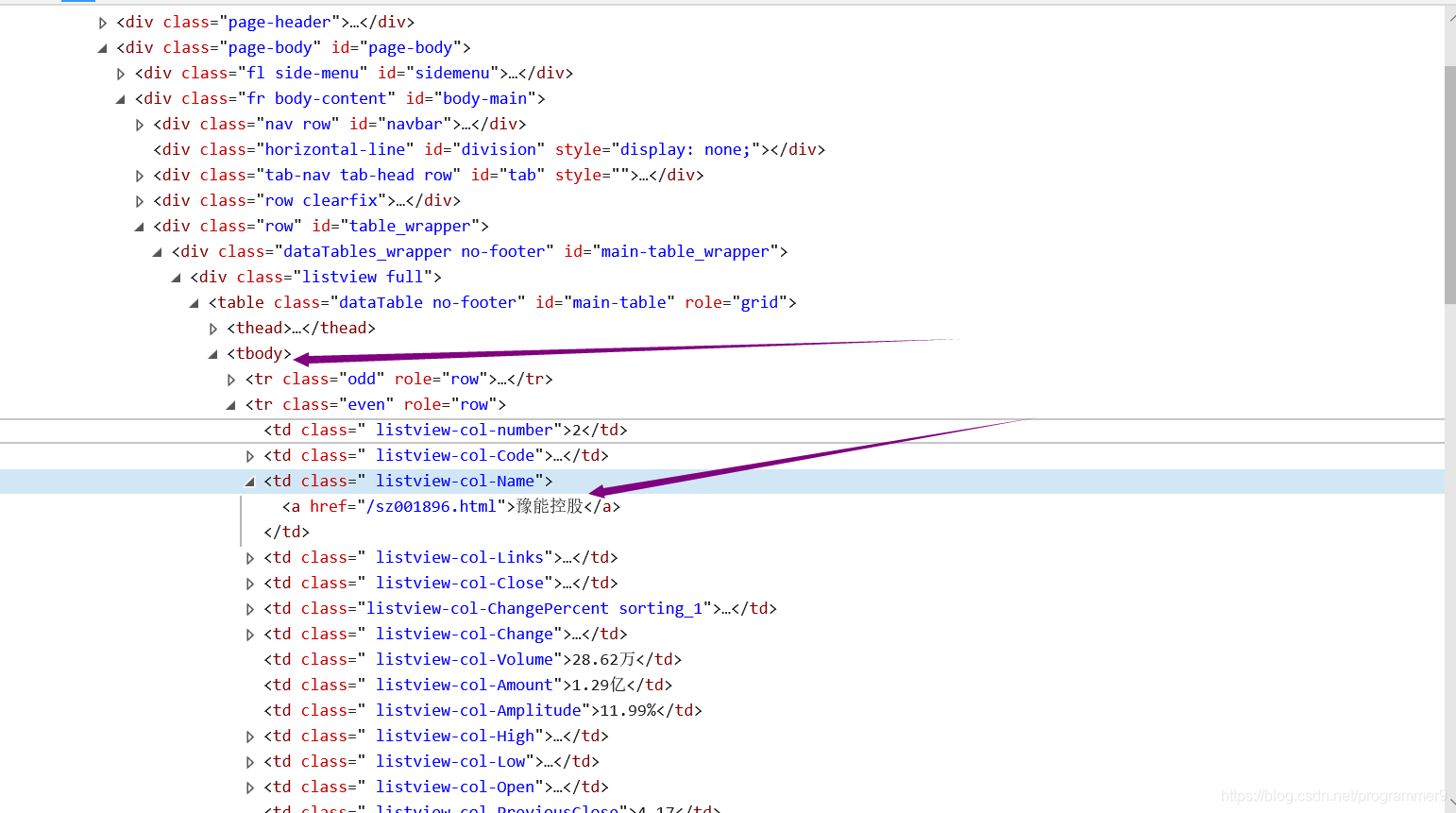
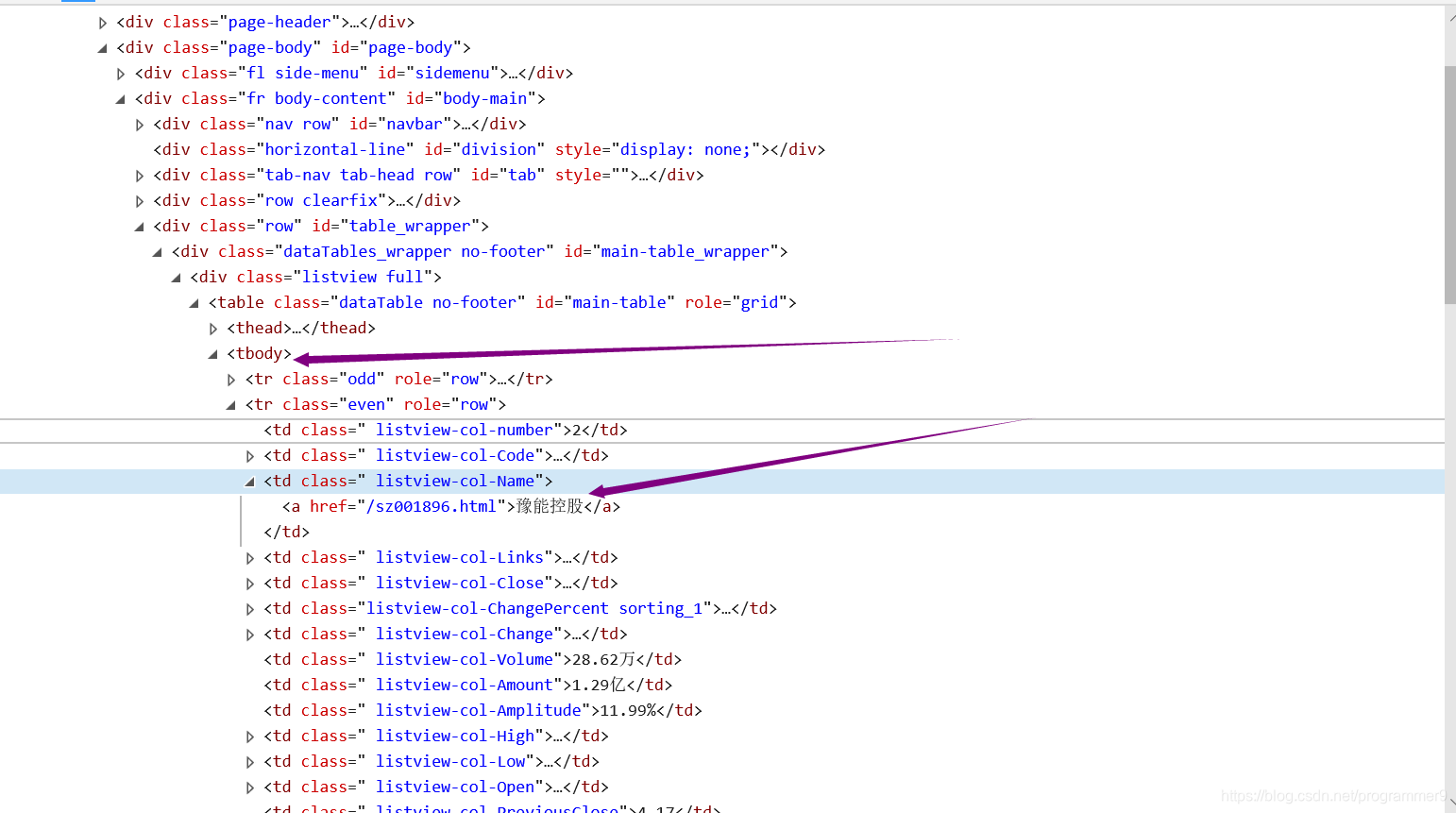
soup = BeautifulSoup(html, "html.parser")#<a href="/sh600448.html">华纺股份</a>这就是从网页源码中提取出的包含股票名称的部分
a = soup.find_all("a")#使用find_all方法找到a标签
for i in a:#遍历
try:
herf = i.attrs["href"]
lst.append(re.findall(r"[s][hz]\d{6}",herf)[0])#上海交易所的代码是以sh开头,深圳交易所的代码则是以sz开头,因此可以用正则表达式
#来从herf中获取股票的信息股票后面的数字是6位
except:
continue#可能会有异常,让程序继续运行就可以了
def getStockInfo(lst, stockURL, fpath):#获得每只股票的信息,并将之存到一个数据结构
#lst是保存所有股票的信息列表,stockURL是获得股票信息的url网站,储存的本地文件路径
for stock in lst:#stock是列表lst里面的内容,
url = stockURL + stock +".html"#https://gupiao.baidu.com/stock/sh601899.html这是紫金矿业的url,我们可以看到,sh代表上海,
#后面六位数则是编号
html = getHTMLText(url)
try:
if html == "":
continue#continue的用处很大嘛
infoDict = {}#我们定义了一个字典,里面存放所有个股信息
soup = BeautifulSoup(html, "html.parser")
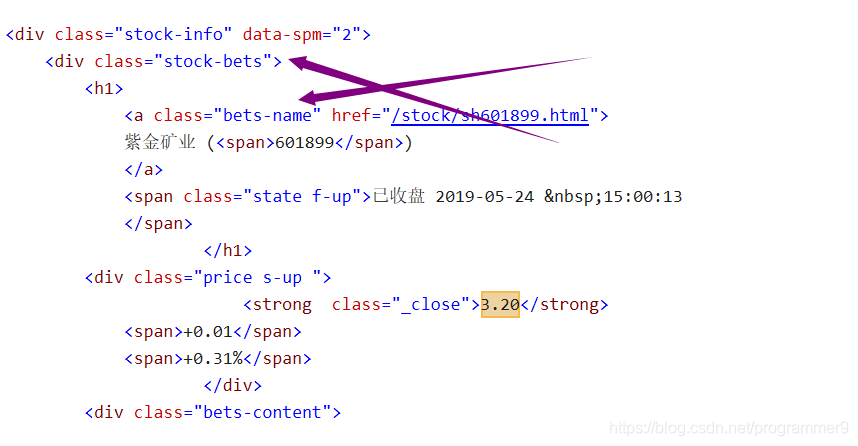
stockInfo = soup.find("div",attrs={"class":"stock-bets"})
name = stockInfo.find_all(attrs={"class":"bets-name"})[0]
infoDict.update({"股票名称":name.text.split()[0]})#真是奇怪,我总是把split写成spilt,怪不得会出现错误显示没有这个定义
#我们在此处获取的是第一部分,其余部分暂时舍弃
keyList = stockInfo.find_all("dt")#股票信息的键的域
valueList = stockInfo.find_all("dd")#股票信息的值的域
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val#赋值并将键值对存放到字典中,使用 key = value的办法
with open(fpath, "a", encoding = "utf-8") as f:
f.write( str(infoDict) + "\n")
except:
traceback.print_exc()
continue
def main():
stock_list_url = "http://quote.eastmoney.com/stocklist.html"#东方财富网,获取股票列表
stock_info_url = "http://gupiao.baidu.com/stock/"#百度股票,获得每只股票的具体信息
output_file = "F://股票数据定向爬取//股票数据.txt"#经过测试,如果没有这个txt文件,那么会新建一个写进去,如果有,则在该文件上写
slist = []#这个列表里面存储的是股票的信息
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
#我居然只爬了一个股票的信息,为什么不是所有的呢?
print("函数整体可以运行")





 该博客主要围绕使用Python进行股票数据定向爬取展开,借助Python的相关库和工具,可实现对股票数据的精准抓取,为后续的股票数据分析等操作提供数据基础,在信息技术领域有一定应用价值。
该博客主要围绕使用Python进行股票数据定向爬取展开,借助Python的相关库和工具,可实现对股票数据的精准抓取,为后续的股票数据分析等操作提供数据基础,在信息技术领域有一定应用价值。

















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









