




大数据架构
目录
大数据技术架构
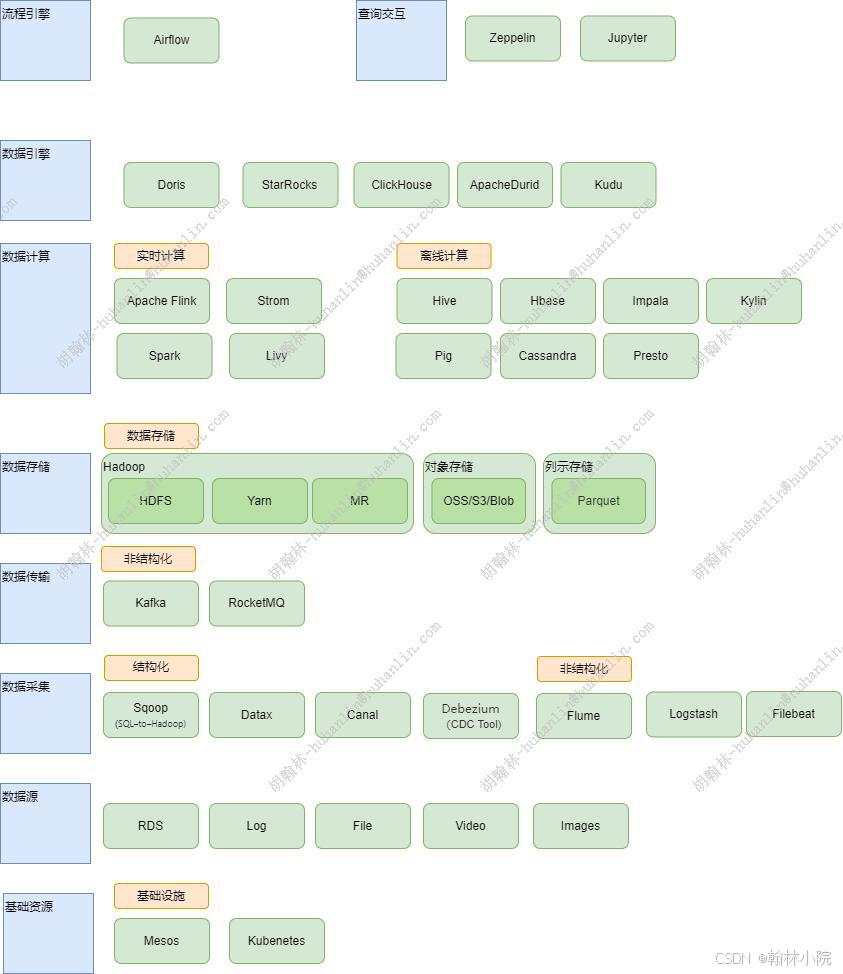
应用架构图
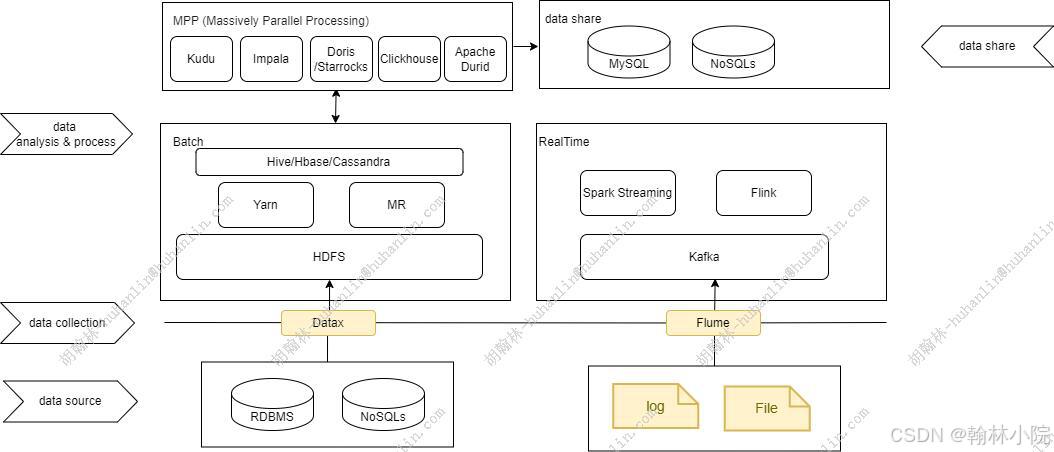
大数据相关框架
数据源
RDS
MySQL、PostgreSQL、Sqlserver等关系型数据库,通常通过Datax、Debezium采集。
Log
结构化文件、日志文件、sdout流等,通常通过Flume,Logstash,Fileat采集。
File
非结构化文件,视频、图片等,通常通过Flume采集,或者直接存入云存储。
数据采集
结构化
Sqoop
Sql to Hadoop,Sqoop依赖于hadoop服务,关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Datax
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
Canel
主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
Debezium
Debezium可以捕获数据库中所有行级的数据变化(CDC change data capture)并包装成事件流顺序输出。
非结构化
Apache Flueme
Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统。实时读取服务器本地磁盘的数据,将数据写入到HDFS.
Logstash
Logstash 是 Elastic Stack 的核心组件之一,它是一个强大的服务器端数据处理管道,可以从多个来源采集数据,转换数据,然后将数据发送到各种存储库中。Logstash 特别适用于日志数据的处理,它可以处理来自各种数据源的信息,无论是结构化还是非结构化的数据。
Filebeat
Filebeat是一个轻量级的日志采集工具,用于转发和汇总服务器、虚拟机和容器的日志。它从输入源读取日志,通过Harvester逐行读取,然后输出到目标如ElasticSearch。
数据传输
Kafka
MQ
RocketMQ
阿里
数据存储
HDFS
Hadoop中的
Yarm
Hadoop中的资源调度
对象存储
S3/OSS/Blob
云服务提供的对象存储
列存储
Parquet
是一种开源的列式存储数据文件格式,与简单的CSV格式行示存储相比,存储占用空间更小,查询性能更高,大幅降低存储成本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1718
1718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









