



微前端的核心价值
2.在html的head中添加meta(浏览器仍希望缓存的话无效)
整个会议下来,我只对一个话题有兴趣,就是 #大果 提出的灵魂拷问:
如果是 widget 级别,那么微前端跟业务组件的区别在哪里?微前端到底是因何而生?
圆桌环节简单发表了一下自己的观点,这里再文字补充一下。
先抛观点:
我认为微前端的核心价值在于 “技术栈无关”,这才是它诞生的理由,或者说这才是能说服我采用微前端方案的理由。
我抛两个场景,大家思考一下:
- 你新入职一家公司,老板扔给你一个 5 年陈的项目,需要你在这个项目上持续迭代加功能。
- 你们起了一个新项目,老板看惯了前端的风起云涌技术更迭,只给了架构上的一个要求:“如何确保这套技术方案在 3~5 年内还葆有生命力,不会在 3、5 年后变成又一个遗产项目?”
https://api.map.baidu.com/reverse_geocoding/v3/?ak=tY84UqTa6sSwgsrwkdSwtqB29GogsLCz&location=39.95933,116.298451&output=json&coordtype=wgs84ll
82SXBMwMkgq0F8Ham2MeRB7IoU&location=39.95933,116.298451&output=json&pois=1
Iframe出现的原因大概率不好实现,所以amis使用中或erp的使用,岩哥提供了几个iframe,但我个人不大喜欢iframe是有延迟的感觉或者
维护的时候就要维护模块好多连接,但微服务可以一个代码库记录下来
实习生考勤,因为我总爱用新的版本, 咱们基于老的项目是不敢轻易升级。 所以我就想到微服务
相比我们前端写的业务组件, 好处是兼容vue,react,原生js
也可以统一解决公用部分。 比如登陆方式,我和孙兴就改了5个系统
npm config set registry=https://registry.npm.taobao.org
2.1 技术特性
技术栈无关,可支持多种技术框架;
独立开发,独立部署,独立运行;
基于single-spa 封装,提供了更加开箱即用的API;
HTML Entry 接入方式: import-html-entry 去加载对应html 文件;
样式隔离,JS 沙箱:确保微应用之间样式互相不干扰,确保微应用之间 全局变量/事件不冲 突;
资源预加载:在浏览器空闲时间预加载未打开的微应用资源,加速微应用打开速度;
2. 会webpack的dll配置。
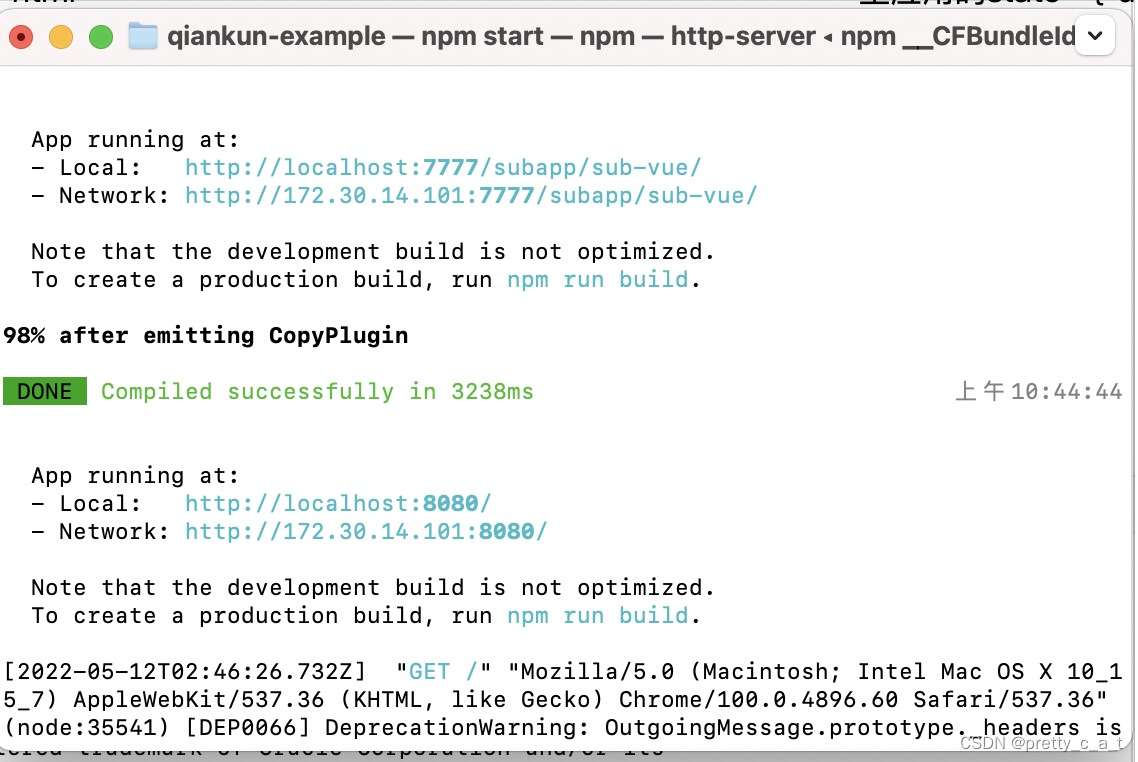
主应用http://localhost:3001/
node-sass “^4.12.0”
node v10.15.2

npm install webpack-dev-server --save-dev


echo “# little_c_a_t” >> README.md
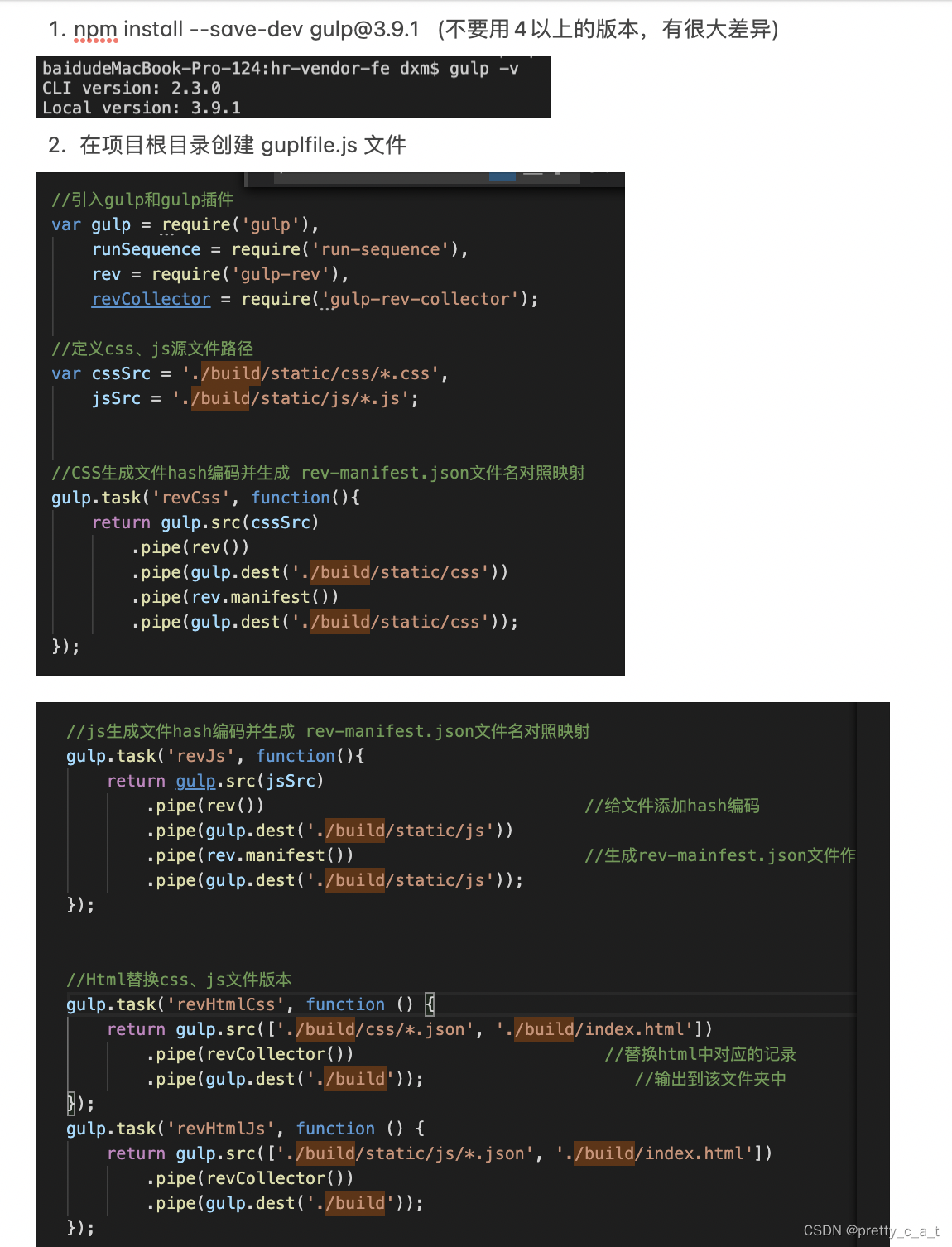
// //定义html任务—0105
// gulp.task(‘html’, function () {
// gulp.src(‘./src’)
// .pipe(gulp.dest(‘./dist’))
// .pipe(connect.reload());
// });
// //定义livereload任务
// gulp.task(‘connect’, function () {
// connect.server({
// livereload: true
// });
// });
// //定义看守任务
// gulp.task(‘watch’, function () {
// gulp.watch(‘src/.html’, [‘html’]);
// gulp.watch('src/.js’, [‘js’]);
// });
https://www.cnblogs.com/leeke98/p/11065734.html
前话:
1、什么是浏览器缓存?
浏览器缓存(Browser Caching)是为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览。
浏览器缓存主要有两类:缓存协商:Last-modified ,Etag 和彻底缓存:cache-control,Expires。
2、网站缓存有什么用?
在浏览网页过程中网站开发人员为了给用户带来更佳的浏览体验,使网站加载快速高效往往会在浏览器本地也就是设备上面存储缓存文件,因为网站或者web应用并不是实时大量内容的更新的,而是多数内容基本变化很小,因此在本地存储一部分文件,这样就不需要每次都重新加载全部的网站或者web应用信息,节省时间、流量,带来更佳的访问体验。
3、为什么要禁用浏览器缓存
在提升访问速度,节省流量的同时,保存缓存文件肯定会占据一定的设备存储空间,因此有些人在不需要追求时间流量的节省的时候,可以选择禁用浏览器缓存,这样浏览器不会在设备本地保存文件节省了存储空间。
场景:
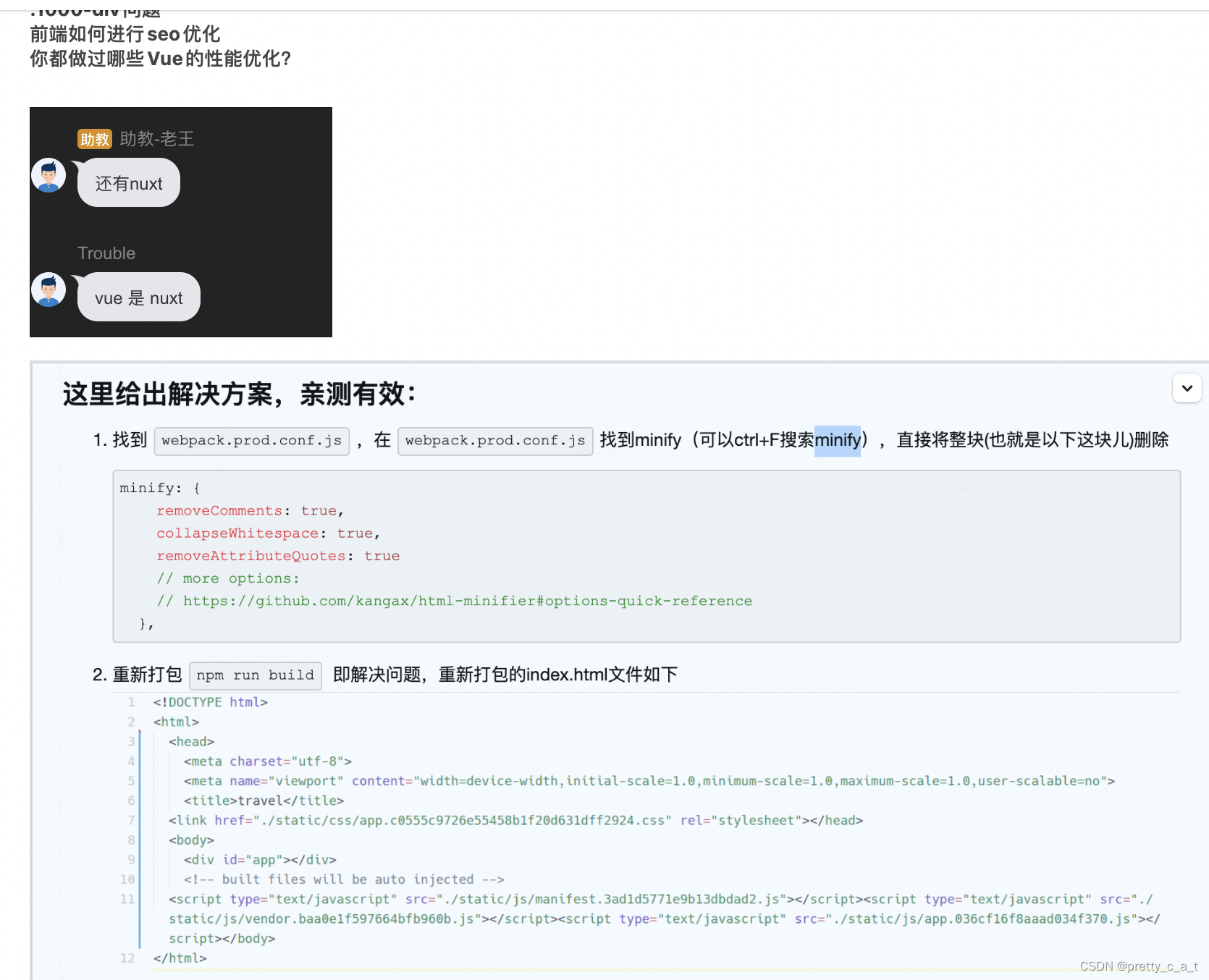
部分项目在打包上线后,因为不希望有些html缓存。但html的文件名字不会发生改变,就不会重新进行加载,造成页面故障
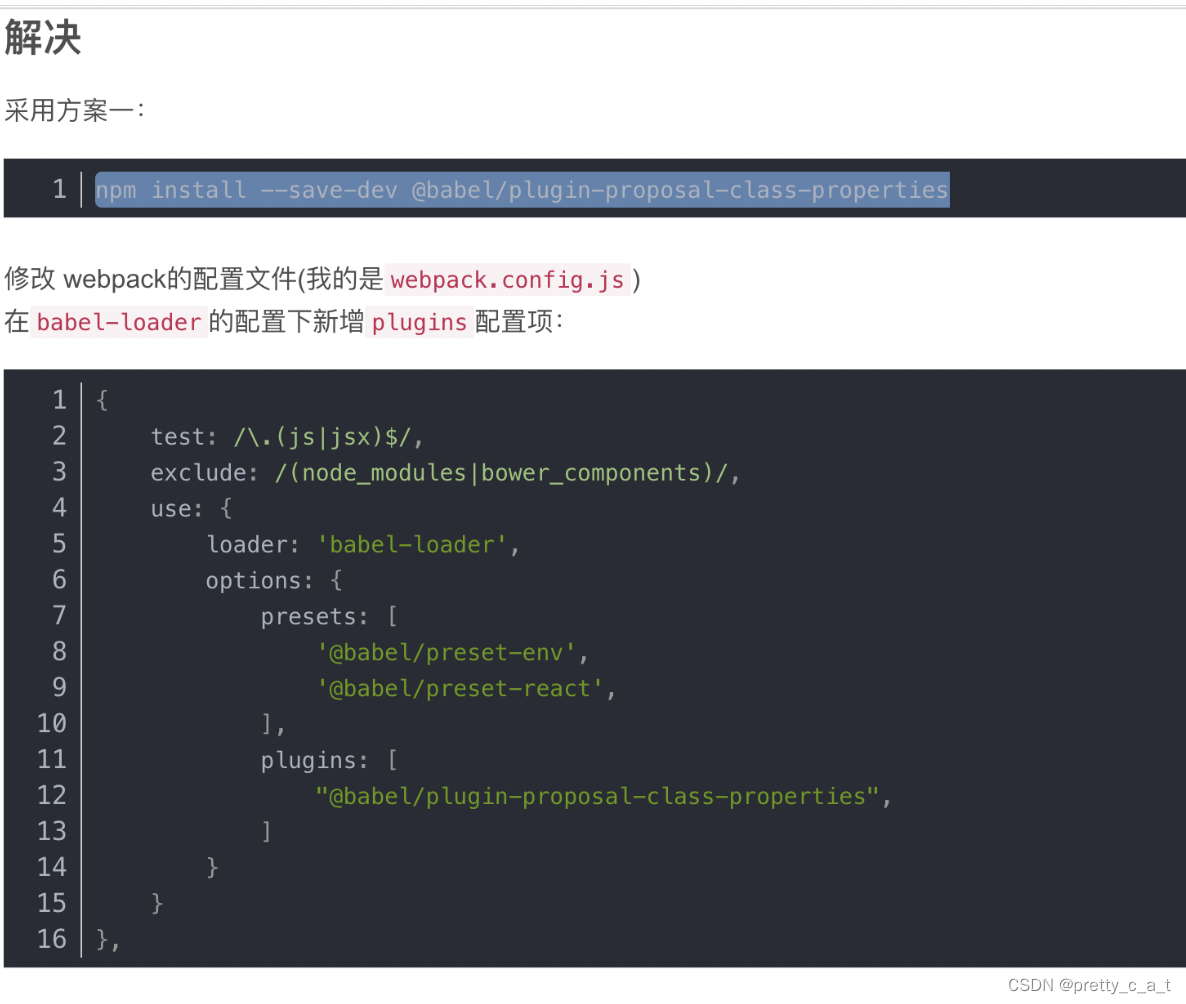
解决方案:
1.使用js向url添加随机参数(注意:若为hash模式,则随机参数需要放置在 # 前)
但是这样做也有一个弊端,因为缓存可以减少对服务器的直接访问,减少服务器的压力。浏览器不读取缓存里的内容之后,每次都会访问服务器,这样就会增加服务器的压力。所以应根据情况使用。
if (!window.name) {
location.href += “?random=” + Date.now();
window.name = “reloaded”;
}
3.后端设置get请求的response请求头
response.setDateHeader(“Expries”, -1);
response.setHeader(“Cache-Control”, “no-cache”);
response.setHeader(“Pragma”, “no-cache”);
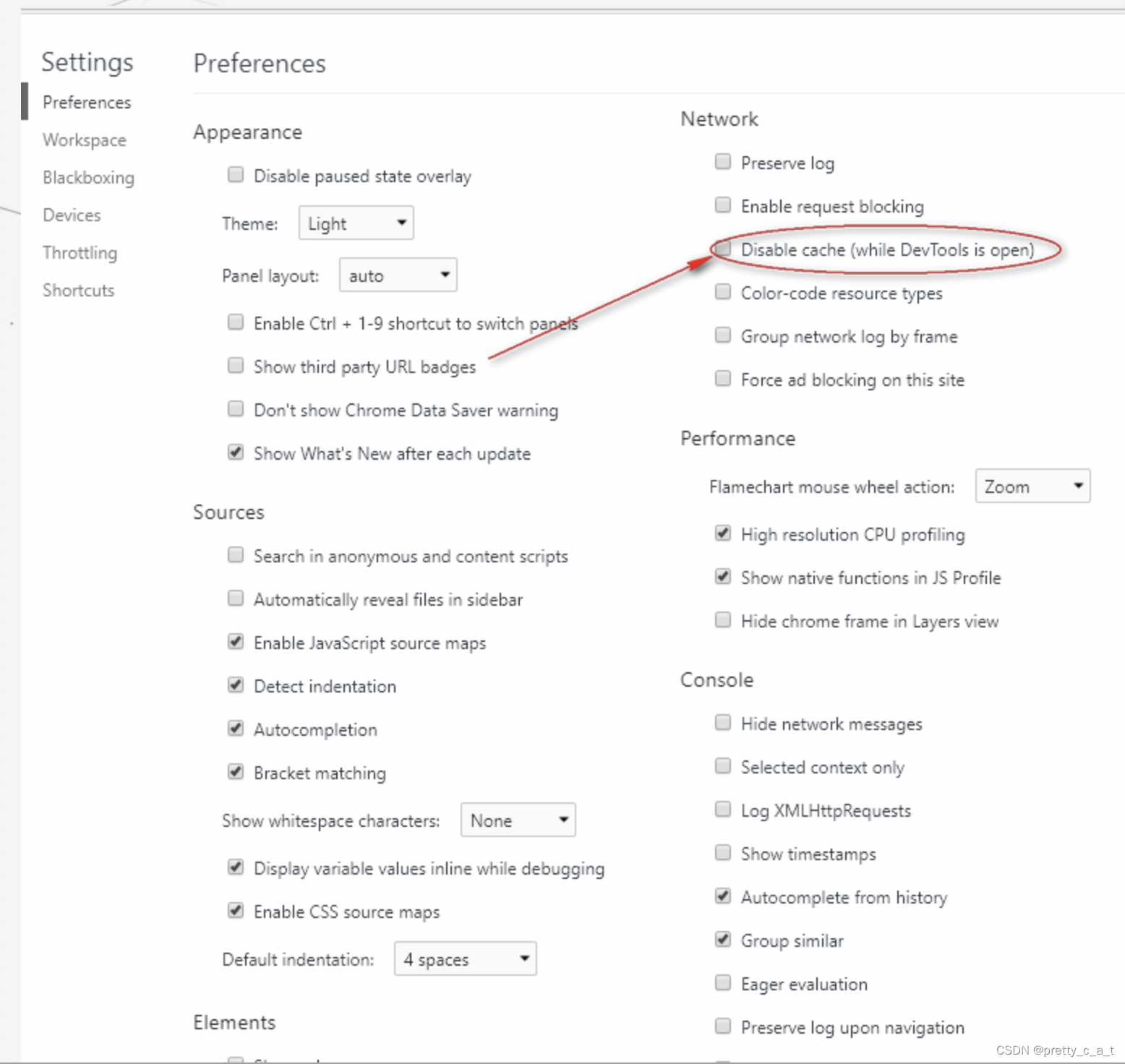
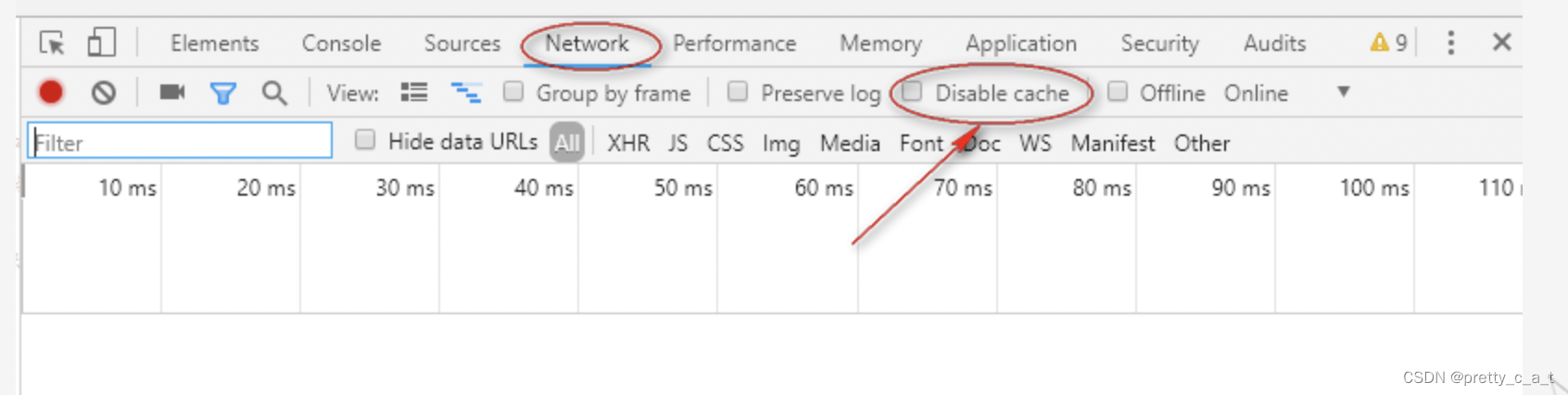
4.在浏览器中设置
F12打开控制台—>Network---->Disable cache 打钩
F12—>F1—>network ----> Disable cache(while DevTools is open) 打钩
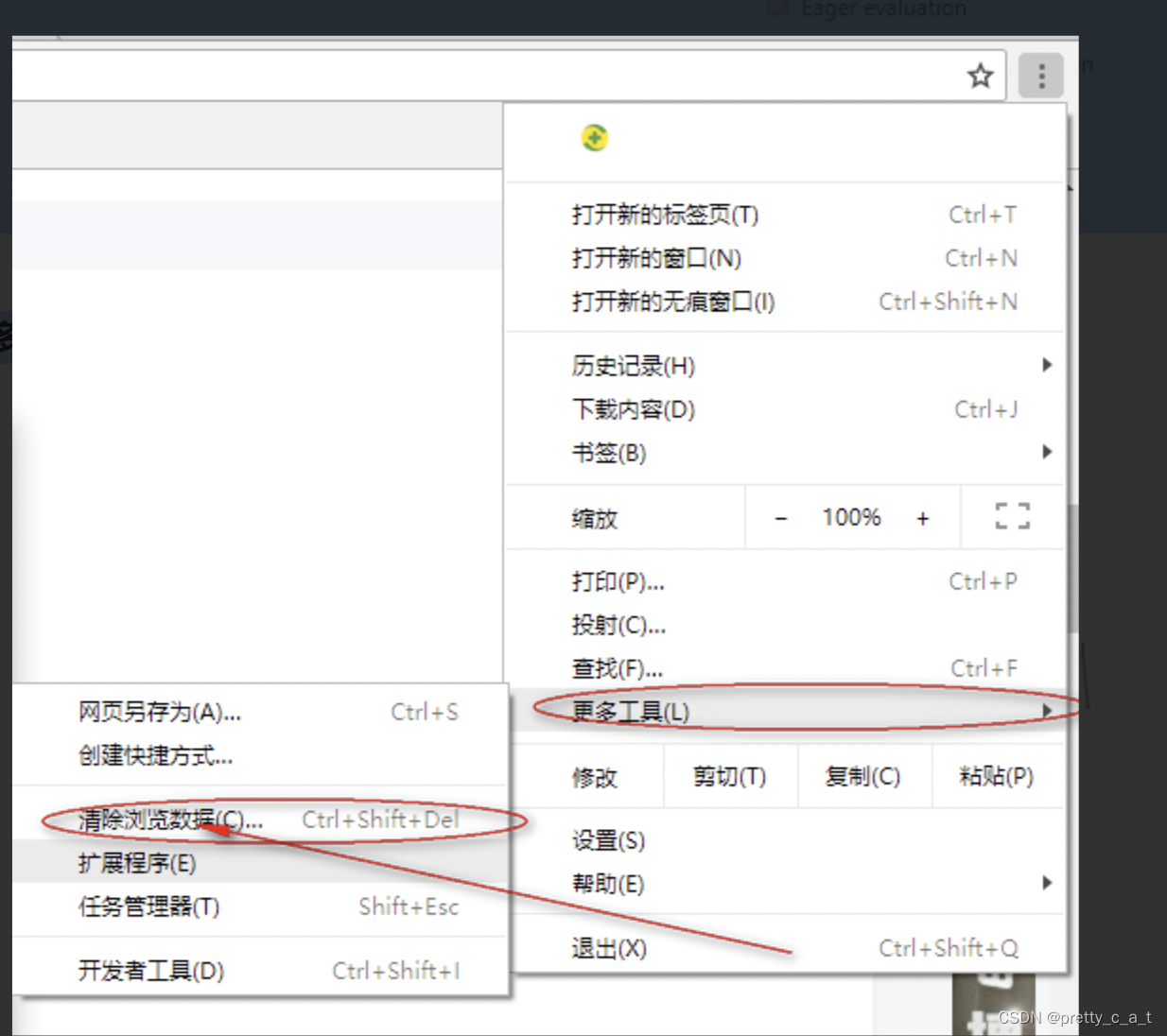
5.更多工具选项 或 ctrl+shift+delete 或 ctrl+f5----> 清除浏览数据
总结:
想让浏览器有何种行为,服务端只能通过响应头的方式来设置
想让服务器知道何种行为,浏览器只能通过请求头的方式来设置
https://www.cnblogs.com/davis16/p/8378393.html
前一年当前年后一年
https://juejin.cn/book/6844733813021491207?utm_campaign=sembaidu&utm_medium=sem_baidu_jj_pc_dc01&utm_source=bdpcjjqd02371
http://www.97yrbl.com/t-511.html
通过这几个框架的学习,感觉有好处,也有弊端,配合swr和recoil确实能提高开发效率
https://blog.youkuaiyun.com/weixin_39738251/article/details/111114619
https://www.liangzl.com/get-article-detail-227503.html
https://juejin.cn/post/6844904174417608712
https://blog.youkuaiyun.com/weixin_39738251/article/details/111114619
https://qiankun.umijs.org/zh/guide/getting-started
https://zhuanlan.zhihu.com/p/65574428
https://www.cnblogs.com/-walker/p/6056529.html
1.修改命令
git remote origin set-url [url]
2.先删后加
git remote rm origin
git remote add origin [url]
git全局配置
git config --global user.name “v_yanghaiyan_dxm”
git config --global user.email “v_yanghaiyan@duxiaoman.com”
创建一个新项目
git clone ssh://v_yanghaiyan_dxm@gitlab.duxiaoman-int.com:8022/v_yanghaiyan_dxm/dd.git
cd dd
touch README.md
git add README.md
git commit -m “add README”
git push -u origin master
基于存在的文件夹新建项目
cd existing_folder
git init
git remote add origin ssh://v_yanghaiyan_dxm@gitlab.duxiaoman-int.com:8022/v_yanghaiyan_dxm/dd.git
git add .
git commit -m “Initial commit”
git push -u origin master
基于存在的git仓库新建项目
cd existing_repo
git remote rename origin old-origin
git remote add origin ssh://v_yanghaiyan_dxm@gitlab.duxiaoman-int.com:8022/v_yanghaiyan_dxm/dd.git
git push -u origin --all
git push -u origin --tags

README.md
nodeCli
使用 egg.js 搭建一套开箱即用的web服务
功能点
- 数据库读写 √ done
- 用户系统
- 登录验证
- 单点登录
- 消息推动(邮件短信等)
QuickStart
Development
$ npm i
$ npm run dev
$ open http://localhost:7001/
Deploy
$ npm start
$ npm stop
npm scripts
- Use npm run lint to check code style.
- Use npm test to run unit test.
- Use npm run autod to auto detect dependencies upgrade, see autod for more detail.
数据库变更
通过migrate
# 升级数据库
npx sequelize db:migrate
# 如果有问题需要回滚,可以通过 db:migrate:undo 回退一个变更
# npx sequelize db:migrate:undo
# 可以通过 db:migrate:undo:all 回退到初始状态
# npx sequelize db:migrate:undo:all

一般会经历以下几个过程:
1、首先,在浏览器地址栏中输入url
2、浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显示页面内容。若没有,则跳到第三步操作。
3、在发送http请求前,需要域名解析(DNS解析)(DNS(域名系统,Domain Name System)是互联网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住IP地址。),解析获取相应的IP地址。
4、浏览器向服务器发起tcp连接,与浏览器建立tcp三次握手。(TCP即传输控制协议。TCP连接是互联网连接协议集的一种。)
5、握手成功后,浏览器向服务器发送http请求,请求数据包。
6、服务器处理收到的请求,将数据返回至浏览器
7、浏览器收到HTTP响应
8、读取页面内容,浏览器渲染,解析html源码
9、生成Dom树、解析css样式、js交互
10、客户端和服务器交互
11、ajax查询
回流必将引起重绘,而重绘不一定会引起回流。
重汇和回流的简介:
- 当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候。在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为重绘。
- 当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
注意:回流必将引起重绘,而重绘不一定会引起回流。
**什么时候会发生回流?
当页面布局和几何属性改变时候就需要回流。下面的情况会引发浏览器的回流:
1:添加或者删除可见的DOM元素
2:元素位置改变;
3:元素尺寸改变----边距、填充、边框、高度和宽度
4:内容改变—比如文本改变或者图片大小改变而引起的计算值宽度和高度改变
5:页面渲染初始化
6:浏览器窗口尺寸改变—resize事件发生时
**什么时候发生重绘?
1.改变字体
2.增加或者移除样式表
3.内容变化(input框输入文字)
4.激活css伪类 eg :hover
5.计算offsetWidth、offsetHeigth属性(浏览器的可见高度)
6.设置style属性的值
3.如何减少回流、重绘
减少回流、重绘其实就是需要减少对render tree的操作(合并多次DOM和样式的修改),并减少对一些style信息的请求,尽量利用好浏览器的优化策略。具体方法: - 直接改变className,如果动态改变样式,则使用cssText(考虑没有优化的浏览器)
- 让要操作的元素进行”离线处理”,处理完后一起更新
a) 使用DocumentFragment进行缓存操作,引发一次回流和重绘;
b) 使用display:none技术,只引发两次回流和重绘;
c) 使用cloneNode(true or false) 和 replaceChild 技术,引发一次回流和重绘;
3.不要经常访问会引起浏览器flush队列的属性,如果你确实要访问,利用缓存
4. 让元素脱离动画流,减少回流的Render Tree的规模
————性能优化————
①对象相互引用会导致引用计数始终为2,所以用完对象后应将引用设为null,例子如下

let element = document.getElementById(“test”);
let myObject = new Object();
myObject.element = element;
element.someObject = myObject;
//…用完后需要加如下代码
myObject.element = null;
element.someObject = null;
②循环优化,这里其实用后测试循环代替前测试循环会更好,不过本地不采用,例子如下

//原有复杂度为O(n)
for (let i = 0; i < values.length; ++i){
process(values[i]);
}
//更改后复杂度为O(1)
for (let i = values.length - 1; i >= 0; --i){
process(values[i])
}
————节流和防抖————
防抖和节流严格算起来应该属于性能优化的知识,但实际上遇到的频率相当高,处理不当或者放任不管就容易引起浏览器卡死。
这个按钮只会在滚动到距离顶部一定位置之后才出现,那么我们现在抽象出这个功能需求-- 监听浏览器滚动事件,返回当前滚条与顶部的距离
这个需求很简单,直接写:
function showTop () {
var scrollTop = document.body.scrollTop || document.documentElement.scrollTop;
console.log(‘滚动条位置:’ + scrollTop);
}
window.onscroll = showTop
然而实际上我们并不需要如此高频的反馈,毕竟浏览器的性能是有限的,不应该浪费在这里,所以接着讨论如何优化这种场景。
防抖(debounce)
基于上述场景,首先提出第一种思路:在第一次触发事件时,不立即执行函数,而是给出一个期限值比如200ms,然后:
- 如果在200ms内没有再次触发滚动事件,那么就执行函数
- 如果在200ms内再次触发滚动事件,那么当前的计时取消,重新开始计时
效果:如果短时间内大量触发同一事件,只会执行一次函数。
实现:既然前面都提到了计时,那实现的关键就在于setTimeOut这个函数,由于还需要一个变量来保存计时,考虑维护全局纯净,可以借助闭包来实现:
———闭包???
闭包就是能够读取其他函数内部变量的函数例如在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
fn 是需要防抖的函数 delay 毫秒,防抖期限
function debounce(fn, delay) {
let timer = null; // 借助闭包
return function() {
if(timer){
// 进入该分支语句,说明当前正在一个计时过程中,并且又触发了一个相同事件。所以要取消当前的计时,重新开始计时
clearTimeout(timer);
timer = setTimeOut(fn, delay);
}else{
// 进入该分支说明当前并没有在计时,那么就开始一个计时
timer = setTimeOut(fn, delay);
}
}
}
// 简化写法
function debounce(fn, delay){
let timer = null;
return function(){
if(timer){
clearTimeout(timer);
}
timer = setTimeout(fn)
}
}
function showTop () {
var scrollTop = document.body.scrollTop || document.documentElement.scrollTop;
}
Window.onscroll = debounce(showTop, 1000)
以上,实现了防抖
https://segmentfault.com/a/1190000018428170
如果在限定时间段内,不断出发滚动事件(比如某个用户闲着无聊,按住不断的拖来拖去,理论上永远不会输出当前距离顶部的距离)
设置一个控制阀门定期开放的函数,也就是让函数执行一次后,在某个时间段内暂时失效,过了这段时间jj
1.软件安装
安装常用软件:
后端:JDK1.8; Maven; IntelliJ IDEA;SecureCRT; Mysql Workbench; Navicat for MySQL; Postman… 安装过程见步骤2:“2.个人电脑开发环境配置”
前端:VsCode sublime …
- token 申请
2.个人电脑开发环境配置
个人电脑环境推荐使用 homebrew 包管理工具安装各种依赖环境
https://brew.sh/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 /usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
安装完成后
安装 java
brew cask install java
安装 maven
brew install maven
安装 mysql
brew install mysql
以上 基本环境即搭建完成,如有其他需要 可以通过 brew search 搜索包,根据提示安装即可
2.1安装 maven和jdk(推荐使用上述方式安装,也可以手工安装)
k8s有三种网络

由外往内
1,节点网络
2,service网络,也成集群网络
3,pod网络
它们的网络关系是一层一层相互代理的
k8s的三类通信方式

Overlay是Linux内核3.18后支持的(当前3.10内核加载模块也可以使用),也是一种Union FS,和AUFS的多层不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的容器层和镜像层
OverlayFS底层目录称为lowerdir,高层目录称为upperdir。合并统一视图称为merged。当需要修改一个文件时,使用cow将文件从只读的Lower复制到可写的Upper进行修改,结果也保存在Upper层。在Docker中,底下的只读层就是image,可写层就是Container

-
如果upperdir和lowerdir有同名文件时会用upperdir的文件
-
读文件的时候,文件不在upperdir则从lowerdir读
-
如果写的文件不在uppderdir在lowerdir,则从lowerdir里面copy到upperdir。
-
不管文件多大,copy完再写,删除或者重命名镜像层的文件都只是在容器层生成whiteout文件标志(标记为删除,并不是真的删除)
overlay: 使用2层分层, 共享数据方式是通过硬连接,只挂载一层,其他层通过最高层通过硬连接形式共享(增加了磁盘inode的负担)
overlay2: 使用2层分层, 驱动原生地支持多层lower overlay镜像(最多128层),与overlay驱动对比,消耗更少的inode
kube-proxy:这个组件一般是运行在node之上的守护进程叫kube-proxy,它负责随时与API Server进行通信,一旦发现service背后的pod发生改变地址发生改变,则对应的由kube-proxy在本地反应到iptables或ipvs规则中,所以service是靠kube-proxy实现的
ectd:是一个键值对存储,是kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划,需要对它做高可用,至少有三个节点
etcd一般有两个端口,一个用于集群外部通信(向客户端提供服务),一个用于集群内部通信
内部通信需要专门的证书,叫点对点通信的证书来配置https,
而向客户端(API Server)提供服务的时候通过https协议,要想加密又要另外一套证书来实现
而客户端向API Server通信又需要另外一套ca颁发的证书
CNI:插件体系来接入外部的网络服务解决方案,CNI叫做容器网络接口
K8S网络:

1,架构角色

Master Node:集群管理中心
Minion Node:用于运行用户pod
kubernetd Master 节点中的组件
1.1 kube-scheduler :监视新创建没有分配到Node的Pod,为Pod选择一个Node
1.2 kube-apiserver:用于暴露kubernetes API,任何的资源请求/调用操作都是通过kube-apiserver提供的接口进行
1.3 kuber-controller-Manager;运行管理控制器。集群中处理常规任务的后台线程
控制器包括:
-
节点(Node)控制器
-
副本(Replication)控制器:负责维护系统中每个副本中的pod
-
资源(ResourceQuota)控制器:三个级别控制资源分配
-
命名(namespace)空间控制器:管理namespace的生命周期.
-
端点(Endpoints)控制器:填充Endpoints对象(即连接service&pods)
-
Service Account和Token控制器:为新的NameSpaces创建默认帐户访问API Token
1.4 ETCD:是kubernetes的默认储存系统,保存所有集群数据,使用时需要为etcd数据提供备份计划
kubernetes Node节点中的组件
作用:
-
创建、销毁pod
-
管理volume(CVI)和网络(CNI)
-
维护pod及service等信息
2.1 kubelet:负责维护容器的生命周期(创建pod ,销毁pod),同时也负责Volume(CVI)和网络(CNI)的管理
2.2 kube-proxy:service服务(提供路由表pod—>service <—node)
-
通过在主机上维护网络规则并执行连接转发来实现service(Iptables/Ipvs)
-
随时与API通信,把Service或Pod改变提交给API(不存储在Master本地,需要保存至共享存储上),保存至etcd(可做高可用集群)中,负责service实现,从内部pod至service和从外部node到service访问。
2.3 Container Runtime:负责镜像管理以及Pod和容器的真正运行
kubernetes 集群附件
3.1 coredns/kube-dns:负责为整个集群提供DNS服务
3.2 Ingress Controller:为服务提供集群外部访问
3.3 Heapster/Metries-server:提供集群资源监控
3.4 Dashboard:提供GUI
3.5 Fluentd-elasticsearch:提供日志采集,存储与查询
2,k8s核心概念
2-1,pod
作用:
1,kubeernentes集群调度的最小单元,运行在Node节点之上,不能再集群外直接访问
2,pod是容器的外壳,pod中包含了运行的容器
3,可把多个容器放在pod中,会有一个主容器,另外的是边车容器(sidecar)
2-2 ,service
作用:
此服务是iptables或ipvs的变化
-
能够感知pod ip地址的变化
-
先创建pod,后创建service,创建service其实就是在iptables或ipvs中添加一条规则
-
通过service访问pod
2-3,lable
-
标签
-
是key/value对,绑定在kubernetes资源对象上
-
是同一个资源对象上,key不能重复,必须唯一
作用:让用户或控制器可识别
2-4,lable-selector(标签选择器)
作用:
-
在众多带有标签的node、pod或其他资源对象,找出指定标签的资源对象
-
kube-proxy是通过service上的label selector来选择pod,自动建立每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制
-
通过对某些Node定义特定的Label,并且在Pod定义文件中使用Node Selector这种标签调度策略,Kube-scheduler进程可以实现Pod定向调度的特性
2-5,controller
作用:
-
资源控制器
-
用于对应用进行监控,当pod出现问题时,会把pod重新拉起。
常见控制器:
-
Deployment 声明式更新控制器
-
ReplicaSet 副本集控制器
-
StatefulSet 有状态副本集
-
DaemonSet 在每一个Node上运行一个副本
-
Job 运行作业任务
-
CronJob 周期执行任务作业任务
-
pod类型
-
自主控制
-
带控制器
-
3,k8s集群验证
kubectl version 验证集群版本
kubectl get cs 检查集群状态
kubectl get componentstatus 验证scheduler/controller-manager/etcd等组件状态
kubectl get nodes 验证节点就绪(READY)状态
kubectl get pod --all-namespaces 验证集群pod状态,默认已安装网络插件、coredns、metrics-server等
kubectl get svc --all-namespaces 验证集群服务状态
4,YAML格式查找帮助
kubectl api-versions 查看api版本
查看资源写法:
kubectl explain namespace
kubectl explain pod
kubectl explain pod.spec
kubectl explain pod.spec.containers
5,查看集群与节点信息命令
查看集群信息:# kubectl cluster-info
查看节点信息:# kubectl get nodes
查看节点详细信息: # kubectl get nodes -o wide
描述节点详细信息:# kubectl describe node master
6,节点标签操作
查看节点标签信息:# kubectl get nodes --show-labels
设置节点标签:# kubectl lable node node1(节点名) node-role.kubernetes.io/node(标签名)=A(标签信息)
多维度标签设置:# kubectl label node node2(节点名) region=huanai zone=A env=test bussiness=game (多维度节点信息)
显示节点的相应用标签:# kubectl get nodes -L region,zone(节点信息)
按标签信息查找节点:# kubectl get nodes -l region=huanai(节点信息)
修改标签信息:# kubectl label node node2(节点名) bussiness=ad(标签信息) --overwrite=true
加上–overwrite=true覆盖原标签的value进行修改操作
使用key加一个减号的写法来取消标签
取消标签信息:# kubectl label node node2(节点名) region- zone- env- bussiness-(标签名-)
标签选择器
打完标签后的node,pod,deployment等资源都可以在标签选择器里进行匹配
标签选择器主要有2类:
等值关系: =, !=
集合关系: KEY in {VALUE1, VALUE2…}
kubectl get node -l “bussiness in (game,ad)”(标签信息)
7,namespace操作
Namespace是对一组资源和对象的抽象集合.
Namespace常用来隔离不同的用户,如Kubernetes自带的服务一般运行在kube-system namespace中.
对于同一种资源的不同版本,就可以直接使用label来划分即可,不需要使用namespace来区分
常见的 pod, service, replication controller 和 deployment 等都是属于某一个 namespace 的(默认是 default)
而 nodes, persistent volume,namespace 等资源则不属于任何 namespace。
查看namespace:# kubectl get namespaces
创建namespace # kubectl create namespace namespace1(namespace名)
YAML文件创建: # vim create_namespace.yml
apiVersion: v1 # api版本号
kind: Namespace # 类型为namespace
metadata: # 定义namespace的元数据属性
name: namespace2 # 定义name属性为namespace2
kubectl apply -f create_namespace.yml
删除namespace:# kubectl delete namespace namespace1(namespace名)
YAML文件删除:# kubectl delete -f create_namespace.yml
pod故障排除
状态 描述
Pending pod创建已经提交到Kubernetes。但是,因为某种原因而不能顺利创建。例如下载镜像慢,调度不成功。
Running pod已经绑定到一个节点,并且已经创建了所有容器。至少有一个容器正在运行中,或正在启动或重新启动。
completed Pod中的所有容器都已成功终止,不会重新启动。
Failed Pod的所有容器均已终止,且至少有一个容器已在故障中终止。也就是说,容器要么以非零状态退出,要么被系统终止。
Unknown 由于某种原因apiserver无法获得Pod的状态,通常是由于Master与Pod所在主机kubelet通信时出错。
CrashLoopBackOff 多见于CMD语句错误或者找不到container入口语句导致了快速退出,可以用kubectl logs 查看日志进行排错
8,pod操作
pod可分为:
-
无控制器管理的自主式pod 删除后不会重新创建
-
控制器管理的pod 控制器会按照定义的策略控制pod的数量,发现pod数量少了,会立即自动建立出来新的pod;一旦发现pod多了,也会自动杀死多余的Pod。
查看pod信息: # kubectl get pod
查看pod详细信息:# kubectl get pod -o wide
描述pod详细信息:# kubectl describe pod memory-demo(pod名)
查看pod标签:# kubectl get pods --show-labels
通过等值关系标签查询:# kubectl get pods -l zone=A(标签信息)
通过集合关系标签查询:# kubectl get pods -l “zone in (A,B,C)”(标签信息)
删除pod:# kubectl delete pod memory-demo(pod名称)
9,Deployment&ReplicaSet
作用:Deployment与RC的作用其实是一样的,都是为了管理Pod的副本数
9.1 验证
kubectl get deployment
9.2 删除的deployment
kubectl delete deployment deployment名
说明:删除deployment,那么里面的pod也会被自动删除
9.3 pod版本升级
查看帮助:# kubectl set image -h
验证版本:# kubectl describe pod nginx1-7d9b8757cf-czcz4(容器名) |grep Image:
kubectl kubectl exec nginx1-7d9b8757cf-czcz4(容器名) – nginx -v
升级版本:# kubectl set image deployment nginx1(deployment名) nginx1=nginx:1.16-alpine(容器版本) --record
-
deployment nginx1代表名为nginx1的deployment
-
nginx1=nginx:1.16-alpine前面的nginx1为容器名
-
–record 表示会记录
容器名查看: -
kubectl describe pod pod名 查看
-
kubectl edit deployment deployment名 来查看容器名
-
kubectl get deployment deployment名 -o yaml 来查看容器名
验证:# kubectl rollout status deployment nginx1(deployment名)
验证版本:# kubectl describe pod nginx1-7d9b8757cf-czcz4(容器名) |grep Image:kubectl kubectl exec nginx1-7d9b8757cf-czcz4(容器名) – nginx -v
9.4 pod版本回退
查看历史版本信息: # kubectl rollout history deployment nginx1(deployment名)
定义需要回退的版本:# kubectl rollout history deployment nginx1(deployment名) --revision=1(版本号)
执行回退:# kubectl rollout undo deployment nginx1 --to-revision=1
验证:# kubectl rollout history deployment nginx1(deployment名)
验证版本:# kubectl describe pod nginx1-7d9b8757cf-czcz4(容器名) |grep Image:
kubectl kubectl exec nginx1-7d9b8757cf-czcz4(容器名) – nginx -v
9.5 副本扩容与剪裁
kubectl scale deployment nginx1(deployment名) --replicas=2(副本数)
查看验证: # kubectl get pods -o wide
9.6 多副本滚动更新
kubectl set image deployment nginx1(deployment名) nginx1=nginx:1.17-alpine(容器版本) --record
查看验证:# kubectl rollout status deployment nginx1(deployment名)
10,service
service类型
-
ClusterIP:默认类型,自动分配一个仅cluster内部可以访问的虚拟IP 常用于内部程序互相的访问。
-
NodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过:来访问该服务。可以在前面结合比如阿里云的SLB,也可以自己搭建lvs,haproxy等
NodePort方式暴露服务的端口的默认范围(30000-32767)
如果需要修改则在apiserver的启动命令里面添加如下参数 –service-node-port-range=1-65535
-
LoadBalancer:使用支持外部负载均衡器的云提供商的服务。其实也是NodePort,只不过会把:自动添加到公有云的负载均衡当中
-
ExternalName:把集群外部的服务引入到集群内部中来,实现了集群内部pod和集群外部的服务进行通信
10.1 查看service

















 8091
8091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









