




视觉-语言基础模型(VLFMs)在图像描述、图文检索、视觉问答和视觉定位等多模态任务中取得了显著进展。然而,现有方法大多基于通用图像数据集训练,由于缺乏对地观测数据,其在遥感与地理空间分析中表现受限。近年来,研究者陆续提出了多个地理空间图文对数据集及基于这些数据微调的VLFMs。这些新方法旨在利用大规模多模态对地观测数据,构建具有多样化地理感知能力的通用智能模型,我们将其统称为“视觉-语言地理基础模型”(VLGFMs)。
本文系统综述了VLGFMs的研究进展,总结并分析了该领域的最新发展。具体而言,我们首先介绍了VLGFMs兴起的背景与动机,突出其独特的研究意义;进而系统总结了VLGFMs涉及的核心技术,包括数据构建、模型架构以及多模态地理空间任务中的应用;最后,围绕未来研究方向提出了见解、问题与讨论。据我们所知,这是首篇对VLGFMs进行全面梳理的文献综述。相关研究成果持续追踪于:https://github.com/zytx121/Awesome-VLGFM
Introduction
在过去的十年中,研究人员见证了深度学习和其他人工智能技术驱动下几乎所有地理空间任务的显著进步,包括场景分类[1]、目标检测[2][3]、变化检测[4]、去噪[5]、土地利用分割[6]、灾害管理[7]和地理空间定位[8]等。然而,这些模型是为特定任务专门设计和训练的,难以直接应用于其他任务。即使对于相似任务,这些模型也常表现出较差的泛化能力。
例如,遥感目标检测是地球观测的核心任务之一,其需要人工标注每个对象的位置和类别,这是一个耗时费力的过程。遥感图像(RSIs)由星载或机载传感器从俯视视角采集,与自然图像相比呈现独特的视角特点,因此催生了旋转目标检测任务的发展。由于该任务使用旋转边界框表示对象,需要标注有旋转边界框的遥感数据集(如DOTA[9])来支持训练。此外,模型架构[10]、损失函数[11]、后处理函数和加速算子[12]都必须基于标准目标检测[13]进行修改。从这个角度看,特定模型的应用场景似乎相当有限,缺乏跨不同任务甚至两个相似任务之间的泛化能力。
为减少为每个任务从头训练特定模型所带来的资源浪费,基础模型[14]应运而生。这些模型在大规模图像上预训练,仅需微调小规模定制数据集即可处理各种视觉任务。在遥感领域,先前关于纯视觉基础模型的研究揭示了一个通用地球观测模型的巨大潜力,这类模型被称为视觉地理基础模型(VGFMs)。VGFMs在全面评估中展现出卓越的泛化能力,涵盖从单模态到多模态、从静态到时序的任务[15]。尽管这些模型表现出强大的感知能力,但它们缺乏像人类一样的推理能力。例如,若无相应标注样本支持VGFM训练,它无法通过考虑周围环境和常识来确定遥感图像中建筑物的具体功能,而人类可以。同样,没有标注样本,VGFM无法根据航空影像中的特征识别汽车的品牌或型号,而人类可以。
最近,大语言模型(LLMs)的演进彻底改变了人机交互。像BERT[16]这样的LLMs利用海量文本数据发展推理技能,在自然语言处理的多样化任务中展现出强大的泛化能力。然而,LLMs仅处理离散文本数据,无法处理图像;而视觉基础模型虽能处理图像数据,却缺乏推理能力。为弥合这些差距,视觉-语言基础模型(VLFMs)的概念被引入。这些创新模型旨在执行感知和推理,整合文本和图像的输入。自GPT-4 Vision发布以来,受其令人印象深刻的能力启发,VLFMs的研究一直备受热捧。大量努力投入于VLFMs,这些模型通常分为对比式、对话式和生成式范式。下面我们将简要介绍这三个方向中最具影响力的工作。具体而言,CLIP[17]采用对比范式,将视觉和文本信息投影到统一的表示空间,从而为下游视觉-语言任务搭建桥梁。LLaVA[18]体现对话范式,赋予LLMs跨文本和视觉模态的上下文感知对话能力。Stable Diffusion[19]是生成范式的典范,利用深度学习从文本描述生成高质量、精细的图像,从而推进图像合成和创造性视觉应用的能力。
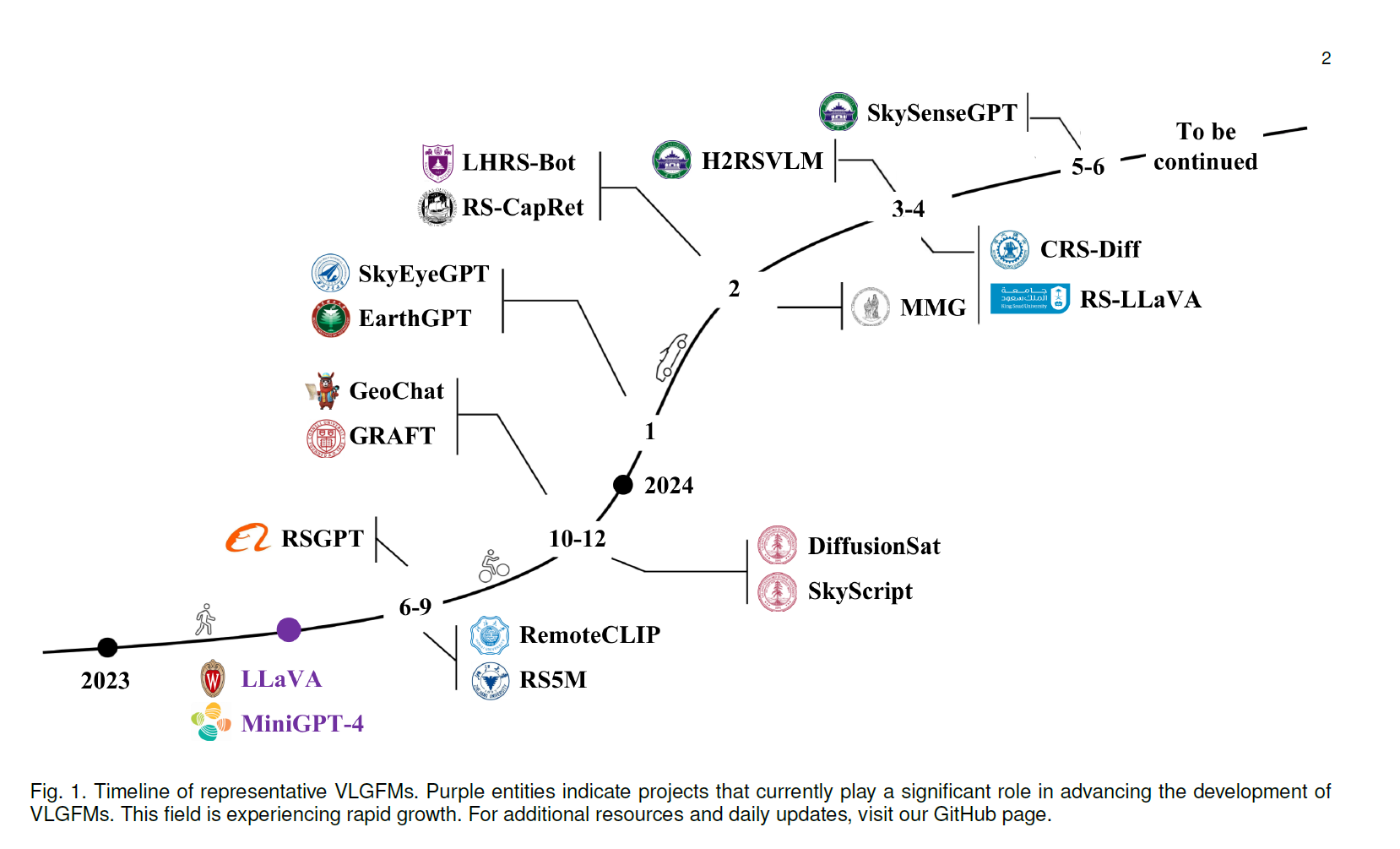
当VLFMs应用于地球观测时,本文将其称为视觉-语言地理基础模型(VLGFMs)。至今,VLGFMs也可分为对比式、对话式和生成式类型。图1列出了已开发的代表性VLGFM及其发布日期。可以看出,VLGFMs最早出现在2023年第二季度,目前相关工作的数量正处于快速增长期。值得注意的是,当前VLGFM的创新主要集中于收集训练数据,对模型架构的修改相对较少。大多数努力涉及使用自定义的遥感指令跟随集基于LLaVA[18]和MiniGPT-4[20]框架进行微调。
随着VLGFM的快速发展和令人印象深刻的成果,跟踪和比较VLGFM的最新研究是值得的。它通过自然语言对话实现与人类的端到端交互,改变了依赖预定义程序接口的传统人机交互方式。据我们所知,目前尚无全面综述总结VLGFMs的最新发展,包括数据流程、架构、基准测试和能力。我们的工作旨在填补这一空白。
贡献。鉴于VLGFM的快速进展和前景,我们撰写本综述以使研究人员熟悉VLGFMs的基本概念、主要方法和当前进展。本综述提取了共同的技术细节,覆盖了VLGFMs领域最具代表性的工作,并对背景及相关概念(包括VGFMs和遥感LLM驱动的智能体)进行了比较分析。此外,我们将VLGFMs展示的能力分为三个层级。据我们所知,我们是首个关于VLGFMs的综述。
综述流程。在第2节中,我们提供背景知识,包括定义、数据集、指标和相关研究领域。在第3节中,我们基于不同的数据收集方法、网络架构和能力对各种方法进行全面回顾。在第4节中,我们指出挑战和未来方向。
2. Background 背景知识
在本节中,我们首先介绍视觉-语言地理基础模型(VLGFM)的概念定义,并将其与相关概念进行比较;随后梳理VLGFM的发展历程并重点介绍若干代表性模型;接着呈现该领域常用基准数据集与评估指标;最后对相关研究领域进行回顾。
2.1 概念定义
**基础模型是一类通过大规模数据训练后具有广泛适用性和通用能力的模型。这类模型通常参数量巨大、学习能力强,能够在多种任务中表现出色。**尽管基础模型目前尚未无处不在,但它们似乎正成为广泛技术创新的基础,并展现出通用技术的关键特征[35]。本文综述的领域可同时处理多任务,仅支持单一任务的视觉-语言模型不在研究范围内,有关注任务特定视觉-语言模型的读者请参阅[14]。
地理基础模型是一类专为通过视觉信息处理地理空间数据而设计的模型。它们利用各类对地观测视觉数据(如遥感影像、卫星照片和航空图像)进行详细分析并支持多种地理应用。尽管该研究是目前热门话题,但并非本文焦点,对纯视觉地理基础模型感兴趣的读者请参阅[36]。
视觉-语言地理基础模型是人工智能模型的一个专门子类,旨在通过整合视觉与语言信息处理和分析地理空间数据。这些模型能够处理多样化的地理空间数据源,如遥感影像、地理信息系统数据和地理标注文本,并利用其跨模态处理能力理解与整合不同类型的地理空间信息。通过结合视觉和语言模态,VLGFMs能够对地理空间数据进行更全面、准确的分析,使其在复杂地球观测任务中极具价值。本文聚焦于这类VLGFMs,排除仅限于视觉模态或特定任务的模型。据我们所知,这是首篇对VLGFMs的详尽文献综述。
2.2 发展历程与路线图
在介绍VLGFM细节之前,有必要回顾其进展。图1总结了VLGFM的发展时间线并列出部分代表性工作。遥感领域VLFMs的发展起步较晚,直到2023年LLaVA[18]和MiniGPT-4[20]的出现,VLGFM相关研究才开始成形。现有大多数对话式VLGFMs均基于这两项工作的开源框架实现。自2023年6月起,首批VLGFMs开始涌现。其中,RemoteCLIP[22]是首个对比式VLGFM,支持图像场景分类和图文检索任务;RSGPT[24]是首个对话式VLGFM,支持图像描述和视觉问答任务;RS5M[23]是首个公开的百万规模遥感图文对数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









