




遥感基础模型,特别是视觉与多模态模型的快速发展,显著提升了地理空间数据智能解译的能力。这些模型融合了光学、雷达与激光雷达影像、文本及地理信息等多种数据模态,使得对遥感数据的分析与理解更为全面。多模态融合有效提升了目标检测、土地覆盖分类和变化检测等任务的性能,这些任务常因遥感数据复杂异构的特性而面临挑战。
然而,尽管取得了这些进展,仍存在诸多挑战。数据类型的多样性、大规模标注数据集的需求以及多模态融合技术的复杂性,均对这些模型的有效部署构成显著障碍。此外,训练和微调多模态模型所需的高计算资源,进一步增加了其在遥感图像解译任务中实际应用的难度。
本文全面综述了面向遥感的视觉及多模态基础模型的最新进展,重点探讨了其模型架构、训练方法、数据集与应用场景。我们分析了这些模型面临的关键挑战,如数据对齐、跨模态迁移学习和可扩展性,并指出了旨在突破当前局限的新兴研究方向。本文旨在清晰呈现遥感基础模型的发展现状,并为推动该类模型在实际应用中实现更大突破提供研究启发。本文所汇集的资源列表详见:https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models。
Introduction
近年来,深度学习与人工智能领域的显著进展已使这些技术成为遥感智能解译的核心工具。深度学习已被广泛应用于多种地理空间任务,如场景分类[1]–[5]、目标检测[6]–[10]、变化检测[11]–[13]、土地覆盖分类[14]–[17]以及地理空间定位[18]–[20]。然而,当前大多数模型专为特定任务设计,具有高度任务导向的架构[21]、损失函数[22]和训练策略[23]。这种高度专业化严重限制了模型的泛化能力,即使在紧密相关的任务之间也是如此[24]。此外,这些模型未能充分利用海量可用的遥感数据,导致泛化能力不足,实际应用性能下降。
随着自监督和多模态学习的快速发展,基础模型的兴起从根本上重塑了人工智能的格局。本文中,基础模型指通过自监督、半监督或多模态学习等技术在广泛数据集上预训练,以提取通用特征,并可通过微调或提示调优高效适配多种下游任务的深度学习模型。借助庞大参数和全面数据,这些模型不仅在自然语言处理(如GPT系列、LLaMA等大语言模型)中取得革命性进展,还在计算机视觉等领域展现出卓越的泛化能力,从而推动了人工智能的应用。
基础模型最初通过GPT[25]–[27]、LLaMA[28]等大语言模型(LLMs)在自然语言处理(NLP)中普及。这些模型采用多阶段训练,凭借数十亿参数和海量文本数据,在语言理解、文本生成和机器翻译等任务中实现最先进性能,并在零样本和少样本学习中展示出泛化能力[29]。在视觉任务中,DINOv2[30]等基础模型通过自监督学习在不同网络规模数据集上训练,实现有效的零样本图像检索;SAM[31]采用半监督训练流程开发了基于提示分割的高可靠性基础模型。然而,由于视觉任务的复杂性和多样性,这些模型仍需额外微调或任务特定模块以适应下游任务[32][33]。视觉-语言模型(VLMs)(如CLIP[34]和Grounding DINO[35])实现文本与图像数据的广泛对齐,使模型能通过文本提示执行零样本推理。多模态大语言模型(MLLMs)(如GPT-4V[36])将图像和文本转换为统一令牌序列进行一致处理,从而更灵活地处理各种下游任务。
遥感数据为智能解译带来独特挑战。标注数据稀缺和遥感任务的专业要求历来限制深度学习模型在该领域的性能[19][37]。图像解译是遥感核心任务,使视觉和多模态基础模型成为最主流研究方向。现有研究通常通过融入遥感解译相关的任务特定数据、结构和训练策略来适配通用模型。视觉基础模型基于传统卷积神经网络(CNNs)和Transformer架构,结合针对遥感场景的增强设计,通过 specialized 预训练任务和模型架构更有效从高分辨率图像提取视觉表示[38]。多模态基础模型整合视觉和文本数据,为遥感任务提供新解决方案。基于CLIP的VLM模型将遥感图像映射到文本描述,通过文本提示实现场景分类和检索[37];同时,利用MLLM架构的多模态模型支持更广泛任务,展示出增强的泛化能力。
为全面理解遥感基础模型现状,本综述系统回顾最新进展,识别关键挑战并 outline 未来研究方向。与以往关注特定任务或阶段的综述不同,本研究采用全面视角,**考察基础模型的架构、训练方法、数据利用和应用场景。**本综述的主要贡献如下:
全面综述:首次 dedicated 对遥感基础模型进行全面综述,涵盖视觉和多模态方法,系统回顾其演进、技术创新和关键成就。
创新分类法:引入新颖组织框架,从模型架构和主要功能两个角度对研究进行分类,提供对 various 方法发展、互连和适用性的结构化理解。
资源汇编:为支持持续研究,汇编并维护专用资源库,包括精选论文、排行榜和开源代码,促进领域合作与创新。
模型架构、训练方法和数据集构成深度学习的三个基本支柱,共同塑造训练模型的泛化能力。认识到其 critical 重要性,本综述采用以这三个维度为中心的分类法,系统分析遥感基础模型的最新进展,为研究人员开发更有效、稳健的遥感基础模型提供全面参考。在此框架内,我们 thorough 检查视觉和多模态模型的主要改进方向,详细说明 each 采用的具体优化策略。此外,我们综合现有基础模型的评估方法和结果,提供对其优势和局限的整体理解。本文的组织和分类如图1所示。本综述的组织如下:第二部分讨论模型架构;第三部分探讨训练方法的进展;第四部分深入探讨训练数据集的构建和利用;第五部分呈现评估基准和相应结果。最后,我们在第六部分总结关键挑战和未来研究方向。
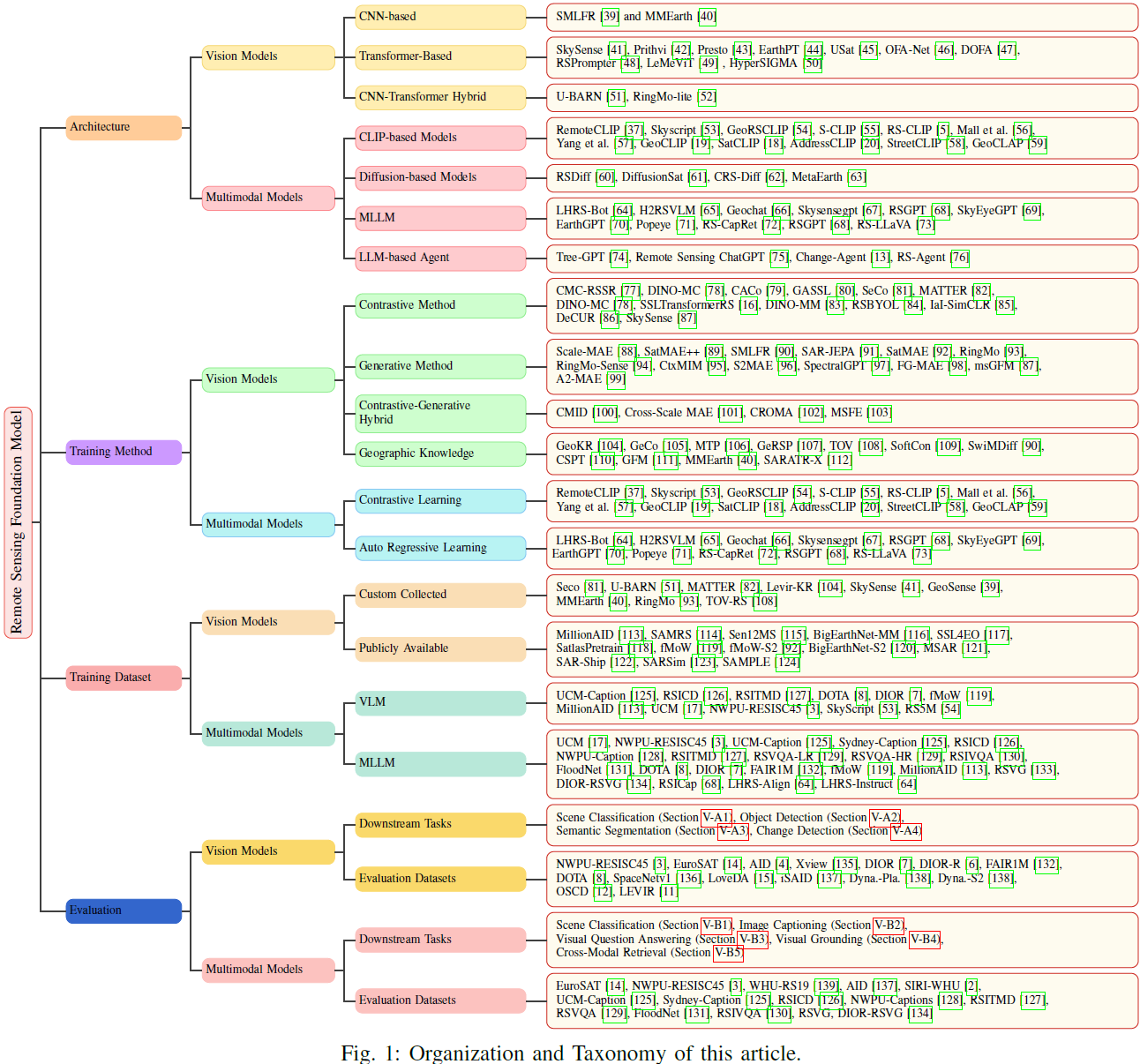
2. Model Architecture 模型架构
2.1 Vision Foundation Model
深度学习技术已在众多遥感图像处理任务中展现出显著进展,涵盖图像分类[140][141]、目标检测[142][143]和语义分割[144][145],这主要得益于其强大的判别性特征学习能力。然而,这些突破性成果依赖于大规模标注数据集的可用性。遥感图像固有的多源性与多分辨率特性构成了巨大挑战。因此,当无法获取大规模标注遥感数据集时,基于自然图像预训练的模型在下游任务微调中往往表现欠佳。
为应对这一挑战,专为遥感图像定制的基础模型概念应运而生,其旨在充分利用海量未标注遥感数据的潜力。与仅在自然图像上预训练的模型相比,这些 specialized 模型在从遥感图像中提取相关特征方面展现出更强的能力,从而在下游应用中取得更为 promising 的成果。
这些基础模型的架构框架可分为三大类别:基于CNN的模型[39][146]、基于Transformer的模型[41][43]以及融合CNN与Transformer组件的混合模型[51][52]。下文将逐一详述各类别。
1) 基于CNN的模型
CNN最初于1980年代被提出[147],其灵感来源于猫的视觉皮层结构[148]。在关键的2012年,ImageNet竞赛[149]以在图像分类上取得前所未有的准确率,将CNN载入了计算机视觉的史册。这一突破引发了CNN的广泛采用和发展,随后的创新,如2016年的ResNet[150],通过残差连接显著增强了模型深度,从而在大规模自然图像数据集上的性能边界被不断推进。
借助这一势头,早期的遥感研究[81], [151]自然地倾向于使用CNN,ResNet[150]和YOLO[152]等框架占据了重要地位。然而,尽管CNN具有相当大的潜力,其固有的架构限制和有限的参数容量在将基于CNN的方法扩展到处理大规模数据集时带来了重大挑战。
为了提升CNN在大规模数据上的性能,研究人员引入了如ConvNeXt[153]和ConvNeXtv2[154]等架构。ConvNeXt旨在将视觉Transformer(ViT)[155]的设计理念融入ResNet架构,从而提升了基于CNN的模型在大规模数据集上的可扩展性。受Transformer在基于掩码的表示学习中的成功启发,ConvNeXtv2经过重新设计,利用稀疏卷积以更好地与掩码自动编码器(MAE)框架对齐。因此,已有若干研究将这些架构应用于遥感领域,包括SMLFR[39]和MMEarth[40]。SMLFR[39]采用ConvNeXt作为其视觉编码器,并配备了一个由三个连续解码器块和两个上采样层组成的轻量级解码器。MMEarth[40]采用了ConvNeXt V2架构,该架构利用稀疏卷积[156]来提高效率。这两种方法与基于Transformer的方法相比都展示了有竞争力的结果。这些发现强调了采用ConvNeXt作为骨干网络的基础模型在推进遥感基础模型方面的前景。
2)基于Transformer的模型:近年来,Transformer架构因其在模型规模和数据集体量上的出色可扩展性而迅速流行。ViT[155]通过将图像块视为令牌序列,将原始的Transformer设计[157]扩展到图像处理。传统的ViT在整个网络中保持令牌数量和令牌特征维度的固定,这限制了性能。为克服此问题,PVT[158]和Swin Transformer[159]等密集预测模型引入了多尺度架构,在小目标检测和分割等细粒度任务中表现出色。此外,基于Transformer的模型在各个领域的成功[160]–[162]凸显了其在大规模预训练方面相对于CNN的优势,使得基于Transformer的架构成为许多遥感图像基础模型的自然选择。
在遥感领域,大多数基础模型[83], [110]采用ViT或Swin Transformer作为其骨干网络。一些研究还探索了先进的ViT变体以进一步提升性能。例如,SARATR-X[112]采用了HiViT[163],该模型融合了Swin Transformer的优势并支持补丁丢弃,以促进掩码图像建模。LeMeViT[49]集成了可学习的元令牌,以用最少的可学习令牌高效地压缩图像表示。在SAM[31]成功的基础上,RSPrompter[48]采用了SAM中的提示学习策略,以生成针对遥感影像的语义上独特的分割提示。EarthPT[44]改编了GPT-2框架,用多层感知机替换了传统的词嵌入,以有效编码非文本数据,从而扩展了其在遥感任务中的通用性。
为了推进基于Transformer的模型,研究人员越来越多地探索多分支架构以增强特征多样性,有效应对多模态融合和细粒度细节提取等挑战。鉴于模态间的固有差异,使用单一编码器处理来自不同来源的特征仍然是一个重大挑战。为解决这一局限性,一些多模态基础模型[16], [41], [86], [102]采用了模态特定的编码器,在后期阶段整合提取的特征。 除了模态分离,许多方法利用多分支设计来提取更复杂和互补的特征。CtxMIM[95]引入了一个上下文增强分支和一个重建分支,以缓解上下文缺失的问题。这种设计将空间特征提取与特征融合分离,使得来自模态、时间及地理上下文的线索得以整合。此外,RS-DFM[164]引入了一个双分支信息压缩模块,旨在分离高频和低频特征。这种方法有助于实现高效的特征级压缩,同时保留关键的与任务无关的信息。BFM[165]探索了多头自注意力和前馈网络的并行配置,以提升视觉相关任务的性能,特别是那些需要精细空间理解的任务,如目标检测和分割。 此外,许多方法专门针对Transformer的组件(如注意力机制和补丁编码)进行了定制,以更准确地捕捉相关的地理特征。
注意力机制是Transformer架构的基石。各种方法致力于在遥感基础模型中精炼注意力机制,以增强特征提取或优化性能。在特征提取方面,HyperSIGMA[50]提出了一种创新的稀疏采样注意力机制,旨在解决高光谱图像中的光谱和空间冗余挑战。该机制能够提取多样化的上下文特征,并作为HyperSIGMA的核心组件,旨在解决高光谱图像在特征利用方面的局限性。尽管高光谱图像具有丰富的光谱信息,但传统上它们仅限于狭窄的特定任务应用。RingMo-Aerial[38]提出了频率增强的多头自注意力,以解决遥感影像中因倾斜角度导致的多尺度变化和遮挡问题。在效率方面,RVSA[166]引入了一种新颖的旋转变尺寸窗口注意力机制,以取代Transformer中的传统全注意力,显著降低了计算开销和内存消耗。同时,它通过从其产生的多样化窗口中提取丰富的上下文信息,增强了对象表示。LeMeViT[49]提出了双重交叉注意力,以实现该框架内图像令牌与元令牌之间的无缝信息交换,与自注意力机制相比,显著降低了计算复杂度。
基于Transformer的模型需要将图像转换为补丁嵌入(patch embedding),然后输入到后续的Transformer模块中。对于多模态模型,通常使用多个独立的补丁嵌入层来生成不同模态的补丁嵌入[46], [87]。DOFA[47]引入了一个波长条件的动态补丁嵌入层,以统一各种地球观测模态的输入。因此,可以在不同的数据模态上训练统一的网络架构。SpectralEarth[167]使用了4×4的补丁而非标准的16×16补丁,在补丁投影层保留了精细的空间细节并增强了光谱信息的保留。
位置编码在基于Transformer的模型中起着至关重要的作用,为输入数据提供空间和结构上下文。许多遥感基础模型的研究调整了位置嵌入,以适应在遥感图像上的预训练。SatMAE[92]引入了针对时间/光谱维度的位置编码,并独立地在时间/光谱维度上掩码补丁,这使得模型能够学习到更有利于微调的数据表示。Scale-MAE [88] 通过将位置编码相对于图像所覆盖的地面区域进行缩放,将其扩展以包含地面采样距离(GSD)。Prithvi [42] 将三维位置嵌入(3D positional embeddings)和三维补丁嵌入(3D patch embeddings)引入ViT框架,使模型能够处理时空数据。USat [45] 修改了补丁投影层和位置编码,以对来自多个传感器的不同空间尺度的光谱波段进行建模。这种方法显著减少了序列长度,从而降低了内存占用和运行时间,同时保持了来自不同传感器图像的地理空间对齐性。为了赋予模型更强的多维感知能力,MA3E [168] 在补丁中添加了角度嵌入(angle embeddings),使模型能够感知补丁的角度。
3)CNN-Transformer 混合模型:为了利用 CNN 和 Transformer 各自的互补优势,近期的研究方法通过结合这两种架构,利用 CNN 进行高效的局部特征提取,同时利用 Transformer 捕捉全局上下文和长距离依赖关系。U-BARN [51] 将 U-Net 与 Transformer 架构相结合,以处理数据的空间、光谱和时间维度,有效捕捉不规则采样的多变量卫星图像时间序列中蕴含的时空信息。遥感影像中高频与低频光谱成分之间复杂的相互作用,限制了传统 CNN 和 ViT 的有效性。RingMo-Sense [94] 采用 Video Swin Transformer 作为其骨干网络,并利用转置卷积层在空间和时间维度上对特征进行上采样。SatMAE++ [89] 使用基于 CNN 的收缩-上采样模块,在多尺度重建过程中提升特征的空间分辨率。RingMo-lite [52] 利用 Transformer 模块作为低通滤波器,通过双分支结构提取遥感图像的全局特征,同时结合 CNN 模块作为堆叠的高通滤波器,以有效捕捉细粒度细节。这种成功的实现方式构建了一个轻量级网络,在各种下游遥感任务中均取得了优异的性能。OmniSat [169] 采用基于 CNN 的编码器-解码器处理图像数据,并使用轻量级的时间注意力编码器 [170] 处理时间序列数据,使其与数据的固有特性相匹配。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9217
9217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









