




DeepSeek-VL: Towards Real-World Vision-Language Understanding原文链接:
https://arxiv.org/pdf/2403.05525
主要贡献
高分辨率视觉编码:1024 x 1024分辨率
三阶段训练方式
模态热身策略
主要架构
主要架构分为三部分:
A hybrid vision encoder, a vision adaptor, and a language model.
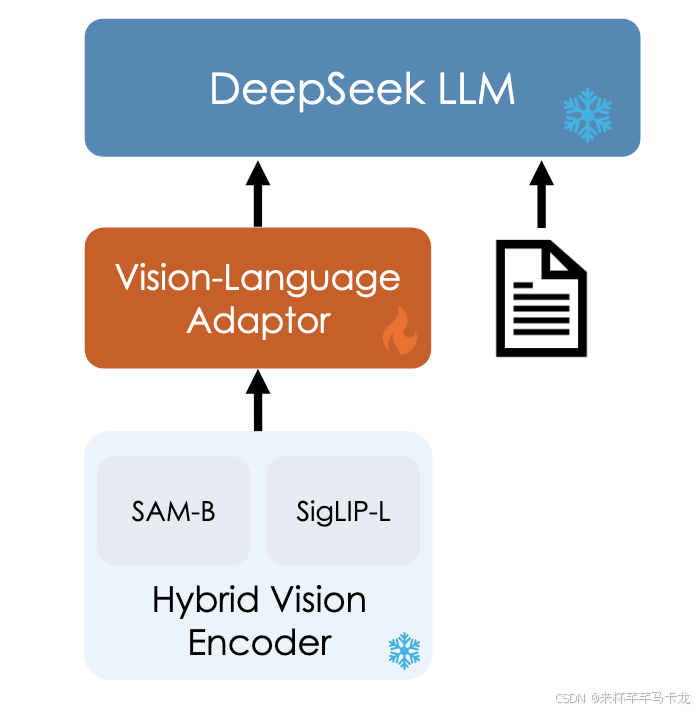
hybrid vision encoder
采用SigLIP作为视觉编码器来提取视觉输入的高级特征表示。然而,一个单独的SigLIP编码器很难解决现实世界的问题,受模糊的编码影响,导致视觉上不同的图像被编码为相似,CLIP家族受其相对较低的分辨率输入的限制(例如224 x 224,336 x 336,384 x 384,512 x 512),这阻碍了他们处理任务的能力,该任务需要更详细的低级别功能,例如密集的OCR和视觉接地任务。
为了处理高分辨率的低级特征,利用SAM-B处理1024 x 1024的高分辨率图像输入,还保留了具有低分辨率384 x 384图像输入的Siglip-L视觉编码器,因此,混合视觉编码器结合了SAM-B和Siglip-L编码器,有效地编码了高分辨率1024 x 1024图像,同时保留语义和详细信息。
Vision-Language Adaptor
使用两层混合MLP来桥接视觉编码器和LLM,最初,不同的单层MLP用于分别处理高分辨率特征和低分辨率功能。随后,这些特征沿其尺寸连接,然后通过另一层MLP转换为LLM的输入空间。
Language Model
语言模型建立在DeepSeek LLM的基础之上,采用Pre-Norm结构(即在每一层的输入之前进行归一化操作,而不是在输出之后进行归一化(Post-Norm)。Pre-Norm 结构在近年来被广泛应用于Transformer模型及其变体中,因为它能够有效缓解梯度消失问题,并提升训练的稳定性),使用RMSNorm作为归一化函数,并且使用SwiGLU作为前馈网络的激活函数,采用旋转嵌入作为位置编码,使用与DeepSeek-LLM相同的to
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









