




视觉语言建模(VLM)致力于弥合图像与自然语言之间的信息鸿沟。通过"先在海量图文对上预训练,再针对特定任务微调"的新范式,遥感(RS)领域的VLM取得了显著进展。该范式使模型能够吸收海量通用知识,在多种遥感数据分析任务中展现出色性能,并具备以对话方式与用户交互的能力。本文旨在为遥感学界提供关于两阶段范式VLM发展的及时全面综述:首先建立遥感VLM的技术体系——对比学习、视觉指令微调与文本条件图像生成三大方向,逐类详解常用网络架构与预训练目标;其次系统评述现有工作,包括基于对比的VLM中的基础模型与任务适配方法、基于指令的VLM中的架构升级与训练策略、生成式基础模型及其典型应用;进而汇总VLM预训练、微调与评估数据集,分析其构建方法(如图像来源与标注生成)和规模、任务适应性等关键特性;最后提出未来研究方向:跨模态表征对齐、模糊需求理解、解释驱动的模型可靠性、持续可扩展能力,以及涵盖更丰富模态与更大挑战的大规模数据集。
现有VLM诞生的新范式:先预训练,后微调,a new paradigm of pretraining followed by fine-tuning
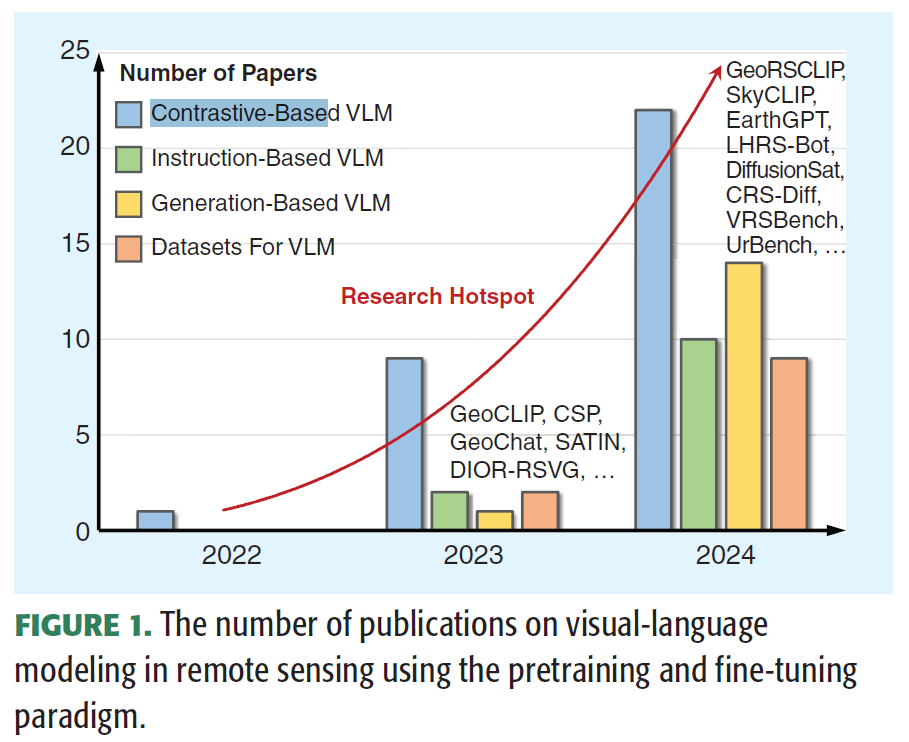
To date, significant progress has been achieved, as illustrated in Figure 1. This includes works based on the following:
1)对比学习 such as GeoRSCLIP [15], SkyCLIP [16], and RemoteCLIP [20], which have driven substantial advancements in various cross-modal tasks and、zero-shot image understanding tasks;(称之为 Contrastive-Based VLM)
2)从文本prompts生成图像,学习图像和文本的implicit的联合分布:like RS-SD [15], DiffusionSat [21], and CRSDiff [22] (称之为Generation-Based VLM)
3) 视觉指令微调,such as GeoChat [18], LHRS-Bot [24], and SkySenseGPT [25](称之为Instruction-Based VLM)
本文的贡献 focus on VLM based on the pretraining and fine-tuning paradigm in the field of remote sensing.
1. 遥感视觉语言模型(VLM)的技术体系分类,逐类详解常用网络架构与预训练目标;
2. 对比式、指令式与生成式三类遥感VLM的最新进展,重点阐释其关键设计与下游应用;
3. VLM预训练、微调及评估数据集的建设进展;
4. 当前技术挑战与潜在研究方向
遥感VLM的分类:对比学习,视觉指令微调,文本引导的图像生成
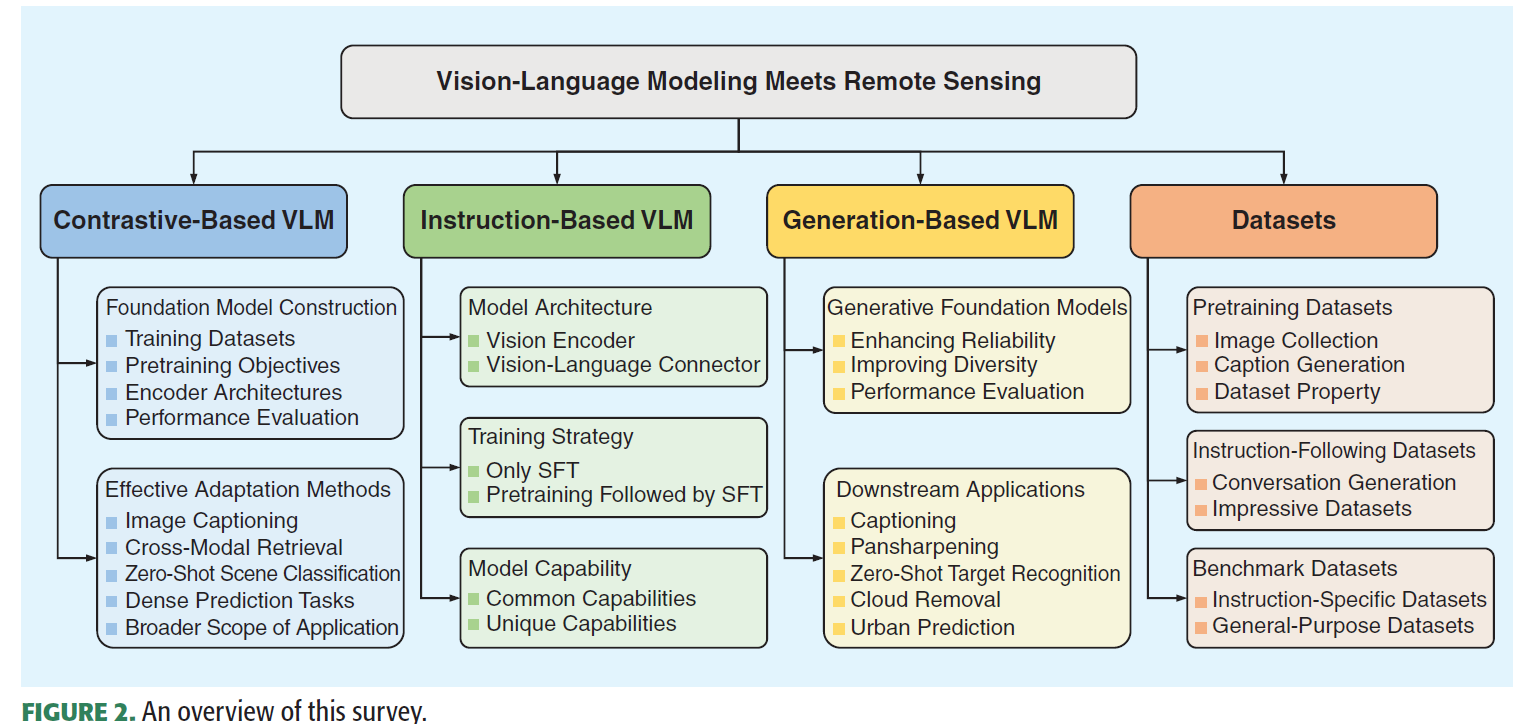
contrastive learning
对比学习的出发点是将文本与图像建模在一个统一共享的特征空间,让同一文本对的特征尽可能相似,而让不同文本对的特征尽可能不同。最先的工作是CLIP,使用对比学习InfoNCE loss最大化同一个图像文本对的cosine similarity,最小化不同图像文本对的cosine similarity
CLIP这些突破性进展激发了学界拓展其能力以推进遥感视觉语言模型(VLM)发展的研究兴趣。目前主要存在两条技术路线:其一遵循CLIP学习范式,专注于预训练任务无关但专门适配遥感领域的基础模型,包括构建大规模图文数据集[15][16]及开发新型预训练目标[33][34];其二探索预训练CLIP模型在多类下游任务中的高效适配,涵盖图像描述生成[35][36]、零样本场景分类[37][38]、图文检索[39][40]等方向。
Visual Instruction Tuning
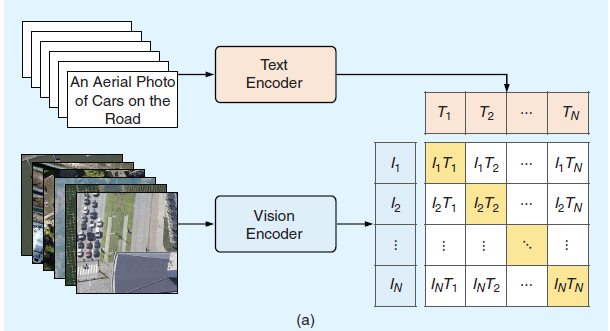
由于需要海量数据与算力支撑,从头开始优化图像-文本对齐模型的成本极高。值得庆幸的是,当前已有大量预训练视觉编码器与语言模型发布:预训练视觉编码器能提供高质量视觉表征,而预训练语言模型(尤其是大语言模型LLMs)展现出卓越的语言理解能力。因此,越来越多的研究开始借鉴LLaVA[23]和MiniGPT-4[41]提出的视觉指令微调方法,利用这些现成模型实现图像-文本对齐。图3(b)展示了此类工作的典型网络架构,包含三个核心组件:预训练视觉编码器、连接器与LLM。具体而言,视觉编码器将遥感图像压缩为紧凑的视觉表征,连接器将图像嵌入映射至LLM的词嵌入空间,LLM则同步接收视觉信息与语言指令以执行推理任务。与CLIP直接输入图像-文本对不同,该方法将图文对预处理为指令跟随数据——每张图像配有问题或语言指令,要求LLM描述图像内容,而对应文本则作为LLM预测的真值标签。
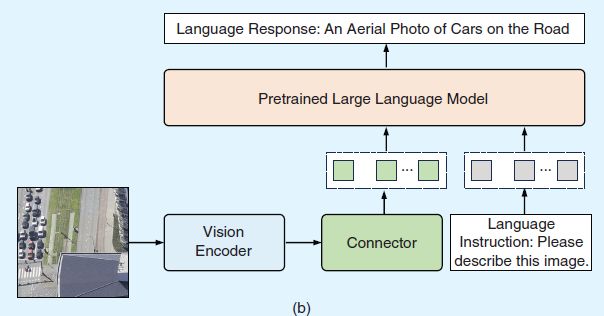
在预训练阶段,视觉编码器与大语言模型(LLM)通常保持冻结状态,仅对连接器参数进行训练。LLaVA[23]与MiniGPT-4[41]的研究表明,视觉指令微调预训练能在保持广泛知识的前提下实现视觉-语言表征的对齐。此后,研究者通过改进网络架构[24][42]和构建高质量预训练数据集持续推进该领域发展。除提升对齐效果外,另一研究方向聚焦于有监督微调(SFT),旨在使模型能执行多样化遥感图像分析任务并以对话方式与用户交互,具体包括:生成任务特定的指令跟随数据[18][25][43]、设计新型训练策略[42][44]以及集成前沿视觉编码器[44]。
Text-conditioned Image Generation
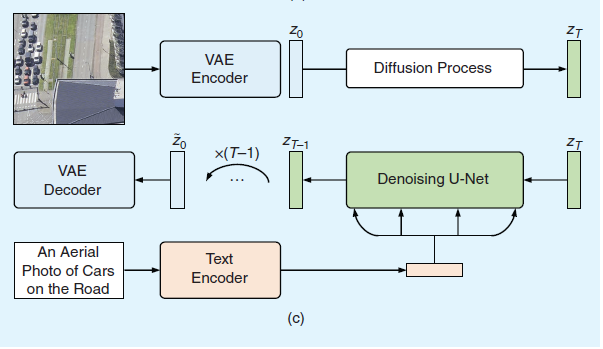
鉴于本文聚焦于采用扩散模型的视觉语言建模(VLM)研究,我们未试图涵盖其在遥感任务中的所有应用实例,而是重点探讨将文本条件与扩散模型相融合的代表性工作。关于扩散模型在遥感领域进展的更全面综述,请参阅文献[46]。
基于前述基本原理,当前形成两大研究方向:其一致力于开发面向多类遥感图像的生成式基础模型,涵盖卫星图像[21]、航空影像[47]、高光谱图像[48]及多分辨率图像[49];其二则将文本条件扩散模型拓展至特定遥感任务,如图像描述与变化描述生成[50][51]、全色锐化[52]以及零样本目标识别[53]等。
Contrastive-Based VLM
当前大多数视觉语言模型(VLM)研究集中于对比学习方向。如前所述,该领域主要存在两个重点研究方向:基础模型构建与高效任务适配。具体而言,基础模型构建致力于解决自然图像与遥感图像间的巨大域差异,其目标是学习蕴含丰富遥感场景语义、且与文本表征精确对齐的视觉表征;而高效适配则探索如何将预训练CLIP模型有效应用于特定遥感任务。后续章节将分别从这两个方向对现有研究进行系统性分析。
基础模型构建
表格1总结了基于对比学习的遥感VLM。为了构建基础模型,三个核心部件需要精心设计,训练数据集,预训练目标,和编码器结构。
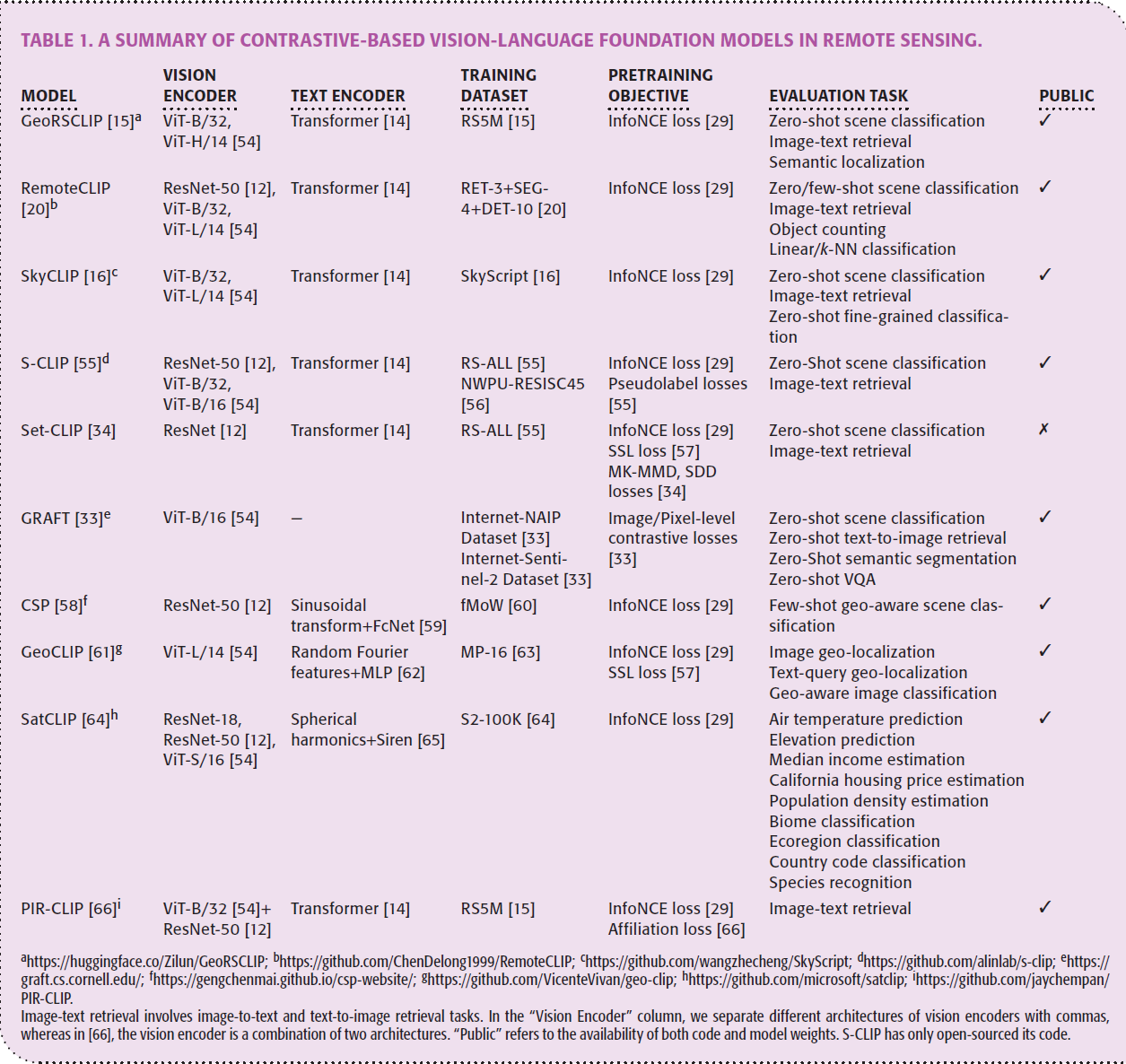
Training Datasets 训练数据集
大规模图文数据集是构建基础模型的基石。现有遥感领域的现成图文数据集(如UCM-captions和Sydney-captions)存在数据量有限与图像多样性不足的缺陷,难以支撑预训练模型获取领域通用知识。鉴于众多遥感图像数据集的可获得性,文献[15]与[20]采用开源数据集作为图像源,并开发图像描述生成方法以产生对应文本标注。值得注意的是,[15]通过遥感相关关键词筛选11个常用图文数据集,并借助调优后的BLIP2模型[69]对Million-AID[67]、fMoW[60]和BigEarthNet[68]三大遥感图像数据集进行标注,最终构建包含超500万图文对的RS5M数据集。现成的视觉语言模型虽因其可用性与易用性成为构建大规模图文数据的强大工具,但确保标注准确性仍是重大挑战。为此,[20]提出基于规则的掩码转边界框(M2B)与边界框转描述(B2C)方法,将像素级或边界框标注转化为自然语言描述。
另一关键问题在于生成描述的语义多样性受限于开源遥感数据集中预定义类别的有限性。鉴于此,Wang等学者[16]尝试利用OpenStreetMap(OSM)蕴含的丰富语义信息,使文本描述不仅能涵盖多样化的对象类别,还可包含细粒度子类别与对象属性。与[20]类似,该方法遵循预定义规则从对象标签中组合生成描述。
Pretraining Objectives 预训练目标
表格1中总结了不同的预训练损失函数,除了最经典的对比InfoNCE loss之外,一些研究人员还提出了新的预训练损失。例如S-CLIP [55] introduces caption-level and keyword-level pseudolabels to fine-tune the original CLIP model on massive unpaired remote sensing images alongside a few image-text pairs.
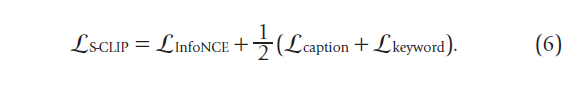
Set-CLIP [34] transforms the representation alignment between images and texts into a manifold matching problem,提出了Multikernel Maximum Mean Discrepancy Loss (L_MK-MMD) 和 semantic density distribution loss (L_SDD),此外,还引入了通过增强手段的自监督损失L_SSL.
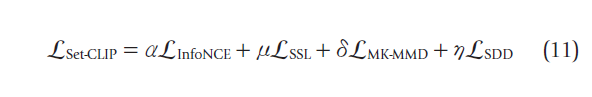
即便小规模图文数据集的构建也需要专业知识来生成文本描述。为彻底避免文本标注工作,GRAFT [33] 提出利用共位地面图像作为卫星影像与自然语言之间的桥梁。通过这种方法,研究团队收集了包含200万组地面对卫星图像配对的数据集,基于此,研究者设计了一个特征提取器,将卫星影像映射至CLIP模型的表征空间,由于单张卫星影像xi可能覆盖较大地面区域,因而可与多张地面图像gij建立关联,并构建了L_GRAFT损失。
Encoder Architectures 编码器架构
与自然图像通常由文本描述内容不同,遥感图像的文本信息可通过地理坐标(经度与纬度)表征,这种表征对场景分类和目标识别等任务具有显著价值[60]。因此,部分研究提出将遥感图像与其地理坐标的表征进行对齐,并特别关注位置编码器的选择[58][61][64]。位置编码器通常由非参数函数式位置编码与小型神经网络构成:CSP[58]采用现有二维位置编码器——即文献[59]提出的Space2Vec网格编码,该编码器通过正弦变换将图像坐标映射为高维表征,再经全连接ReLU层处理;GeoCLIP[61]则先对图像坐标施加等距地球投影以降低标准地理坐标系的固有畸变,继而采用随机傅里叶特征[62]捕捉高频细节,通过频率变化构建分层表征,这些分层表征经独立的多层感知机(MLP)处理后再进行元素加操作,最终生成联合表征,该设计使位置编码器能有效捕捉多尺度下的地理位置特征;SatCLIP[64]采用结合球谐基函数与正弦表示网络的位置编码器,将地理坐标映射为潜在表征[65]。
除适配不同类型文本信息外,编码器调整的另一目的在于提升视觉概念的表征质量。遥感图像通常覆盖广阔视场且包含多样地物,但其文本描述往往聚焦于特定目标及其空间关系。图像中的语义噪声(如无关物体与背景干扰)会阻碍关键内容的表征,从而破坏图文表征的对齐。文献[66]通过引入遥感场景先验知识指导预训练模型,在计算图文嵌入相似度前滤除语义噪声:具体通过在视觉编码器顶端增置指令编码器与Transformer编码层实现——指令编码器在场景分类数据集AID[70]上预训练后生成指令嵌入,通过软置信策略过滤图像嵌入;经滤波的嵌入再通过Transformer编码层结合指令信息激活,最终生成用于后续对齐的相关图像嵌入。
Performance Evaluation 性能评估
零样本场景分类,图像文本跨模态检索 是评估遥感VLM的广泛使用的任务。Zero-shot scene classification and image-text retrieval
Effective Adaptation Methods 有效适应方法
受基础模型卓越性能的启发,研究者已开发出多种方法将预训练模型有效适配于特定遥感任务,包括图像描述生成、跨模态检索、零样本分类、密集预测等。本节将结合表3的总结,系统阐述不同下游任务背景下适配方法的发展进展。
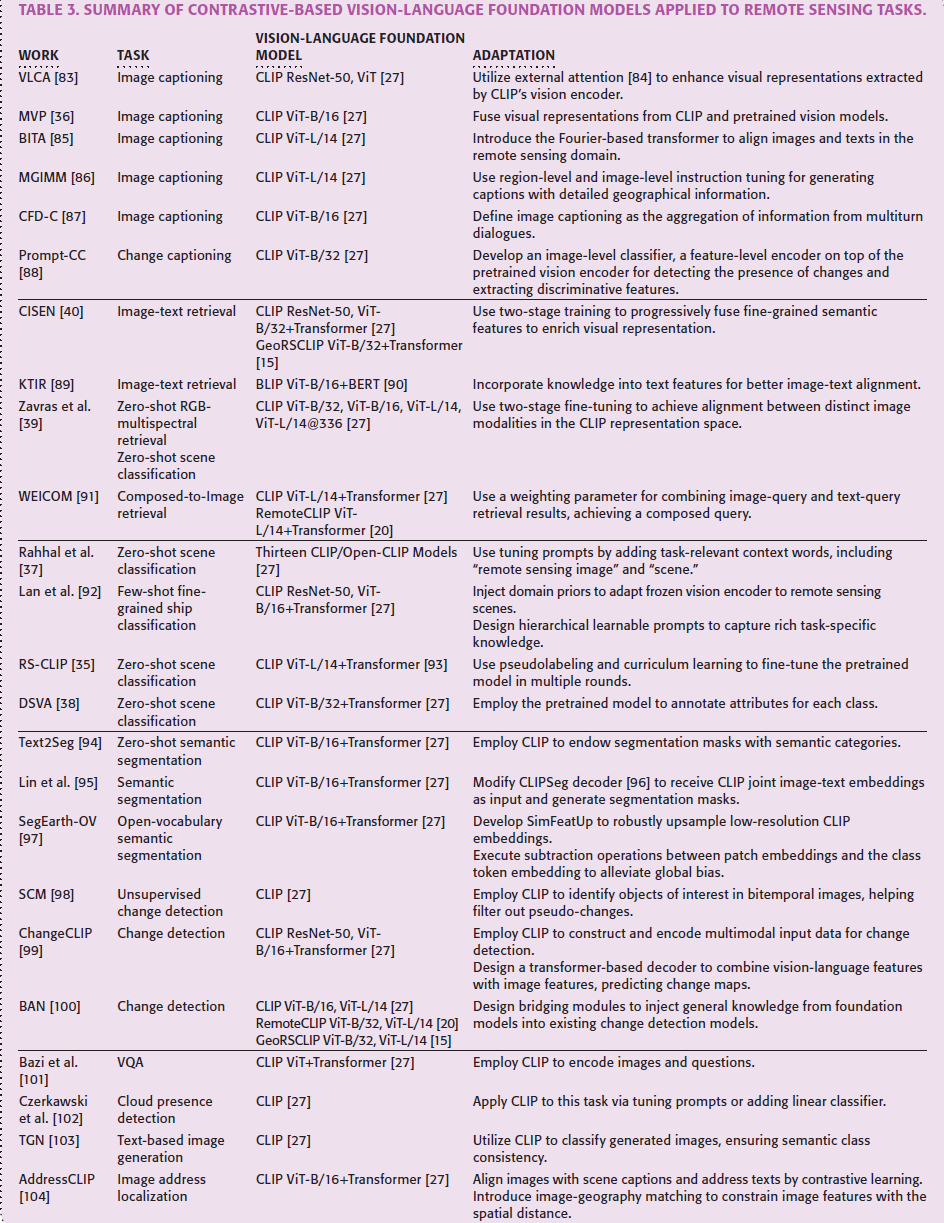
image captioning
图像描述生成旨在通过自然语言描述给定图像的内容。视觉-语言基础模型因其能对齐图文表征而特别适合此项任务:研究者可利用模型的视觉编码器提取图像内容表征,为语言模型生成描述提供输入准备[36][83][85]。当前遥感图像描述任务中,视觉编码器多采用CLIP架构,而语言模型则涵盖GPT-2[105]、BERT[106]与OPT[107]等。为提升描述准确性,部分研究致力于增强模型的视觉表征能力或进一步促进图文对齐。
以表征增强为例,VLCA[83]引入外部注意力机制[84]以捕捉不同图像间的潜在关联,从而提升视觉表征质量;MVP[36]通过堆叠Transformer编码器融合来自预训练视觉-语言模型与预训练视觉模型的视觉表征,并利用CLIP视觉编码器配合自适应平均池化层生成视觉前缀(visual prefixes),将其与词元嵌入进行拼接后,开发基于BERT的描述生成器来结合融合视觉表征与拼接嵌入,最终实现准确描述生成。与之相反,BITA[85]专注于通过交互式傅里叶变换器提升遥感领域图文对齐效果:该架构将可学习视觉提示输入傅里叶层,与预训练视觉编码器的图像嵌入进行交互,从而捕捉最相关的视觉表征;通过对比学习使这些视觉表征与同样由傅里叶变换器提取的文本表征对齐;最终该交互式傅里叶变换器连接冻结的视觉编码器与语言模型,充分发挥语言模型的生成与推理能力。
除提升描述准确性外,生成精细化描述也成为研究重点[86][87]。文献[86]提出两阶段指令微调方法优化视觉-语言映射层,以生成地理细节丰富的描述:第一阶段以指令"[region]基于遥感图像指定区域,描述该区域内主要对象的基本属性"为指导,实现地理对象区域与其属性描述的对齐;第二阶段通过指令"[image]请提供该图像的详细描述"聚焦地理对象空间分布的理解。文献[87]将图像描述定义为多轮对话信息聚合任务,每轮对话用于查询图像内容:CLIP视觉编码器逐轮提取图像特征,与历史问答对及当前问题共同输入自回归语言模型[105]生成应答;经多轮对话后,由GPT-3[108]汇总对话信息生成增强型文本描述。
与单图像描述不同,Prompt-CC[88]利用预训练模型描述双时相影像间的差异(即变化描述任务):基于CLIP提取的双时相视觉表征,引入图像级分类器检测变化存在性,并通过特征级编码器提取识别具体变化的判别性特征。
cross-modal retrieval
跨模态检索旨在通过一种模态的查询数据检索另一种模态的内容。基于视觉-语言基础模型,当前研究既探索图像与文本间的相互检索[40][89][91],也研究不同成像参数图像间的检索[39]。图文检索面临双重挑战:根据图像查询匹配对应文本描述,或根据文本查询匹配对应图像。现有工作利用预训练编码器分别编码图像与文本,将其映射至共享表征空间进行相似度度量:CISEN[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









