




来源:https://github.com/open-mmlab/MMRazor收录的方法
ICCV 2021:Channel-Wise Knowledge Distillation for Dense Prediction
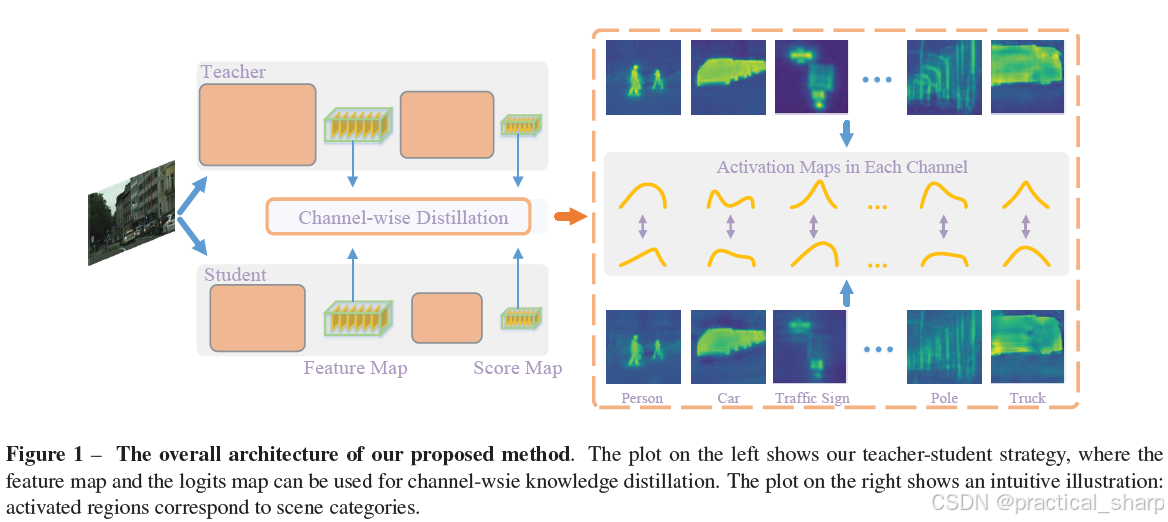
首先,使用1x1卷积将教师模型与学生模型的中间层特征的通道维度进行对齐。
A 1x1 convolution layer is employed to upsample the number of channels for the student network if the number of channels mismatches between the teacher and the student.
然后,对每个通道的WxH的特征进行softmax归一化。

最后,使用KL散度损失来最小化学生特征与教师特征之间的距离

ICLR 2018 Workshop:Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adversarial Networks
Adversarial learning for knowledge distillation can be first found in (Ref. ICLR 2018 Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adversarial Networks).
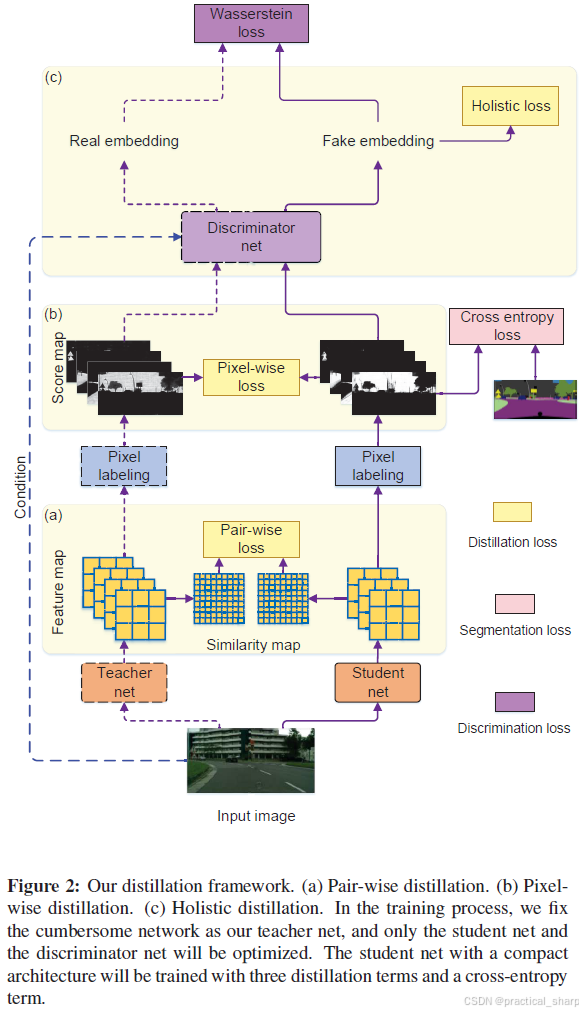
Liu et al. (Ref. CVPR 2019:Structured Knowledge Distillation for Semantic Segmentation) shares the similar idea for semantic segmentation, named holistic distillation. We also leverage the adversarial learning performed in the output space.
Main idea: We propose to use conditional adversarial networks to learn the loss function to transfer knowledge from teacher to student.

CVPR 2019:Structured Knowledge Distillation for Semantic Segmentation
提出从大网络中蒸馏结构化知识到小网络中,structure knowledge
调研了两种结构化知识 (1)pair-wise similarity (2) GAN-based holistic distillation
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









