




 文章介绍了CVR预估模型ESMM,该模型基于Multi-Task Learning,旨在解决样本选择偏差和数据稀疏问题。ESMM通过共享CTR和CVR的嵌入层参数,利用CTR和CTCVR的监督信息隐式学习CVR,以提高模型在全样本空间的泛化能力。
文章介绍了CVR预估模型ESMM,该模型基于Multi-Task Learning,旨在解决样本选择偏差和数据稀疏问题。ESMM通过共享CTR和CVR的嵌入层参数,利用CTR和CTCVR的监督信息隐式学习CVR,以提高模型在全样本空间的泛化能力。
文章基于 Multi-Task Learning 的思路,提出一种新的CVR预估模型——ESMM,有效解决了真实场景中CVR预估面临的数据稀疏以及样本选择偏差这两个关键问题。
Motivation
不同于CTR预估问题,CVR预估面临两个关键问题:
1 样本选择偏差(sample selection bias,SSB):传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例,但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。即传统的推荐系统仅用Xc(click=1的样本集)中的样本来训练CVR预估模型,但训练好的模型是在整个样本空间X(曝光的)去做推断的。
 由于点击事件相对于曝光事件来说要少很多,因此只是样本空间X的一个很小的子集,从Xc上提取的特征相对于从X中提取的特征而言是有偏的,甚至是很不相同。从而,按这种方法构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中独立同分布的假设。这种训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能。conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions
由于点击事件相对于曝光事件来说要少很多,因此只是样本空间X的一个很小的子集,从Xc上提取的特征相对于从X中提取的特征而言是有偏的,甚至是很不相同。从而,按这种方法构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中独立同分布的假设。这种训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能。conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions

2 数据稀疏(data sparsity,DS):推荐系统展现给用户的商品数量要远远大于被用户点击的商品数量,同时有点击行为的用户也仅仅只占所有用户的一小部分,(作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本),因此有点击行为的样本空间Xc相对于整个样本空间X来说是很小的,通常来讲,量级要少1~3个数量级。在淘宝公开的训练数据集上,Xc只占整个样本空间X的4%。这就是所谓的训练数据稀疏的问题,高度稀疏的训练数据使得模型的学习变得相当困难。
一些策略可以缓解这两个问题,例如从曝光集中对unclicked样本抽样做负例缓解SSB,对转化样本过采样缓解DS等。但无论哪种方法,都没有很elegant地从实质上解决上面任一个问题。
CVR预估到底要预估什么
想象一个场景,一个item,由于某些原因,例如在feeds中的展示头图很丑,它被某个user点击的概率很低,但这个item内容本身完美符合这个user的偏好,若user点击进去,那么此item被user转化的概率极高。
CVR预估模型,预估的正是这个转化概率,它与CTR没有绝对的关系,很多人有一个先入为主的认知,即若user对某item的点击概率很低,则user对这个item的转化概率也肯定低,这是不成立的。更准确的说,CVR预估模型的本质,不是预测“item被点击,然后被转化”的概率(CTCVR),而是“假设item被点击,那么它被转化”的概率(CVR)。这就是不能直接使用全部样本训练CVR模型的原因,因为咱们压根不知道这个信息:那些unclicked的item,假设他们被user点击了,它们是否会被转化。如果直接使用0作为它们的label,会很大程度上误导CVR模型的学习。
所以这个新模型能学到什么呢?在某种输入特征下(如包含商品图片很丑的特征),得到很低ctr预估时候,如果也转化了ctcvr=1,那么这部分只能是被cvr学习到一个高值(而且是直接通过X大集合学习到的),此时的cvr表示的就是一旦点击,点击后的转化率很高(不管预估的点击率有多低,转化高就是了)。还能学到的是,如果只用click的样本学习cvr,那么那些低ctr的商品学到的cvr会很不准(因为click的样本经过采样后基本是点击高的商品),新模型可能通过参数共享学的cvr更准。
ESMM模型
认识到点击(CTR)、转化(CVR)、点击然后转化(CTCVR)是三个不同的任务后,我们再来看三者的关联:

其中 z,y 分别表示conversion和click。注意到,在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,这两个任务是可以使用全部样本的。
当无法直接建模pCVR,可以建模学习pCTCVR和pCTR,反向求pCVR的预测,因此ESSM中两个学习的模型是建模CTR和CTCVR的子模型。ESMM正是通过这学习两个任务,再根据上式隐式地学习CVR任务的。
Note: 这里的pCVR可以理解为假设在全域样本上用户会点击,商品的转化率。因为在用户还没点之前,我们就要将商品排好序,只能假设点了之后的CVR,所以直接是无法对pCVR建模的。

Figure 2: Architecture overview of ESMM for CVR modeling. In ESMM, two auxiliary tasks of CTR and CTCVR are introduced which: i) help to model CVR over entire input space, ii) provide feature representation transfer learning. ESMM mainly consists of two sub-networks: CVR network illustrated in the left part of this figure and CTR network in the right part. Embedding parameters of CTR and CVR network are shared. CTCVR takes the product of outputs from CTR and CVR network as the output. pctr预测一个impression的click,pcvr预测一个impression的conversion,pctcvr预测一个impression→click→convrsion的sequence概率。
目标函数:
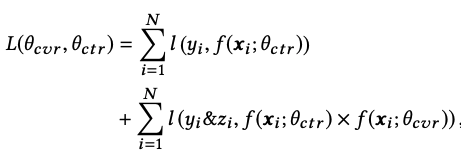
代码实现:
def loss_op(self, task_label=None, task_num=None):
with tf.name_scope("Loss-op"):
self.ctr_loss = tf.reduce_mean(self.loss_func(self.click_label, self.ctr_pred))
self.reg_loss = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
self.reg_loss = tf.reduce_sum(self.reg_loss)
self.cvr_loss = tf.reduce_mean(self.loss_func(self.pay_label, self.ctr_pred * self.cvr_pred))
self.loss = self.ctr_loss + self.cvr_loss + self.reg_loss

1)共享Embedding CVR-task和CTR-task使用相同的特征和特征embedding,即两者从Concatenate之后才学习各自部分独享的参数;CVR与CTR网络共享embeding层参数,这种参数迁移的方式显著降低了CVR模型的数据稀疏问题。说白了就是通过Embedding Layer 共享,把曝光没点击的样本共享给pcvr模型。
2)隐式学习pCVR 。pCVR(粉色节点)仅是网络中的一个variable,没有显示的监督信号。利用CTCVR和CTR的监督信息来训练网络,隐式地学习CVR,这正是ESMM的精华所在。
Note:
1 重点在于 1 共享参数的更新大大减少稀疏性;2 能学习到低预估ctr,但是ctcvr又=1的这种高cvr网络更新。
2 ESMM的结构是基于“乘”的关系设计——pCTCVR=pCVR*pCTR,是不是也可以通过“除”的关系得到pCVR,即 pCVR = pCTCVR / pCTR ?例如分别训练一个CTCVR和CTR模型,然后相除得到pCVR,其实也是可以的,但这有个明显的缺点:真实场景预测出来的pCTR、pCTCVR值都比较小,“除”的方式容易造成数值上的不稳定。
别人的一些思考
缺点
在实际应用中,往往点击、转化的样本非常稀疏,通常曝光到点击率可能只有1%,而且点击到转化可能也只有1%。这样就会造成损失函数的第二部分常常为0.0001量级。按照点击到转化可能也只有1%算的话,大概和第一部分差100倍。这样损失函数的值的大小可能就由第一部分决定了。(不太对)
讨论
1 迁移到其他指标相关场景 click VS share, click VS follow, click VS like
2 正负样本不平衡的问题和处理,是否要采用resampling或reweight等技术。
3 loss function 和 metric不一致的问题,感觉这篇文章与MMoE出发点不一样,而且是有明显先验的
MMoE: 个人理解理解是multi-expert attention Ensemble,expert 的异构、相关性对结果和影响在目前的实验上看与传统机器学习Ensemble的经验一致
ESMM:个人理解从sequence甚至casual 层次去解析多目标的本质关系,当然比较适用于多个目标存在业务场景关系
from: -柚子皮-
ref: 阿里妈妈团队 发表在 SIGIR’2018 的论文,论文地址:https://arxiv.org/pdf/1804.07931.pdf
开源实现:https://github.com/alibaba/x-de
[CVR预估的新思路:完整空间多任务模型]ESMM模型的tensorflow实现请[构建分布式Tensorflow模型系列:CVR预估之ESMM]
[Entire Space Multi-Task Model(ESMM)阅读体会]

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









