




Softmax
softmax函数
Softmax函数是logistic函数的一种泛化。Softmax - 用于多分类神经网络输出。二类分类当然也可以用,但是如果只输出一个神经元可以使用sigmod函数。
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是

也就是说,是该元素的指数,与所有元素指数和的比值。
举个例子来看公式的意思:

就是如果某一个 zj 大过其他 z, 那这个映射的分量就逼近于 1,其他就逼近于 0,主要应用就是多分类。
为什么要取指数?
第一个原因是要模拟 max 的行为,所以要让大的更大;第二个原因是需要一个可导的函数。
被称为 softmax 函数,因为它表示“ max ”函数的一个平滑版本。这是因为,如果对于所有的 j != k 都有 a_k ≫ a_j ,那么 p(C k | x) ≃ 1 且 p(C j | x) ≃ 0 。
通过softmax函数,可以使得P(i)的范围在[0,1]之间。在回归和分类问题中,通常θ是待求参数,通过寻找使得P(i)最大的θi作为最佳参数。
此外Softmax函数同样可用于非线性估计,此时参数θ可根据现实意义使用其他列向量替代。
Softmax函数得到的是一个[0,1]之间的值,且∑Kk=1P(i)=1,这个softmax求出的概率就是真正的概率,换句话说,这个概率等于期望。
带温度T的softmax概率

比之前的softmax多了一个参数T(temperature),T越大产生的概率分布越平滑。
softmax代码实现
1 torch实现
输入输出是tensor
torch实现
torch.softmax(tensor0, dim=-1)
torch.nn.Softmax(dim=-1)(tensor0)
当然tensorflow中也有这个函数。
2 scipy实现
from scipy.special import softmax
a = [1,2,3,4,-3,-4,-2, -10000]
b = softmax(a)
[scipy.special.softmax¶]
3 tf实现
算softmax计算溢出怎么办?
C′ 通常取 −max(ai) 。自己去算softmax,容易出现溢出等问题,最好用官方的实现:如sampled_softmax_loss_v2
基于softmax的各种loss
softmax loss
Softmax loss
Softmax loss是由softmax和交叉熵(cross-entropy loss)loss组合而成,所以全称是softmax with cross-entropy loss。即softmax是激活函数,交叉熵是损失函数,softmax loss是使用了softmax funciton的交叉熵损失。当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。即假如log loss中的p的表现形式是softmax概率的形式,那么交叉熵loss就是softmax loss,所以说softmax loss只是交叉熵的一个特例。
在caffe,tensorflow等开源框架的实现中,直接将两者放在一个层中,而不是分开不同层,可以让数值计算更加稳定,因为正指数概率可能会有非常大的值。
令z是softmax层的输入,f(z)是softmax的输出,则
![]()
batch形式softmax loss
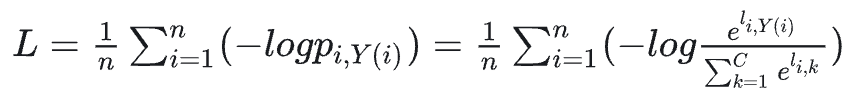
softmax loss的变种和改进
soft softmax

当T=1时,就是softmax的定义,当T>1,就称之为soft softmax,T越大,因为Zk产生的概率差异就会越小。文【2】中提出这个是为了迁移学习,生成软标签,然后将软标签和硬标签同时用于新网络的学习。
Large-Margin Softmax Loss
softmax loss擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。
举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。
作者的实现是通过一个LargeMargin全连接层+softmax loss来共同实现,可参考代码。
softmax loss的各种实现
同样,multi-label是一定不能使用交叉熵作为loss函数的。因为如果是多目标问题,经过softmax就不会得到多个和为1的概率,而且label有多个1也无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。并且它只计算了某个类别标签为1时的loss及梯度,而忽略了为0时的loss,而每个输出又相互独立,不像softmax函数那样有归一化的限制。

















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









