






 SWING是一种基于图结构的推荐算法,旨在通过考虑三角形结构增强节点相似度计算,提高推荐系统的召回率。相较于传统算法如Adamic/Adar和Item-based CF,SWING在处理网络结构变化时更灵敏,但对新用户和商品的冷启动问题存在挑战。通过引入惩罚因子和热门商品打压策略,可以进一步优化精度。SWING在计算复杂度上比Item-based CF更高,但在实际应用中表现出色,广泛应用于电商和音乐平台的推荐系统。
SWING是一种基于图结构的推荐算法,旨在通过考虑三角形结构增强节点相似度计算,提高推荐系统的召回率。相较于传统算法如Adamic/Adar和Item-based CF,SWING在处理网络结构变化时更灵敏,但对新用户和商品的冷启动问题存在挑战。通过引入惩罚因子和热门商品打压策略,可以进一步优化精度。SWING在计算复杂度上比Item-based CF更高,但在实际应用中表现出色,广泛应用于电商和音乐平台的推荐系统。
Link Prediction
现实世界中的网络大部分都可以抽象为两种,一种是user-user这种同质的网络,另一种是user-object。推荐在这两种网络中都可以归为link prediction的范畴,给定一个图G(V, E),V是节点的集合,E是边的集合,推荐其实就是预测图中尚未存在的边。关于Link Prediction和推荐系统学术界已经有很多研究工作,比如经典的协同过滤-Collaborative Filtering,Adamic/Adar等等。
Collaborative Filtering有user-based和item-based两种,user-based多用于挖掘那些有共同兴趣的小团体;而item-based侧重于挖掘item之间的关系,然后根据用户的历史行为来为用户生成推荐列表。相比item-based,user-based方法推荐的新颖性好一些,但是准确性差,item-based 的应用更为广泛。在之后又发展出SVD和一系列model-based方法,在实际的推荐系统中可以分为两层,match层和rank层。match用各种算法做召回,比如CF,Content B-based,Demographic-based等等,做粗排之后交由rank层的model做更精细的排序。本文主要侧重在基于图结构做match,我们提出了一种新的算法—SWING。
Triangle Rank
说到SWING,首先得从Triangle Rank(也是我们原创的算法)说起,起源是我有一段经历在社会网络中做好友推荐。也就是在上边提到的第一种user-user这种网络中做link prediction,产品形态比如“你可能认识的人”。好友推荐最重要的就是衡量node proximity,即节点的邻近程度,一个节点和你越“亲近”,那么你认识他的可能性越大。传统度量节点的邻近程度有下面这些方法:

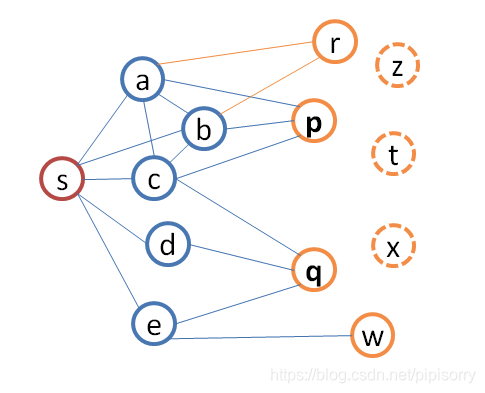
公式看起来有点抽象,我们来看一个具体的例子:在图1中,s是主节点,[a, b, c, d, e, f]是s的好友集合,[r, p, q, w]是s的2-hops邻居节点。假设我们要为s推荐好友,你会怎么做呢?很容易可以想到计算共同好友数(Common Neighbors),比如q和s有3个共同好友,r和s有2个共同好友,这样推荐的顺序是: q = p > r > w。我们用T(s)来表示节点s的度数,我如果告诉你,T(r)=10,T(q)=300,你觉得这样推荐合理么?这样看似乎先推荐r更合理,于是我们又可以想到Jaccard’s Coefficient或者Cosine Similarity,对本身度数比较大的节点做惩罚,这样就很大程度上解掉了这个问题。
在实际应用中更著名的是Adamic/Adar,常常被各种paper拿来当base line。我们来看一下Adamic/Adar的定义:
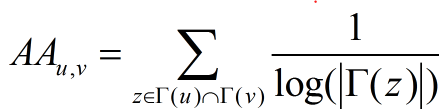
去掉分母的话不就是共同好友数么?是的,Adamic/Adar就是对中间节点(intermediate node)的节点做了一个加权,中间节点的度数越大,它的权重越小(其实就是neighbers出度加权的common neighbers)。但是实际应用中它的效果却非常好,Facebook在WSDM’11上发表了一篇文章,Supervised Random Walks: Predicting and Recommending Links in Social Networks,用random walk来做link prediction,费了半天劲在最后的评测上只比Adamic/Adar好了一点点,学术意义大于实际意义,当然Facebook线上用的肯定还有其他算法。
概括一下就是,Adamic/Adar很简单,但是却很有效。上边第3篇文章大牛Kleinberg在他们数据集上评测,效果最好的是Adamic/Adar和Katz,Katz算法复杂度太高了,实际很少会直接应用。
还有什么可提升的空间么?(a, b),(b, c), (a, c)之间都还有一条边,所有上边提到的算法,都是基于“点”计算节点相似性,并没有考虑中间节点的网络结构。在社会网络发展的研究领域中,有一个著名的理论,就是节点之间都在慢慢的相互之间连成三角形,其实s每加一个二跳节点为好友,都会新构成一个或多个三角形(close a triangle),比如s如果和w新建立了好友关系,[s, e, w]就构成了一个三角形,三角形在网络中是非常稳固的结构。
Item-based CF
Item-based CF的核心仍然在于计算item节点之间的proximity。
web-cos算法与热门打压
考虑到jacard相似度会倾向于推出热门商品,我们在相似度公式中引入一个打压热门的因素。
同时jacard相似度计算不考虑用户看两个商品的时间间隔,我们认为随着用户浏览两个商品的时间间隔的增加,两个商品的关联性应有所减弱。所以我们在相似度公式中同时引入了时间衰减因子。
item-based CF,可以支持用户自定义相似度,item之间相似度的计算方式WB-Cosine,定义为:
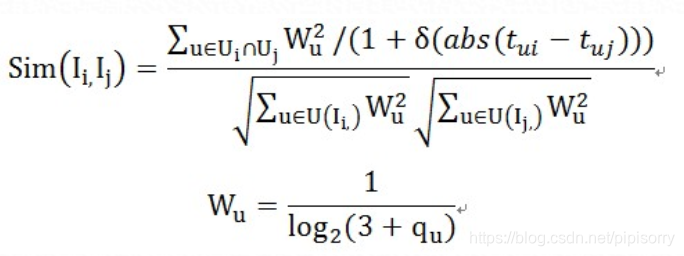
这个算法在经典余弦相识度算法基础上,对那些行为多的用户进行权重惩罚,同时还考虑了时间因素,实际应用效果比Jaccard’s Coefficients和原始的Cosine Similarity会有提升。
其中,U_i是浏览商品i的用户集合,q_u是用户浏览的商品数。
该算法核心是在经典余弦相识度算法基础上,对那些浏览行为过多的用户进行权重惩罚。如果取W_u=1就退化成jacard相似度公式。
我们对比了单份相似数据的效果,这份相似数据对比基于jacard相似数据,线上效果有5%的提升。但由于第二阶段的调优成果不能直接用到这份相似数据上。所以第三阶段的线上效果相比第二阶段提升并不明显。
SWING
Swing 是搜索事业部--推荐算法团队弦木同学原创的一种新的match算法,目前Swing i2i作为最重要的基础数据,广泛应用于手淘和PC众多的推荐场景中; 除此之外,swing还应用于集团天天动听和阿里妈妈广告业务中, 并有显著提升。
基于图结构的实时推荐算法 Swing,能够计算 item-item 之间的相似性。不同于传统基于“点”的节点亲密度(proximity)计算方式,如:Common Neighbors, Adamic/Adar, Cosine Similarity, Jaccard Similarity, Wb-cosine, Rooted PageRank等,Swing会考虑网络结构信息,以高维的网络结构向二跳节点扩展,抗噪能力强,相比传统的CF准确性有大幅的提升。
为了衡量物品 i 和 j 的相似性,考察都购买了物品 i 和 j 的用户 u 和 v, 如果这两个用户共同购买的物品越少,则物品 i 和 j 的相似性越高。极端情况下,两个用户都购买了某个物品,且两个用户所有购买的物品中,共同购买的物品只有这两个,说明这两个用户兴趣差异非常大,然而却同时购买了这两个物品,则说明这两个物品相似性非常大!Swing 指的是秋千,用户和物品的二部图中会存在很多这种秋千,例如 (u1,u2,i1), 即用户 1 和 2 都购买过物品 i,三者构成一个秋千 (三角形缺一条边)。这实际上是 3 阶交互关系。传统的启发式近邻方法只关注用户和物品之间的二阶交互关系。Swing 会关注这种 3 阶关系。这种方法的一个直觉来源于,如果多个 user 在点击了 i1 的同时,都只共同点了某一个其他的 i2,那么 i1 和 i2 一定是强关联的,这种未知的强关联关系相当于是通过用户来传递的。另一方面,如果两个 user pair 对之间构成的 swing 结构越多,则每个结构越弱,在这个 pair 对上每个节点分到的权重越低。
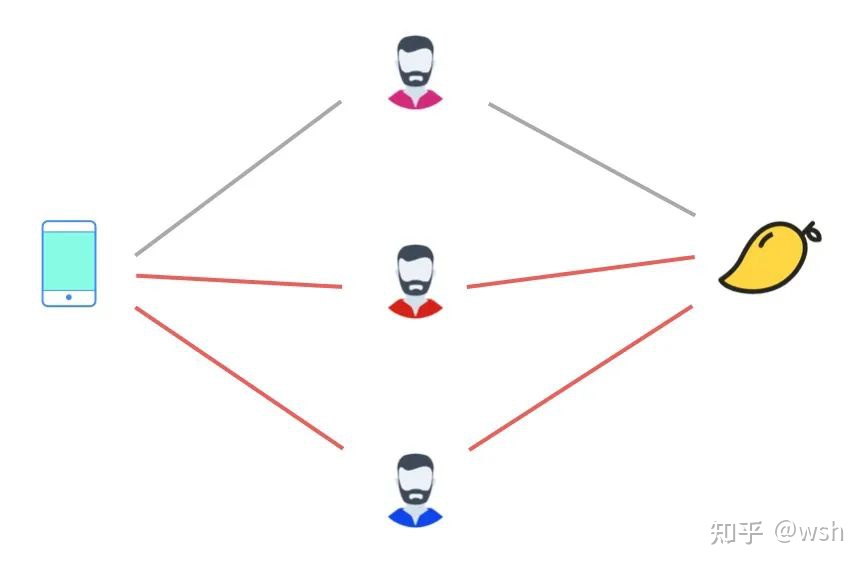
协同过滤算法swing考虑了上述的每条边的权重大小,寻找图中更加稳固的形状。共同点击过两个物品的用户集合set1,set2中,set1和set2中分别的任一用户和这两个物品形成了一个四边形(上图红边为一个四边形),统计有多少个这样的结构,每一个结构的权重是不同的,这个结构里两个用户共同评分过的物品的数量越多权重就越小,这是因为:两用户共现的帖子越多,其中帖子集合里面由于共同用户而两物品相似的可信度越低,因此权重越小。[swing算法 - 知乎]
公式如下:
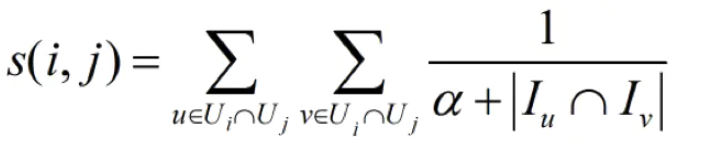
Ui表示点击过i的user集合, Iu表示u点击过的item集合。

思考:为何swing 算法的召回结果会更好
1:svd, CF 等算法在对对用户行为进行一层抽象
2:打分近似, 矩阵近似计算
3:svd, CF数据稀疏问题
4:swing 算法基于二步图,对用户和商品行为进行了直接建模,其原理和思想更加贴近实际用户特征[【召回】swing 算法 - 简书]
5:所有传统的node proximity度量方式(random walk等传播算法除外)都是以“点”的方式向二跳节点扩展去计算,而Triangle Rank和SWING都是以某种更“稳固”的网络结构向二跳节点扩展。和Collaborative Filtering比,swing要更严格,它更好的利用了人的collective intelligence,去噪能力强,每一个swing结构都是“有益”的信息,CF不是,CF中很多节点都可能是不相关的“噪声”,而且没有办法区分。
6:SWING另外一个优点是它对网络结构的变化相对更灵敏,如果出现一个新的很相关的item,如果有部分用户都发现了这个item并且都点了它,那么它就很可能排上去(这个优点在user-user网络里会更突出)。在实际用的时候,我们也发现SWING的这个特性会带来一些困扰,比如一些稍显“色情”的图片,很多用户都去点,那么它就有可能被排到前面,不过总体还好,也有解决方法,这里就不展开了。
缺点:但是i2i召回本身也存在一些问题,比如对新用户和新商品不友好,难以解决冷启动问题
改进
1 对“活跃”的user进行惩罚,增加IUF(inverse user frequency)因子,评测表明可以进一步提高precision。wi = Math.pow(item_set_i.size() + 5, -0.3);wj = Math.pow(item_set_j.size() + 5, -0.3);swingScore = wi * wj / (1 + intersectionSet.size());
2 热门商品打压:score / log2(1.0 + site_clk_goods_qty_1m)(可以在算完普通swing分最终结果表里面处理)
公式:
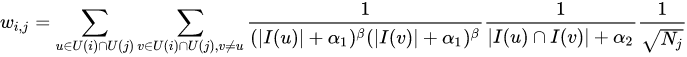
还可以尝试:
1 在训练算法时过滤掉下单次数太多(>=100)或者太少(<=1)的用户。
2 除了下单关联外,加上加购关联。
3 user_id+seller_id或者user_id+industry_id作为新的user_id。同时可以带上加购同店铺满减标签。
4 item_list只考虑同行业。
算法复杂度
假设网络中item的总数量是T,item的平均节点度数是N,user的平均节点度数是M,那么item-based CF的算法复杂度为O(T*N*M),SWING的算法复杂度是O(T*N^2*M) {(对所有商品groupby就是T,计算neighbors的交集是N**2,交集(最大为M)里面所有doc与当前t组合)}。
eTREC中高效实现了CF,并将整个流程简化为两轮map-reduce,原始的SWING只需要一轮map-reduce。如果添加IIF因子,需要在处理基础数据的时候额外加1~2轮map-reduce。
代码
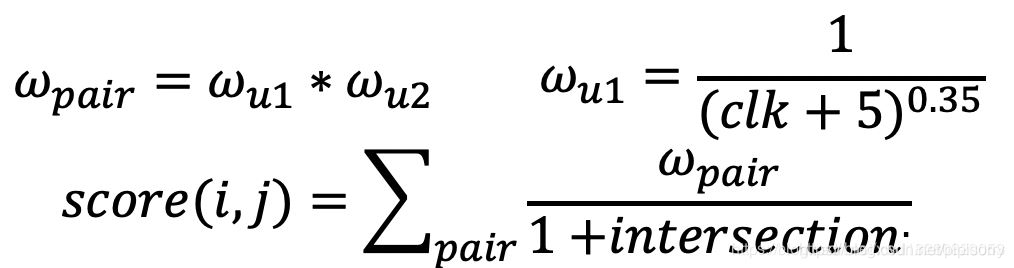
def SwingRecall(u2items):
u2Swing = defaultdict(lambda:dict())
for u in u2items:
wu = pow(len(u2items[u])+5,-0.35)
for v in u2items:
if v == u:
continue
wv = wu*pow(len(u2items[v])+5,-0.35)
inter_items = set(u2items[u]).intersection(set(u2items[v]))
for i in inter_items:
for j in inter_items:
if j==i:
continue
if j not in u2Swing[i]:
u2Swing[i][j] = 0
u2Swing[i][j] += wv/(1+len(inter_items))
# break
return u2Swing
提升swing i2i中尾部准确率
同是召回,场景不同,目标不同,差异还是很大的。首猜目标是点击,且用户兴趣相对较发散,召回更加注重全面性(能较大程度覆盖用户的所有兴趣)、发现性和多样性,i2i、u2i、u2u2i等适合首猜。而购物车和detail场景目标是转化,此时用户的意图已经相对收敛,尤其是detail场景,所以最重要的依然是i2i(和主商品相关)。由此尝试过多种i2i,包括基于graph的path walk、图像i2i、graph embedding的i2i、文本bert embedding的i2i,均没有拿到什么收益。
数据分析方法论
1、召回分两个方向:扩召回和去掉已有召回中不好的。比如swing i2i中天然存在热门不相关的bad case。
2、肉眼去看bad case,分析为什么会召回这些bad case,如何避免或者去掉。
3、数据分析要分段,分为头部、中部、尾部,各段的表现以及各段分别存在什么问题,做出改进后对各段分别的影响等。
受Q同学的启发,统计了swing i2i在detail场景曝光头部(30%)、中部(40%)、尾部(30%)的l2p(= pay_uv / exposure_uv),分别为:0.0707%、0.0368%、0.03%,由此看出处于中尾部的远差于头部。同时,头部、中部、尾部的商品,近40天的平均点击uv数分别为965.78、117.09、51.51,近180天的平均点击uv数分别为2969.16、467.26、216.45。将用于计算swing i2i的用户点击数据从40天拉长到180天,是能有效提升用于统计的样本数量的,同时还能引入更多的边。唯一的瓶颈在于数据量太大,跑不出来,我们就利用随机采样,减少头部、中部、尾部的数据样本之间的差距,使得样本分布更均衡一些。同时减少右i的数量,因为detail场景主转化,去掉无销量的商品,影响不大。
i2i大体可分为两个方向:基于graph / network直接得到商品间关系;通过商品的embedding表示计算商品间关系。而基于graph / network的相对更精准,因为都是基于显式的,已存在的关系。基于embedding的泛化性更好,能挖掘出隐式的关系。
其中基于graph / network方向,可考虑直接将node2vector或者GNN的第一阶段得到的结果,即用于计算item embedding的种子数据直接作为i2i结果投入使用,即基于path walk挖掘出更多的邻居商品。其中也可借鉴social network中的一些思想。
也想到一个奇怪的点,比如利用influence maximization方面的思想,找出最具影响力的users,将他们买过的东西推荐给其他用户等。或者衡量每个商品的影响力由此确定边的权重和可信度等。
from:

















 2691
2691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









