






把与用户兴趣各种相关的信息都压缩成为一个表达向量。
使用类似聚类的方式来对用户的兴趣多峰分布进行表征. 那么如何高效地在神经网络内嵌入聚类过程, 将无监督的聚类过程结合到有监督的分类模型, 就是我们需要解决的关键问题. 在这里, 我们选择了使用动态路由(Dynamic Routing) 算法解决了这个问题.
Capsule 让人眼前一亮的地方是它提出了一种新的 "vector in, vector out" 的传递方案, 并且向量的输出可以看成是输入的某种聚类结果. 在胶囊网络中, 只要把一个向量当作一个整体来看,它就是一个"胶囊". 可以这样理解: 神经元就是标量, 胶囊就是向量. 每一个胶囊表示一个属性, 而胶囊的向量则表示这个属性的“标架”. 也就是说,我们以前只是用一个标量表示有没有这个特征 (比如有没有羽毛), 现在我们用一个向量来表示, 不仅仅表示有没有, 还表示“有什么样的” (比如有什么颜色、什么纹理的羽毛). 向量化表达特征, 可以说在对单个特征的表达上更丰富了.
胶囊网络中是怎么实现这样一种 "vector in, vector out" 的机制的呢? 答案就是通过动态路由算法.
其中, S_ij∈R^(N_h×N_l)是需要学习的双线性映射矩阵, 它的作用可以理解成为每个上层胶囊生成不同的映射空间, 达到表征不同属性的目的.
由于上层胶囊向量的长度用于代表该胶囊的激活程度, 可使用非线性的激活函数 squash 将上层胶囊的输入向量进行压缩得到上层胶囊的输出 →c^h_j:
这里有个有趣的地方, 即路由系数 b_ij的计算需要使用到上层胶囊的输出 →c^h_j:, 而 →c^h_j: 的计算反过来又需要用到 b_ij,虽然无法直接得到解析解, 但是通过迭代法, 从一个初始的估计出发逐步得到一系列近似解, 我们可以逼近这个最优数值. 动态路由就是从一个初始给定的全0 b^0_ij 开始, 一步步地迭代得到 b^k_ij, 最终得到上层胶囊的输出 →c^h_j.
B2I Dynamic Routing
在 MIND 中, 我们使用了 Dynamic Routing 实现了Multi-Interest Extractor Layer, 达到对用户行为进行聚合, 抽取用户兴趣点的目的. 但在原始的算法上, 我们做了几处适配.
-
使用共享的双线性映射矩阵 SS. 对所有行为向量以及所有生成的兴趣向量使用共享的映射矩阵, 保证生成的兴趣向量处于相同的空间.
-
随机初始化 b^0_ij∼N(0,σ^2) 类似 K-Means 聚类的初始化方法, 保证生成不同的初始聚类中心.
-
根据用户行为的数目动态调整兴趣个数. 当用户行为丰富时, 生成较多的兴趣中心, 当用户行为较少时, 生成较少的兴趣中心.
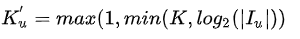


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









