




比赛网址:https://tianchi.aliyun.com/competition/entrance/531842/introduction
项目源码:Github
一、项目知识点
-
数据预处理;
-
数据可视化;
-
特征工程;
-
模型选择;
-
实验结果的评价;
二、实验过程
一、比赛任务分析
1.赛题背景
赛题以新闻APP中的新闻推荐为背景,要求选手根据用户历史浏览点击新闻文章的数据信息预测用户未来点击行为,即用户的最后一次点击的新闻文章
2.赛题数据
数据来自某新闻APP平台的用户交互数据,包括30万用户,近300万次点击,共36万多篇不同的新闻文章,同时每篇新闻文章有对应的embedding向量表示。将会从中抽取20万用户的点击日志数据作为训练集,5万用户的点击日志数据作为测试集A,5万用户的点击日志数据作为测试集B。
| train_click_log.csv | 训练集用户点击日志 |
|---|---|
| testA_click_log.csv | 测试集用户点击日志 |
| articles.csv | 新闻文章信息数据表 |
| articles_emb.csv | 新闻文章embedding向量表示 |
| sample_submit.csv | 提交样例文件 |
数据表
| Field | Description |
|---|---|
| user_id | 用户id |
| click_article_id | 点击文章id |
| click_timestamp | 点击时间戳 |
| click_environment | 点击环境 |
| click_deviceGroup | 点击设备组 |
| click_os | 点击操作系统 |
| click_country | 点击城市 |
| click_region | 点击地区 |
| click_referrer_type | 点击来源类型 |
| article_id | 文章id,与click_article_id相对应 |
| category_id | 文章类型id |
| created_at_ts | 文章创建时间戳 |
| words_count | 文章字数 |
| emb_1,emb_2,…,emb_249 | 文章embedding向量表示 |
字段表
| Field | Description |
|---|---|
| user_id | 用户id |
| click_article_id | 点击文章id |
| click_timestamp | 点击时间戳 |
| click_environment | 点击环境 |
| click_deviceGroup | 点击设备组 |
| click_os | 点击操作系统 |
| click_country | 点击城市 |
| click_region | 点击地区 |
| click_referrer_type | 点击来源类型 |
| article_id | 文章id,与click_article_id相对应 |
| category_id | 文章类型id |
| created_at_ts | 文章创建时间戳 |
| words_count | 文章字数 |
| emb_1,emb_2,…,emb_249 | 文章embedding向量表示 |
3.评价指标
利用推荐系统常用的两个指标MRR与HR进行评估。
HR(Hit Rate): 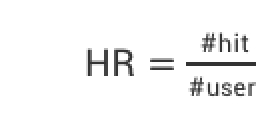
命中率:预测个数占用户总数的比例 (HR_i表明前i篇文章的HR得分)
MRR(Mean Reciprocal Rank):
首先对选手提交的表格中的每个用户计算用户得分

其中, 如果选手对该user的预测结果predict k命中该user的最后一条购买数据则s(user,k)=1; 否则s(user,k)=0。而选手得分为所有这些score(user)的平均值。(MRR_i表明前i篇文章的MRR得分)
4.赛题难点
(1)数据量大:一共有包括30万用户,近300万次点击,共36万多篇不同的新闻文章
(2)推荐系统随机性大:由于是基于真实数据,每个用户的点击随机性较高
5.赛题分类
最终需要给用户从高到低推荐5篇文章进行预测,因此为排序问题,可以通过一定方式转换为二分类问题(后续会提及方法)。
二、数据统计与可视化分析
1.数据集可视化展示
(1)Click_log(用户点击记录)
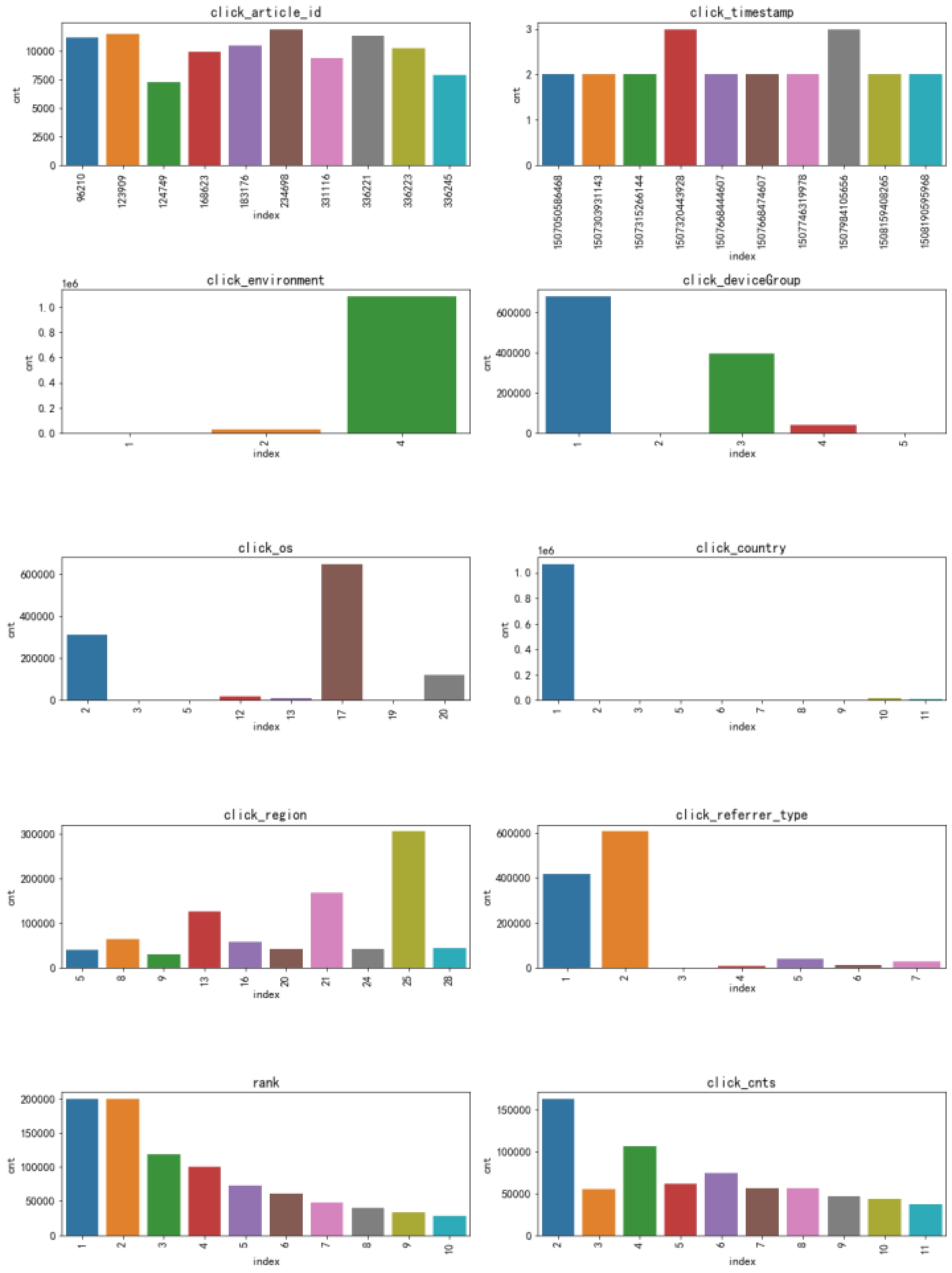
(2)Articles.csv(文章信息)
统计单词数量
统计文章主题
共461个主题,分布如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2543
2543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











