



 博客涉及元字符、re模块函数、分组和贪婪等内容,因之前已有笔记未详细书写。重点是作业部分,包括找到电影名称对应HTML文本、用Request库获取网页文本、用正则表达式提取电影名称,还使用for循环爬取前三页电影名称。
博客涉及元字符、re模块函数、分组和贪婪等内容,因之前已有笔记未详细书写。重点是作业部分,包括找到电影名称对应HTML文本、用Request库获取网页文本、用正则表达式提取电影名称,还使用for循环爬取前三页电影名称。
元字符
re模块 函数
分组和贪婪
由于这些部分我之前写过笔记,在这里就不写了。
作业
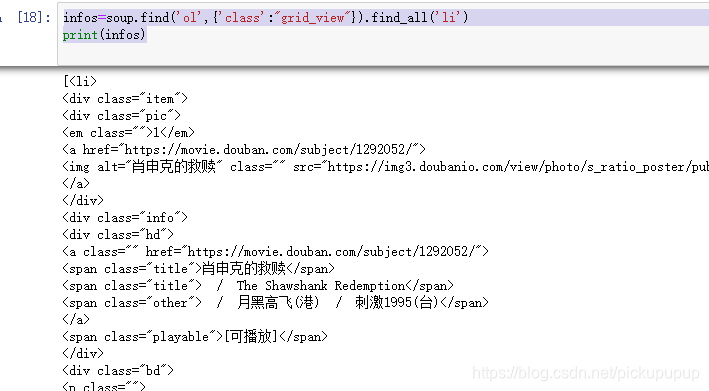
找到各个电影名称对应的HTML文本

使用Request库获取网页文本
infos=soup.find('ol',{'class':"grid_view"}).find_all('li')
print(infos)
infos=soup.find('ol',{'class':"grid_view"}).find_all('li')
print(infos)
使用正则表达式,提取文本中的电影名称
for info in infos:
title=info.find('div',{'class':"hd"}).find('span',{'class':'title'}).get_text()
print(title)

使用for循环,爬取前三页的电影名称
import requests
import re
from bs4 import BeautifulSoup
for i in range(10):
url= 'https://movie.douban.com/top250?start=%d&filter='% (i*25)
# print(url)
resp =requests.get(url)
html =resp.text
soup=BeautifulSoup(html,'html.parser')
# print(soup)
infos=soup.find('ol',{'class':"grid_view"}).find_all('li')
# print(infos)
for info in infos:
title=info.find('div',{'class':"hd"}).find('span',{'class':'title'}).get_text()
print(title)
直接爬取了全部


















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









