



 博客介绍了爬虫基本原理,包括发送请求、获取响应内容、解析内容和保存数据;讲解了HTTP协议及HTML知识,如常用标签等;还介绍了Requests库,包括发起请求和处理响应内容,并布置了用该库获取豆瓣电影TOP250网页文本等作业。
博客介绍了爬虫基本原理,包括发送请求、获取响应内容、解析内容和保存数据;讲解了HTTP协议及HTML知识,如常用标签等;还介绍了Requests库,包括发起请求和处理响应内容,并布置了用该库获取豆瓣电影TOP250网页文本等作业。
一、爬虫基本原理
1 发送请求
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的的headers等信息,等待服务器响应。
浏览器发送消息给该网址所在的服务器
1.1请求方式
1.2请求URL(链接)
URL:http协议 域名 路径
客户端——>服务器
1.3请求头
1.4请求体
2 获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面
2.1响应状态
200 成功状态码
300 重定向状态码
400 客户端错误状态码
500 服务器错误状态码
2.2响应头
2.3响应体
3 解析内容
3.1解析方式:
直接处理、Json解析、正则表达式、Beautifulsoup、PyQuery、XPath
怎样解决JavaScirp渲染的问题
4 保存数据
文本、关系型数据库、非关系型数据库、二进制文件
二、HTTP协议及HTML知识
1 超文本传输协议(HTTP协议)
2 HTML
标签语言 通过一系列标签构成
常用标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
</body>
</html>
2.1<!DOCTYPE html>
告诉浏览器以哪种规范解析文档,浏览器按照标准来渲染页面
2.2<html></html>
2.3 <head></head>
<meta>共有两个属性,分别是http-equiv属性和name属性
name属性主要用于描述网页,与之对应的属性值为content,content中的内容主要是便于搜索引擎机器人查找信息和分类信息用的。
http-equiv相当于http的文件头作用,它可以向浏览器传回一些有用的信息,以帮助正确精准地显示网页内容,一致相对应的属性值为content,其中的内容其实就是各个参数的变量值。
<title> 标签
2.4 <body>
<hn>标题标签
<p> 段落标签,中间有一行空白
<b>加粗标签
<br>换行
<div>块级标签
<span>内联标签
特殊符号
2.5 图形标签<img>
<img src="1.jpg" width="200px" height="200px" alt="京东" title="京东">
2.6 <a>
超链接:<a href="http://www.jd.com">京东</a>
锚标签:
列表标签
<ul>无序列表
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<ol>有序列表<dl>定义列表
2.7表格标签
2.8表单标签
用于向服务器传输数据
<form action="task1.html" "method="get">
<p>姓名:<input type="text"></p>
<p>密码:<input type="password"></p>
<p><input type="submit" value="press"></p>
<p><input type="button" value="press"></p>
<p>爱好:篮球<input type="checkbox"></p>
<p>男<input type="radio" name="sex"></p>
<p>女<input type="radio" name="sex"></p>
</form>
三、Requests库
1 发起请求
1.1 requests.get()
import requests
url=""
reps=requests.get(url)
1.2 如何构建查询参数
1.3 其他请求方式
还有post等,可以在network headers部分查看具体请求方式
2 响应内容
2.1 编码
encoding=“utf-8”
2.2 将响应的内容保存到文件
with open()
with open(r'C:\Users\赖菲\Desktop\无聊的课程论文\随便学学爬虫\向日葵小组 网络爬虫入门\task\data.txt','a',encoding='utf-8') as f:
f.write("{}".format(urls))
作业
1 用Requests库获取豆瓣电影TOP250第一页的网页文本
2 打印出豆瓣电影TOP250所有链接
3 将其写入txt文本中
1
import requests
url="https://movie.douban.com/top250?start=0&filter="
resp= requests.get(url)
print(resp.text)
运行结果
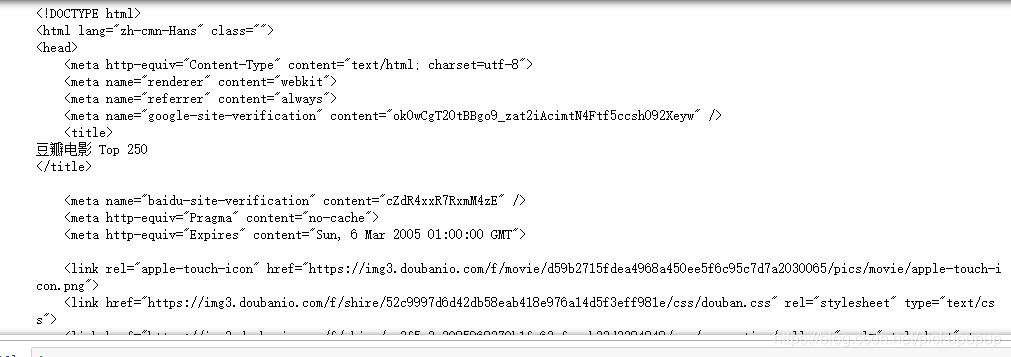
2
import requests
def allurl():
html = []
for i in range(10):
url='https://movie.douban.com/top250?start=%d&filter='%(i*25)
html.append(url)
return html
allurl()
运行结果:
['https://movie.douban.com/top250?start=0&filter=',
'https://movie.douban.com/top250?start=25&filter=',
'https://movie.douban.com/top250?start=50&filter=',
'https://movie.douban.com/top250?start=75&filter=',
'https://movie.douban.com/top250?start=100&filter=',
'https://movie.douban.com/top250?start=125&filter=',
'https://movie.douban.com/top250?start=150&filter=',
'https://movie.douban.com/top250?start=175&filter=',
'https://movie.douban.com/top250?start=200&filter=',
'https://movie.douban.com/top250?start=225&filter=']
3
def allurl():
html = []
for i in range(10):
url='https://movie.douban.com/top250?start=%d&filter='%(i*25)
html.append(url)
return html
urls=allurl()
print(urls)
with open(r'C:\Users\赖菲\Desktop\无聊的课程论文\随便学学爬虫\向日葵小组 网络爬虫入门\task\data.txt','a',encoding='utf-8') as f:
f.write("{}".format(urls))

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









