









NER(Named Entity Recognition)即命名实体识别,是指识别文本中具有特定意义的实体,如人物、地点、组织、时间和数字等,属于信息抽取的一部分。
目前,NER主要在多轮对话项目中应用,用于自动获取词槽所需的实体信息。如:“我想订一张下周一从北京回上海的机票”。在这个例子中按顺序抽取,
依次可得<[数字:一],[时间:下周一],[地点:北京],[地点:上海],[订单:机票]>,这些信息并非直接可用,还需进行一定的转换,变为规范数据才能使用。
数字通常要转为阿拉伯数字[0-9],时间一般转为标准年-月-日 时-分-秒,地点需要明确出发地和到达地,订单要具体到某一类。
对文本进行命名实体识别,一般从文本开始到结束顺序识别,相当于对一个序列进行识别,判断当前识别部分是否为某类实体。传统算法中CRF取得了较好的识别效果,
得到广泛应用,目前也被引入到深度学习中,作为深度学习模型的最后一层使用。为了节省人力、时间等资源,同时保障项目顺利推进,本项目的NER工作采用了成熟的深度学习方法,
具体的模型结构为Bi-LSTM+CRF。
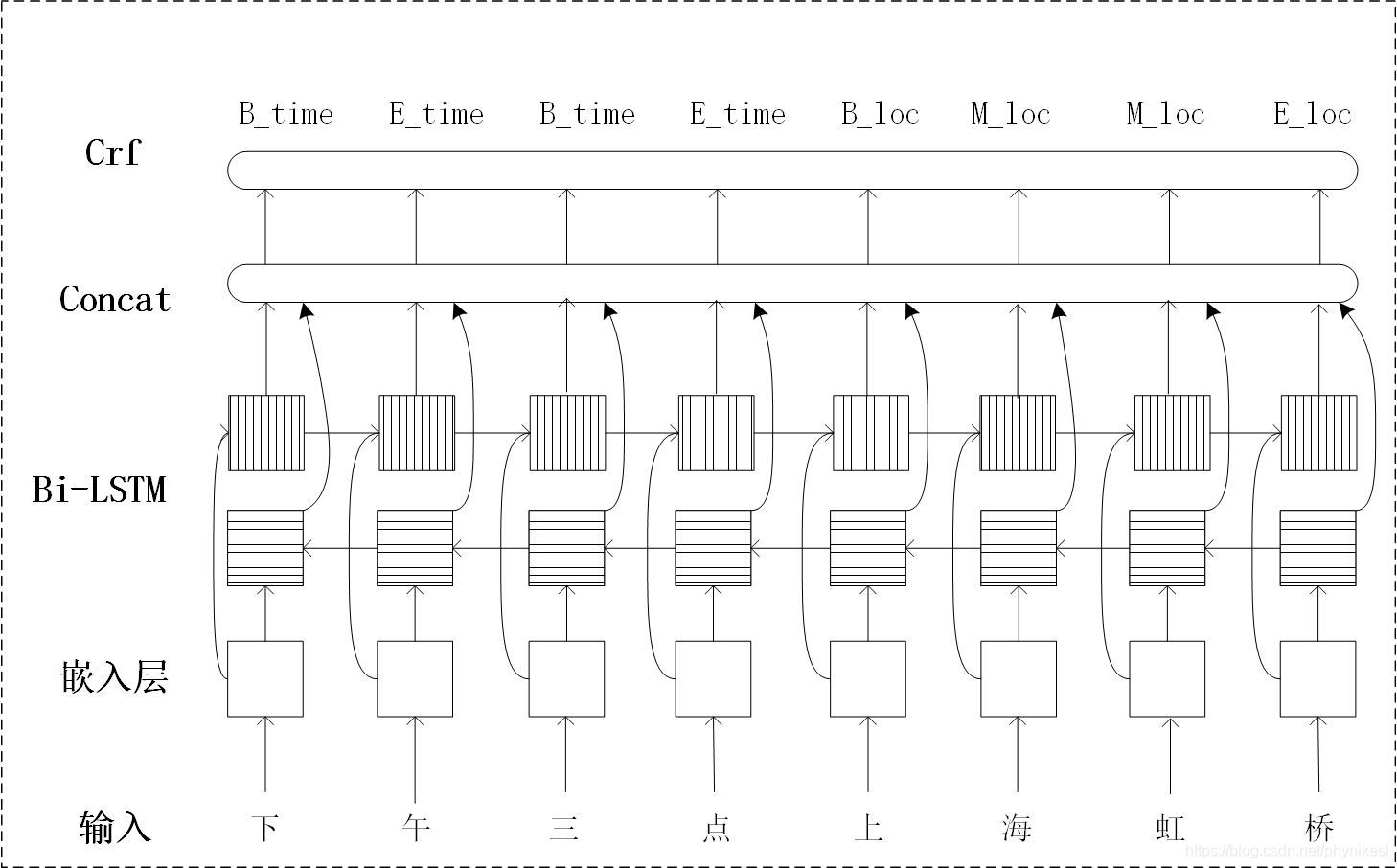
NER模型网络结构
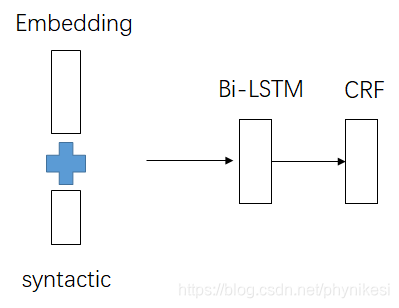
结合词性标注的嵌入层优化
模型自下而上依次是:嵌入层(用于文字的向量化表征),Bi-LSTM层(用于特征提取),CRF层(用于字标注)。
嵌入层不止包含每个字的字向量还有词性标注对应的标注向量,将二者做concat拼接作为最终输入。由于词汇数量级为万,词性标注数量级为十,差距较大,
并未将词性标注的维度设置为词向量维度一致,而是设为其5%-10%。比如词向量100维,词性标注10维。
为最大化利用数据,降低干扰,将各大类实体独立训练,得出Time(时间)、Loc(地点)、Per(人物)、Org(组织)和Num(数字)五类模型,再一起用于预测。
性标注处理,借助哈工大pyltp进行词性标注,词性标注符号可预先确定,由语料也可确定字典大小,以便训练字向量和词性标注向量时确认规模。因为词性标注按照分词结果,
以词为单位进行标注,因此没法单独标注每个字的词性。此外,即便有办法标注字的词性,由于字在不同的词中作用不同,其词性标注未必单一,也难以确定用哪一个词性作为代表更合适。
相比之下,以词为单位所得词性标注较为统一,可以用词的词性标注作为组成该词的每个字的词性标注。比如“李冬冬”词性标注为“np”,可得<[‘李’:‘np’],[‘冬’:‘np’],[‘冬’:‘np’]>。
CRF标注采用‘B’、‘M’、‘E’、‘O’为基础标记,根据需要也可以加上单字标记‘S’。其中‘B’代表一个实体的开始,‘M’代表一个实体除了首字和尾字以外的部分,‘E’代表实体尾字,
‘O’代表非实体标记(也可视为无效文本的标记)。如“火车快要到达北京站了。”,对应的标记为<[火:B],[车:E],[快:O],[要:O],[到:O],[达:O],[北:B],[京:M],[站:E],[了:O],[。:O]>。
实际使用时,会在相应标记后接一个实体类别,如:“中国”对应国家,<[中:B_country],[国:E_country]>;“北京”对应城市,<[北:B_city],[京:E_city]>;“中关村”对应村子,<[中:B_village],[关:M_village],[村:E_village]>。
对未登录词的处理与数据填充,在字典中保留特殊标记‘Unknown’,未登录词均用此标记替代。由于使用了LSTM网络,预设了time_steps,不足此长度的句子会被填充,
没有单独设置‘Pad’符号,也用‘Unknown’填充。此次词性标注模型训练使用的是有监督方式,对于目标target的填充,统一用‘O’填充,‘O’本身就用来标记非实体文本,
代表的就是‘无效数据’,填充部分也属于无效数据,特性一致。
词性标注符号及编号
{'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4, 'g': 5, 'h': 6, 'i': 7, 'j': 8, 'k': 9, 'm': 10, 'n': 11, 'nd': 12, 'nh': 13, 'ni': 14, 'nl': 15, 'ns': 16, 'nt': 17, 'nz': 18, 'o': 19, 'p': 20,
'q': 21, 'r': 22, 'u': 23, 'v': 24, 'wp': 25, 'ws': 26, 'x': 27, 'z': 28}。共计选用了29类词性标注符号。
数据构成统计
| 实体大类 | Time | Loc | Per | Org | Num |
| 训练集 | 10573 | 15584 | 17427 | 11725 | 12946 |
| 标签种类 | 11 | 31 | 19 | 22 | 55 |
| 实体小类 | 5 | 11 | 7 | 8 | 19 |
优化前后模型性能对比
| P | R | F1 | 优化前F1 | |
| Loc | 0.93 | 0.85 | 0.89 | 0.87 |
| Num | 0.99 | 0.89 | 0.94 | 0.92 |
| Org | 0.9 | 0.86 | 0.88 | 0.83 |
| Per | 0.95 | 0.93 | 0.94 | 0.91 |
| Time | 0.98 | 0.96 | 0.97 | 0.96 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









