




93 确定执行的优先级
问题:
- 如何制定一个复杂的机器学习系统
- 设计复杂机器学习系统时所涉及到的问题
案例1 Building a spam classifier
- 邮件的特征向量
手动挑出单词
根据词频挑出单词

- 问题一:如何在有限的时间让分类器高精度低错误率
收集更多的素材
邮件的标题处理作特征
邮件的正文处理作特征(例如感叹号,med1cine)

94 误差分析
问题:
- 误差分析的概念
算法设计步骤
- 简单快速构建模型
- 画出学习曲线 图分析是否高方差高偏差,以决定是否使用更多的参数或数据(避免过早优化)
- 误差分析。查看被错误分类的都有什么特征和规律,系统的优缺点

误差分析步骤:
- 找到错误,手动分类,是否有更好的特征来帮助分类

数值计算的方法是算法检验的保证 (单一规则的数值评价指标) - 词干提取是否使用:快速尝试使用看是否有效果(可以看交叉验证错误率 )
- 单词大小写一致 是否使用
注意:在交叉验证集上做这些测试而不是测试集上
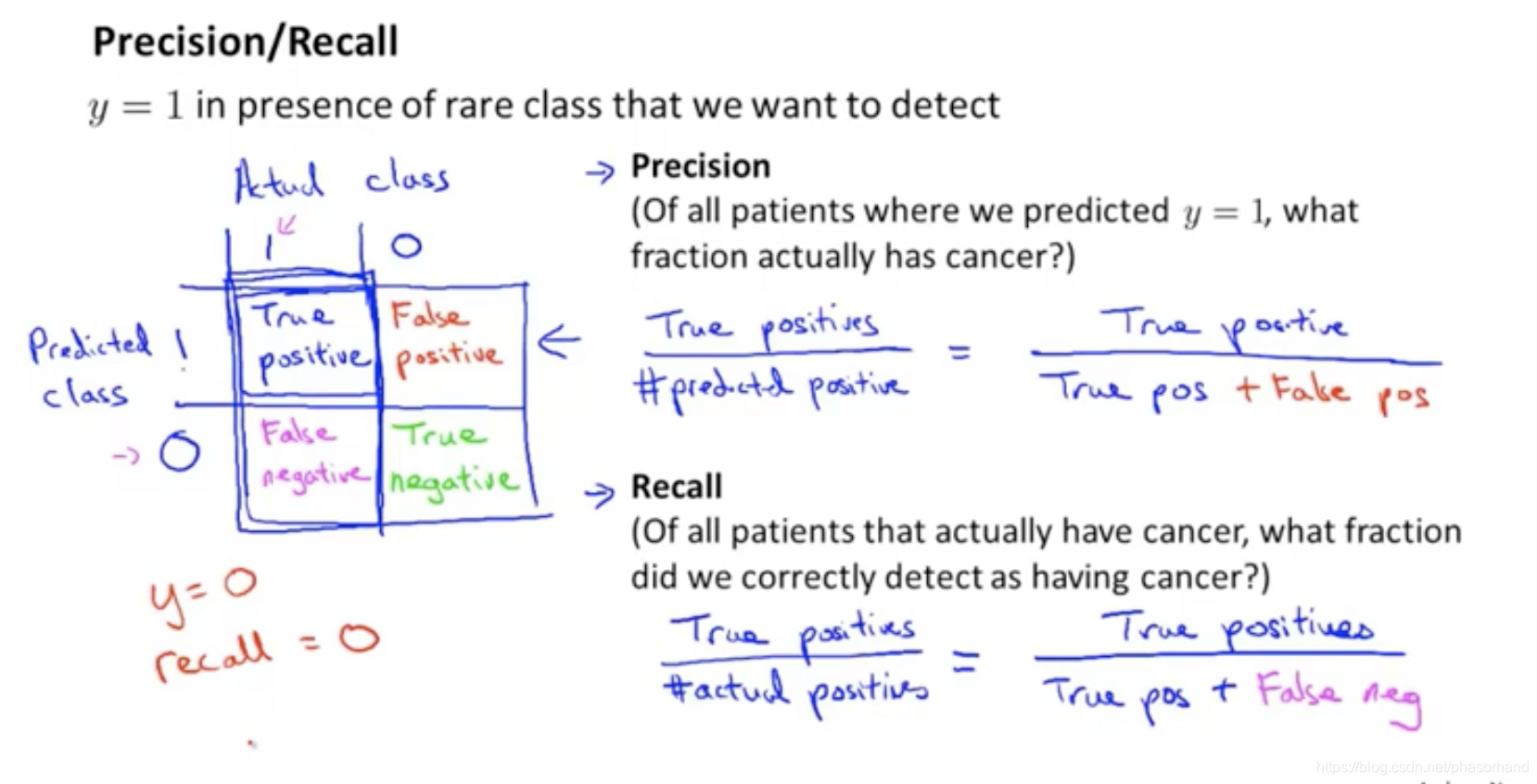
95 不对称性分类的误差(偏差类)
癌症案例:及时错误率低也不允许,需要选择一个不同的评估度量值
- 查准率/召回率 Precision/Recall:他们表现的好基本断定模型很好
96 精确度和召回率的权衡
- 遇到偏斜类问题的评估度量值
- 保证查准率和召回率的相对平衡
临界值的选择
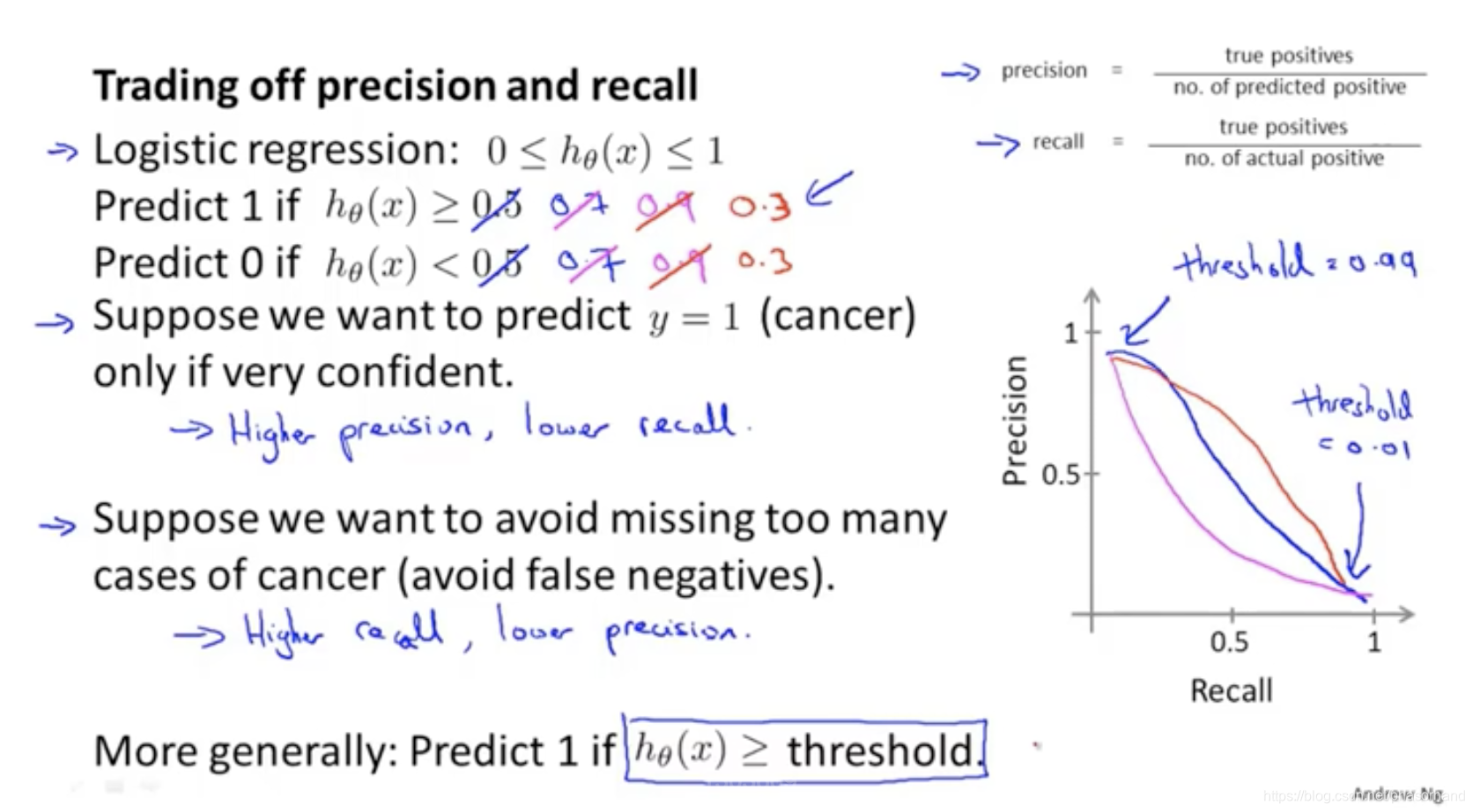
- 可否自动选取临界值

98 机器学习数据
很多开始看起来查的算法后面可能会逆袭
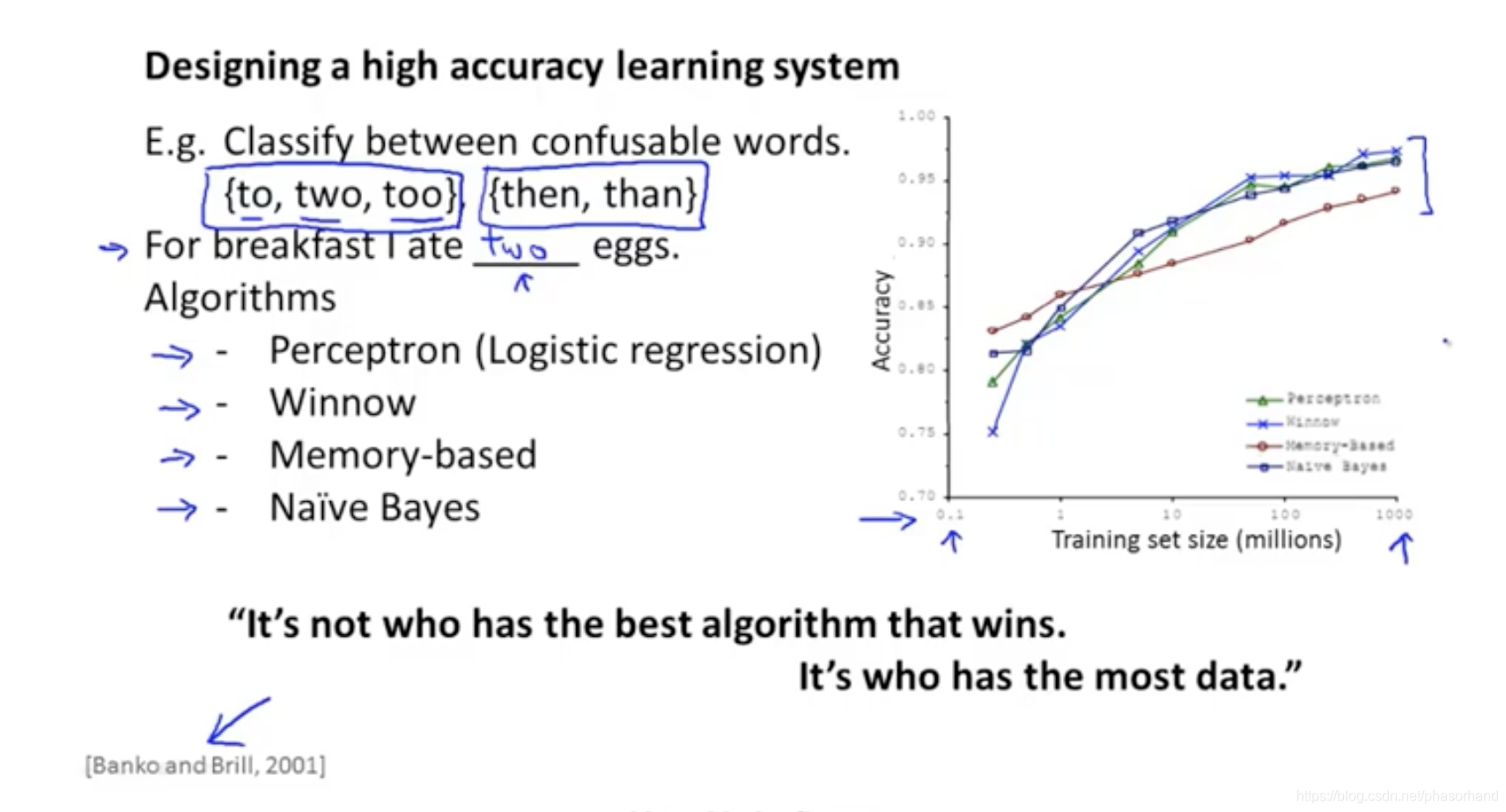
只告诉一个人房屋面积,他不是一个专家可能会说出这个房屋的价格,他是一个专家会向你要更多数据
数据比特征多很多不容易过拟合

key test:
- 一个人类专家看到了特征x能准确的预测y吗?
- 是否有足够大的集合

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









