




 本文探讨了机器学习中模型选择、训练与验证的过程,包括如何通过交叉验证集避免过拟合,诊断偏差与方差问题,以及如何利用学习曲线指导后续工作。介绍了正则化对偏差与方差的影响,并提供了基于复杂神经网络与正则化调整的解决方案。
本文探讨了机器学习中模型选择、训练与验证的过程,包括如何通过交叉验证集避免过拟合,诊断偏差与方差问题,以及如何利用学习曲线指导后续工作。介绍了正则化对偏差与方差的影响,并提供了基于复杂神经网络与正则化调整的解决方案。
83 决定下一步做什么
做之前了解这样做是否有效(筛除无效的选项)

Machine learning diagnostic

84评估假设(训练集 测试集)
取数据前最好打乱一下
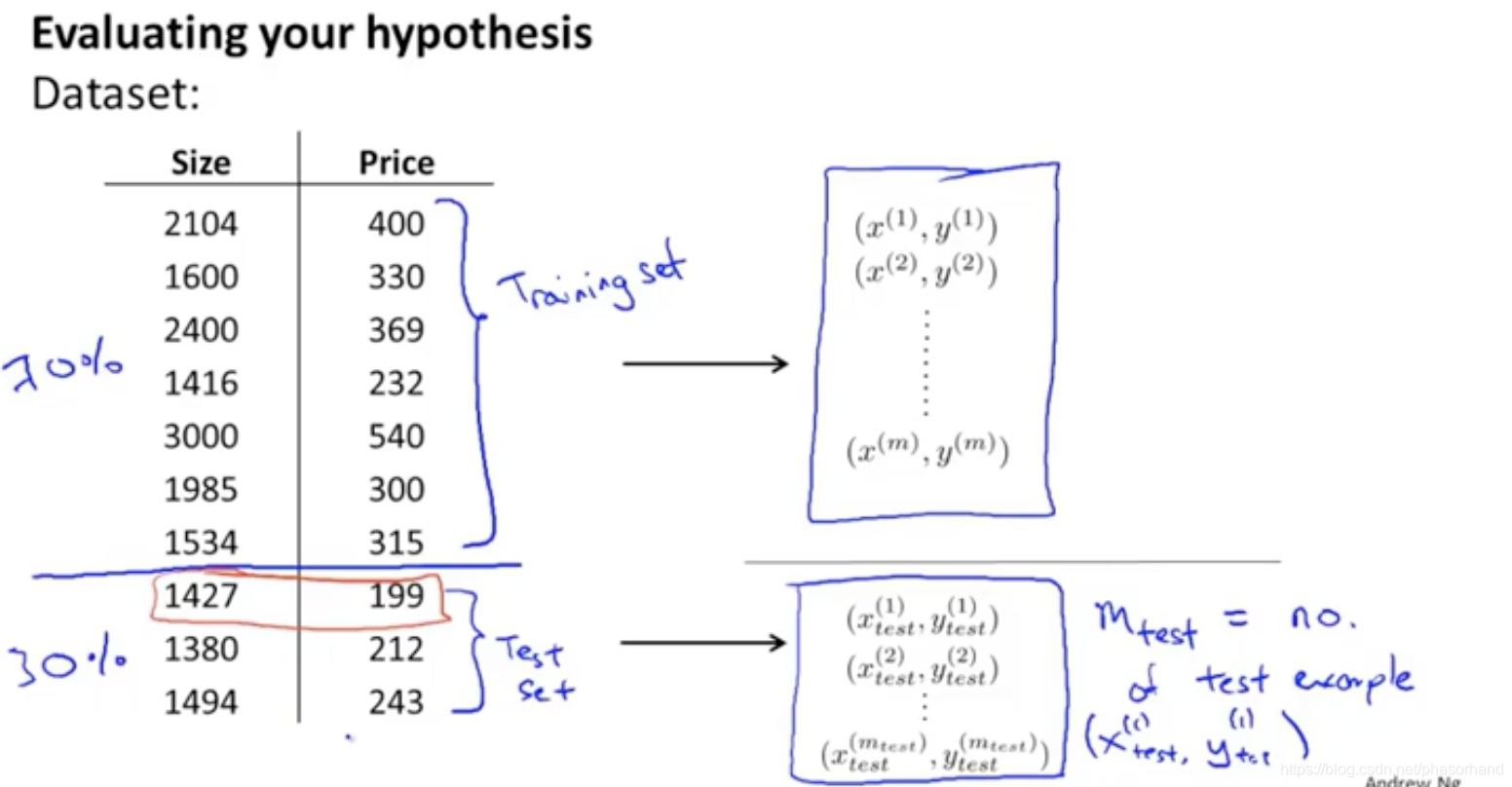

85 模型选择和训练、验证
模型选择问题:
- 数据集最合适的多项式次数
- 如何选用正确的特征
- 选择算法中的正则化参数lambda
只有测试集无法考察泛化能力
根据测试集的表现选择了模型(相当于测试集参与训练了),再用测试集去试验泛化能力就会不准确(偏高)!

cross validation set(cv)验证集
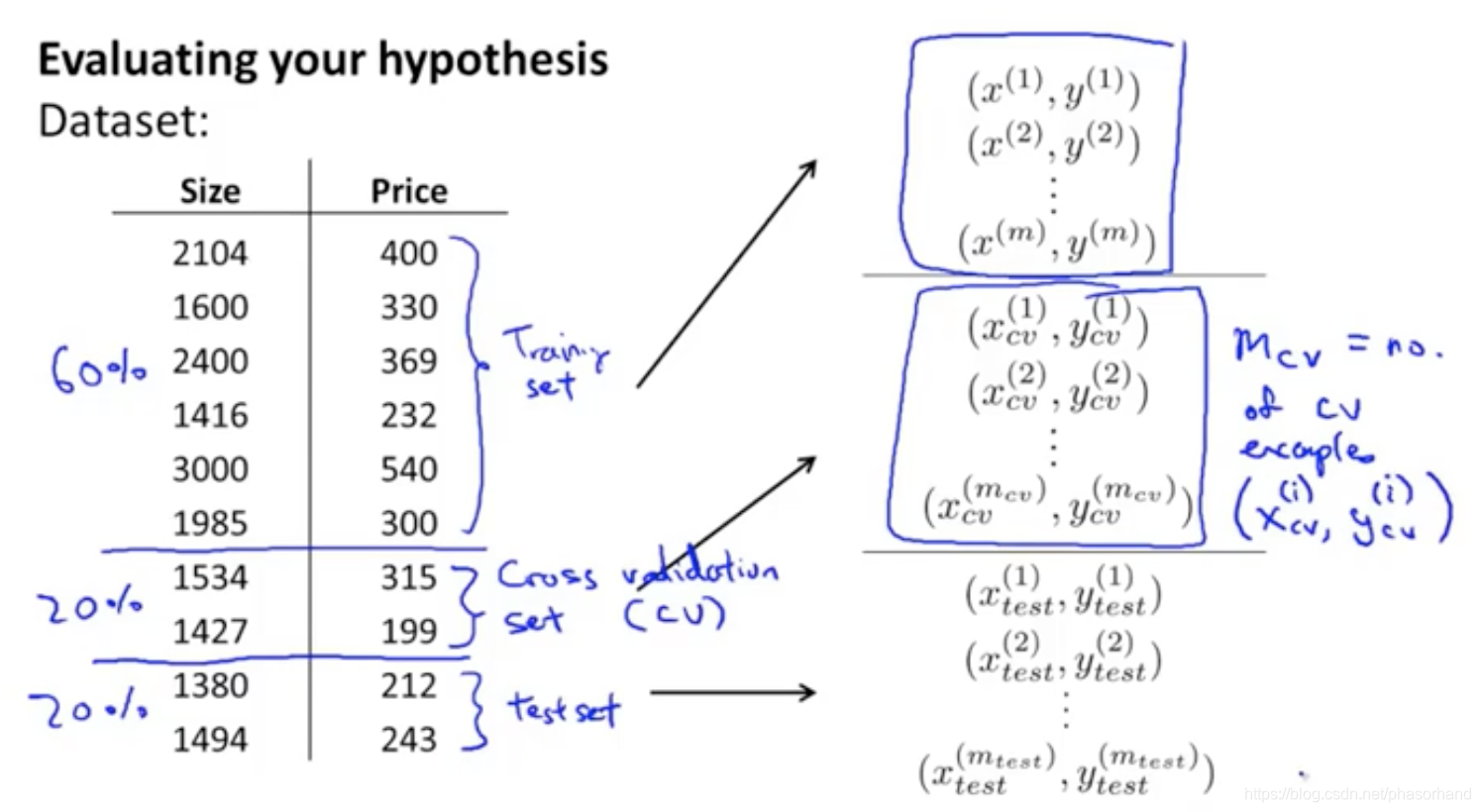
三种

测试集验证泛化能力
86诊断偏差和方差
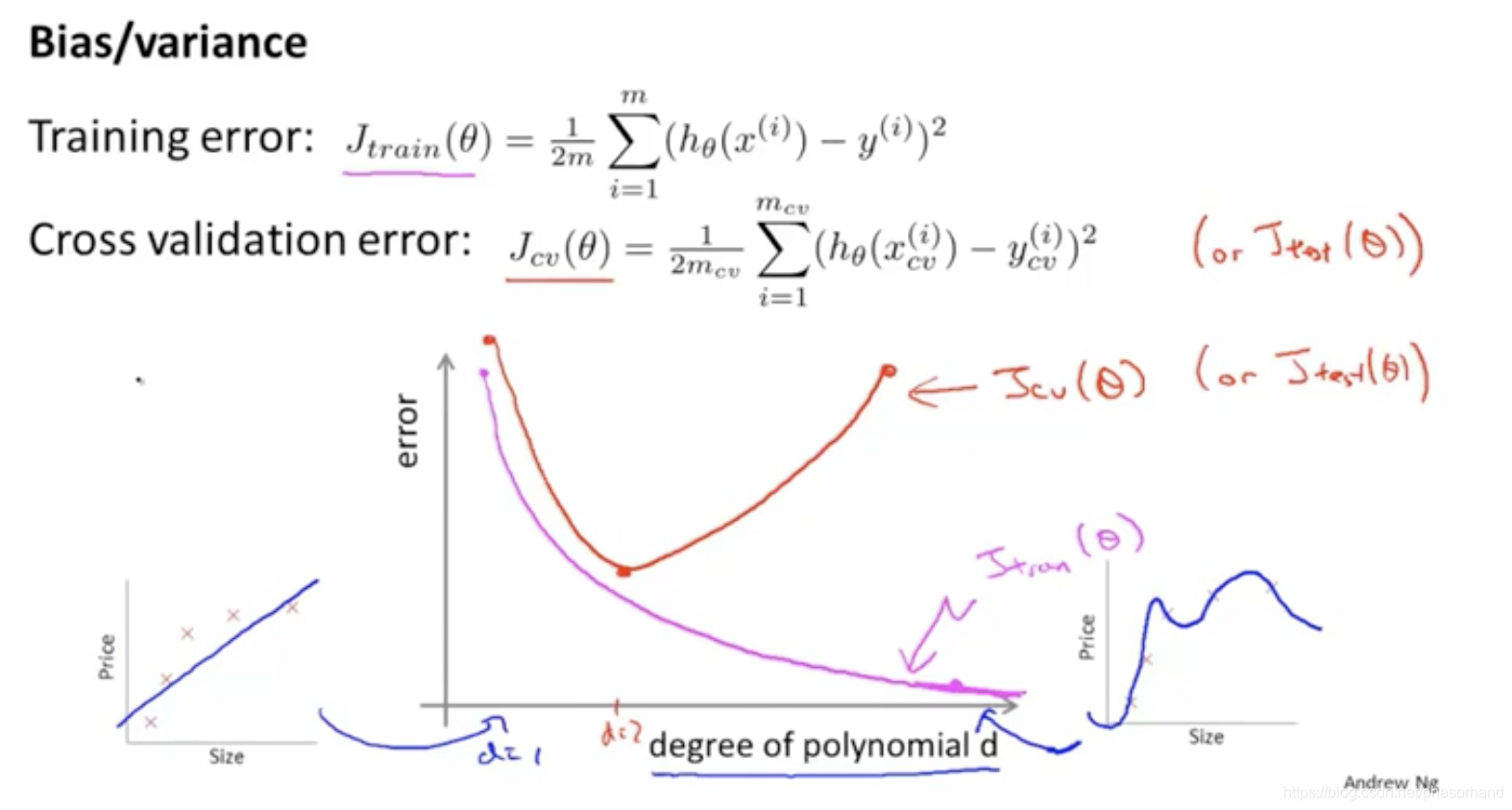

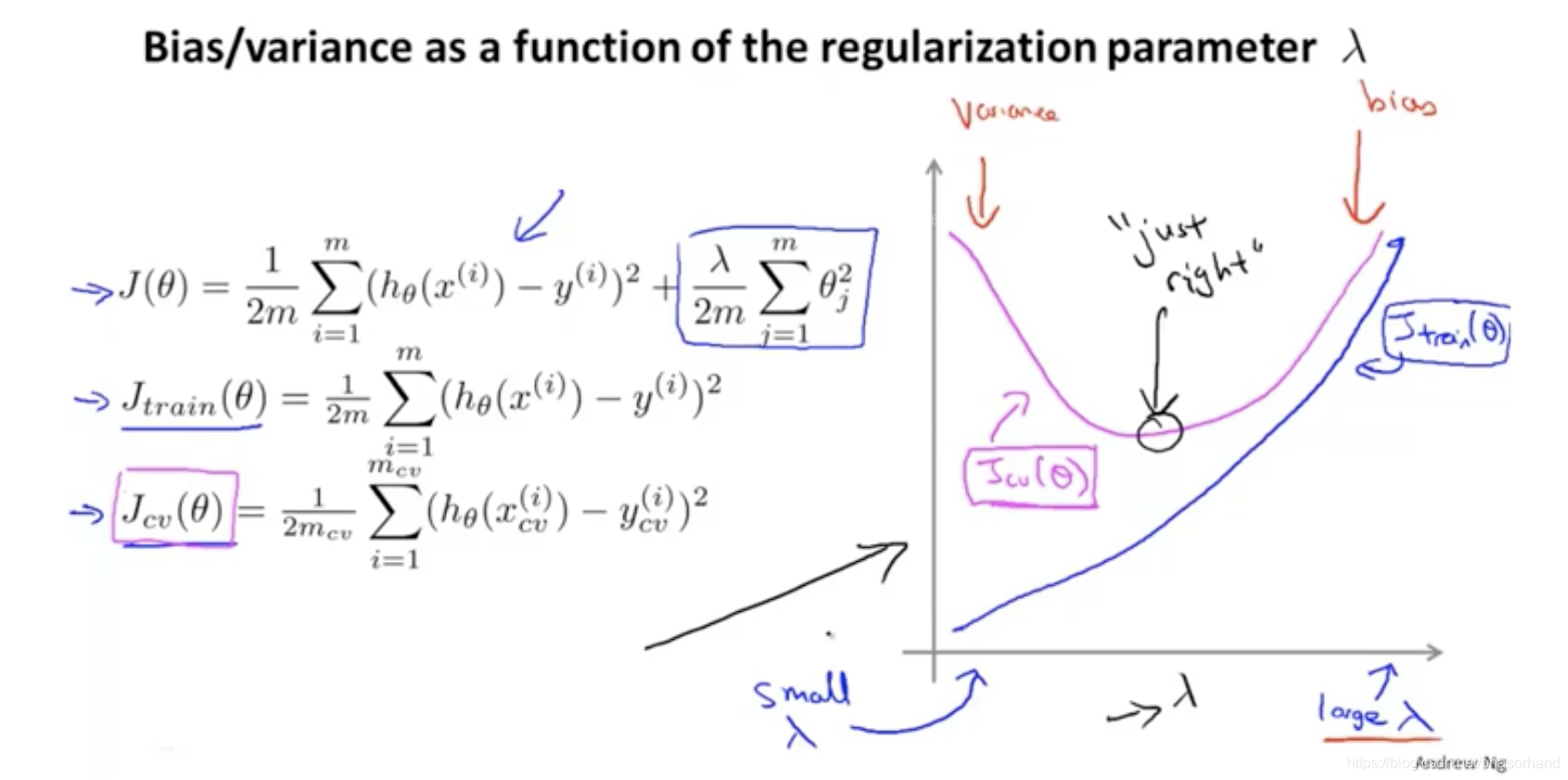
87 正则化和偏差、方差
问题:
- 正则化是如何影响方差的
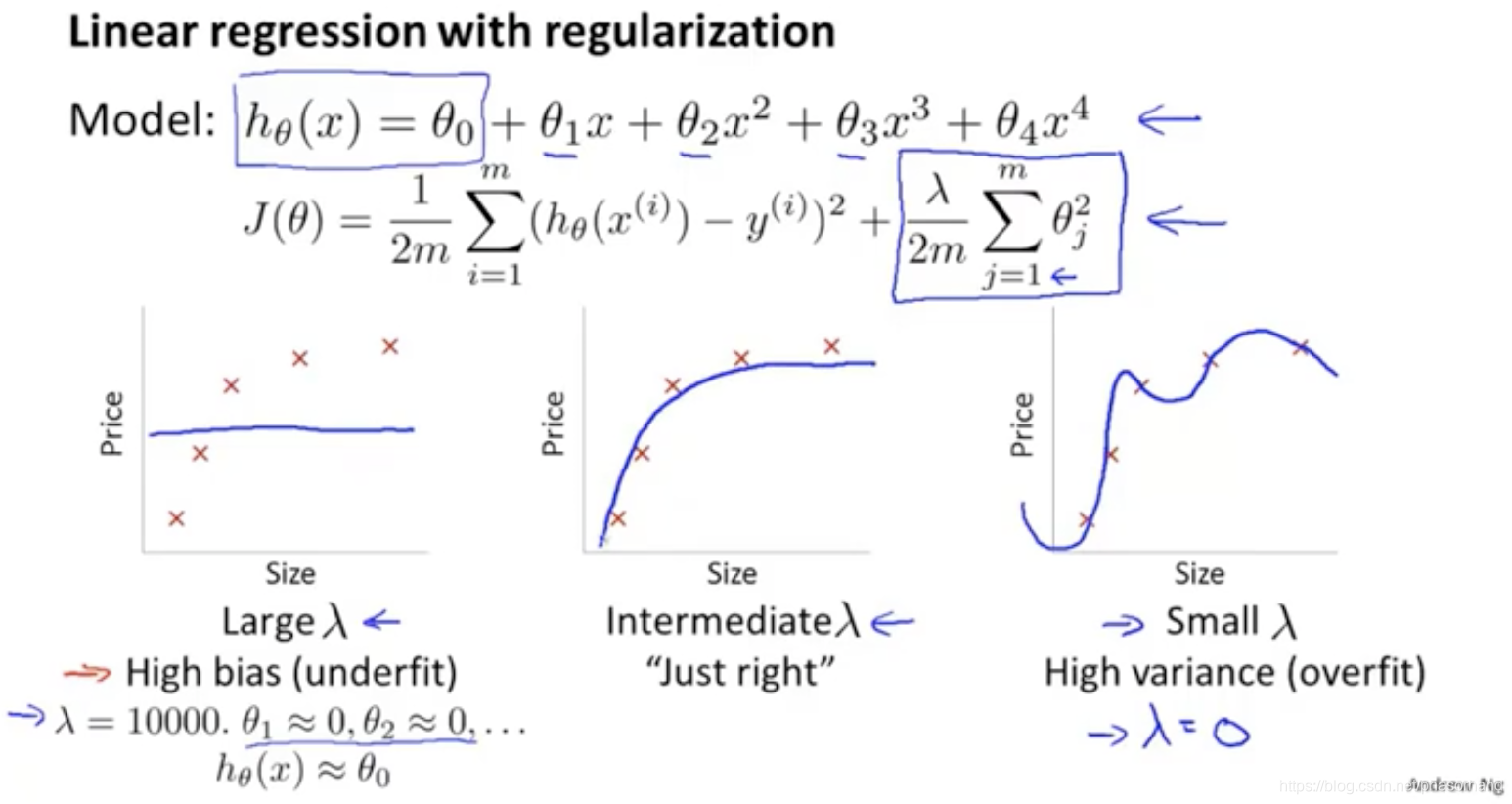
三个误差计算不考虑正则化


lambda小的时候过拟合所以Jcv就很大(Jcv;左边是方差 过拟合,右边是偏差 欠拟合)
交叉误差最小的点选出lambda
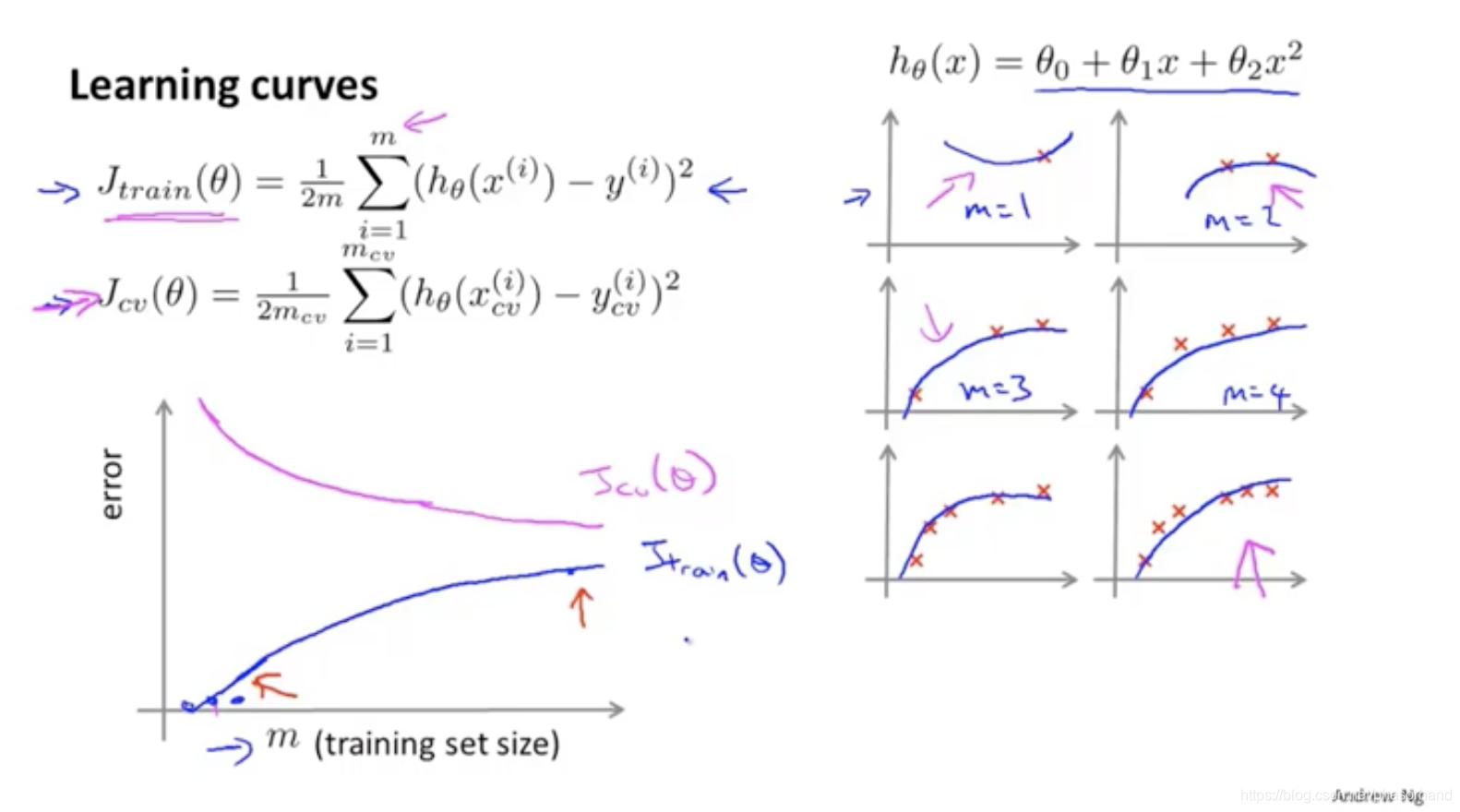
89 学习曲线
高偏差(欠拟合)
交叉验证误差和训练误差都很高,增加训练数据并不能优化模型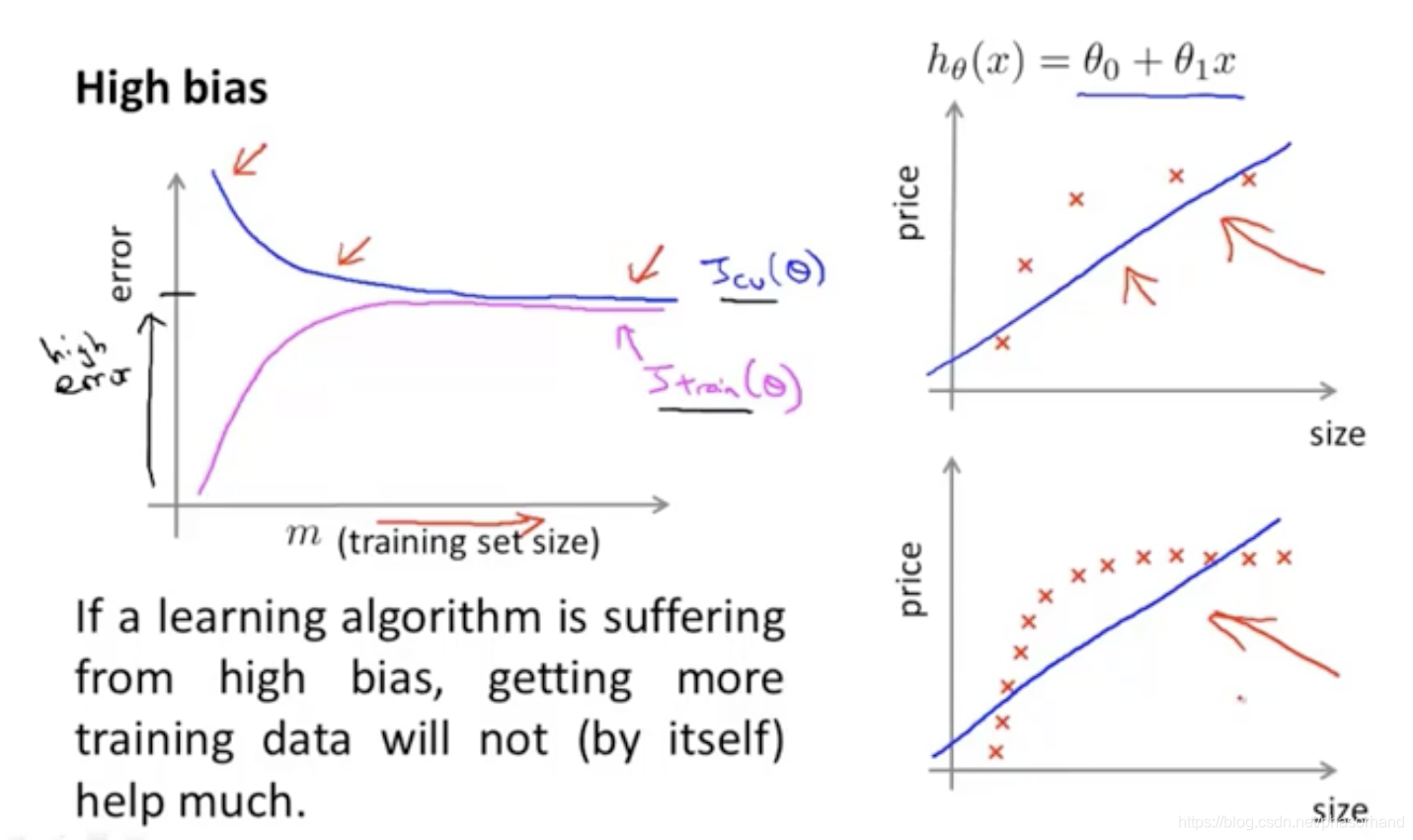
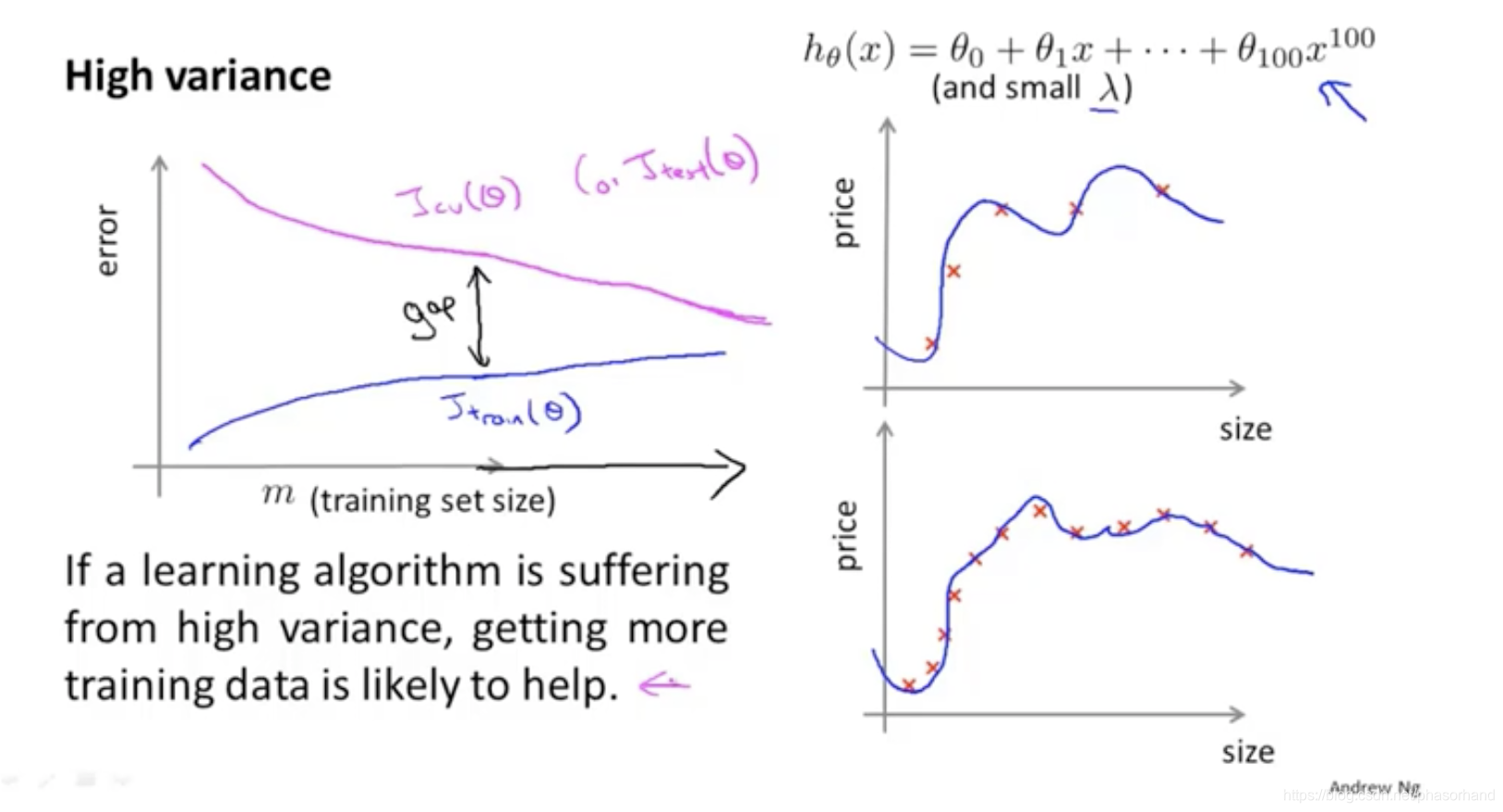
高方差(过拟合)
交叉验证误差和训练误差相差较大,数据增多有帮助
训练时多画这些曲线
决定接下来做什么
问题
- 弄清哪些方法有助于改善算法,哪些又是徒劳
高偏差(欠拟合):选的模型太简单,正则化严重
高方差(过拟合):选的模型太复杂或者训练数据不够,正则化不够

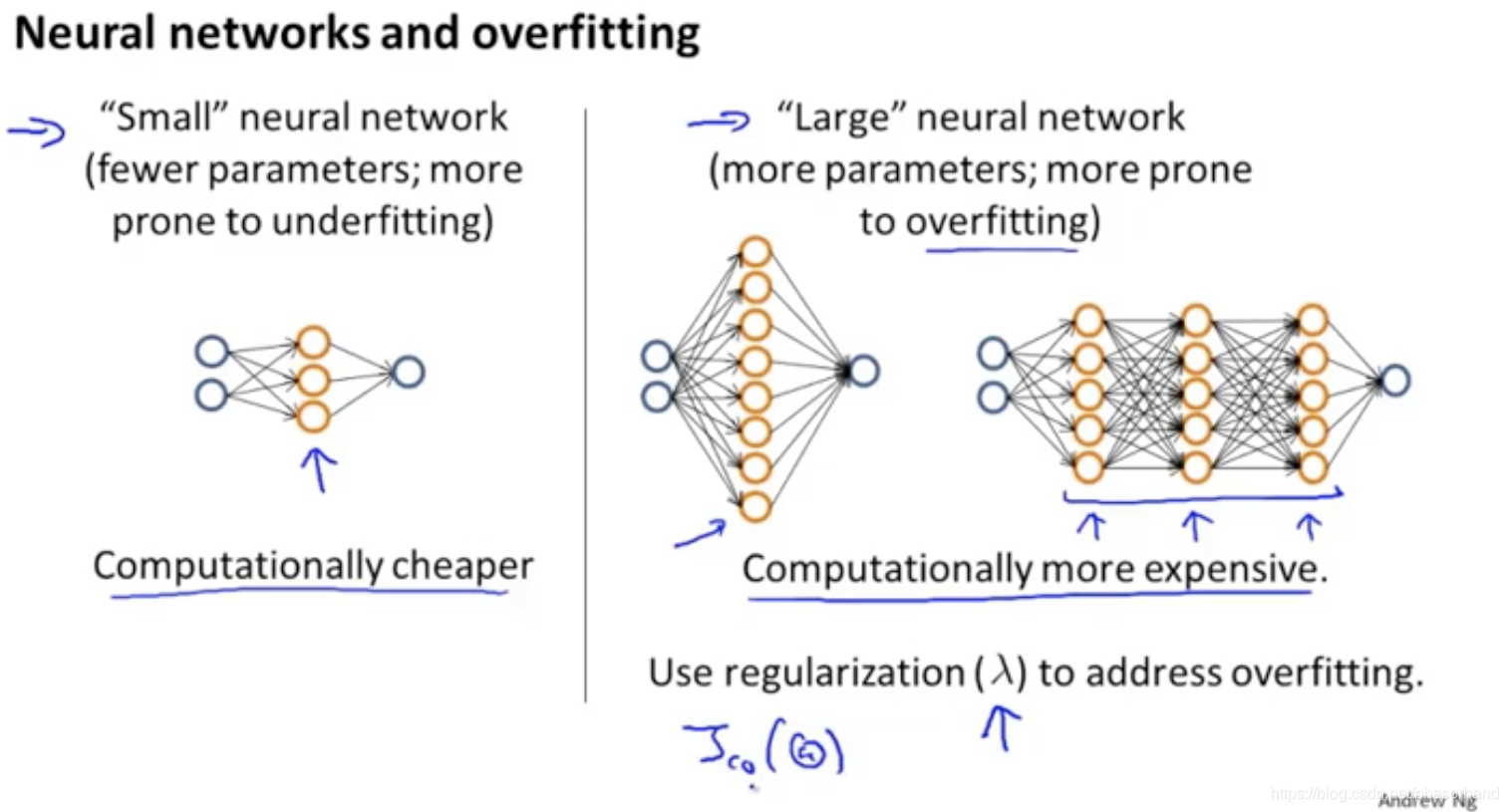
通常使用一个复杂神经网络并用正则化方法修正更好
隐藏层选择:选一个两个三个试试对比一下

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









