 Python神经网络分类与回归问题小结
Python神经网络分类与回归问题小结




二分类问题
import numpy as np
from tensorflow.keras.datasets import imdb
from tensorflow import keras
from tensorflow.keras import layers
from matplotlib import pyplot
# 10000 mean top 10000 appear frequency words
(tr_x, tr_y), (te_x, te_y) = imdb.load_data(num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
return results
tr_x_vec = vectorize_sequences(tr_x)
te_x_vec = vectorize_sequences(te_x)
tr_y_vec = np.asarray(tr_y).astype('float32')
te_y_vec = np.asarray(te_y).astype('float32')
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
val_x, tr_x_tr = tr_x_vec[:10000], tr_x_vec[10000:]
val_y, tr_y_tr = tr_y_vec[:10000], tr_y_vec[10000:]
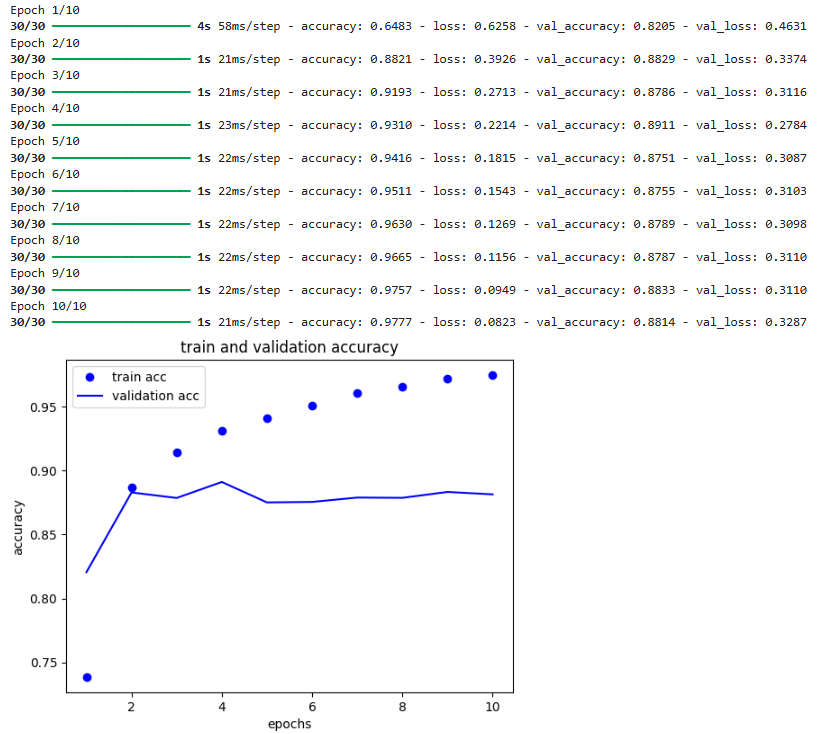
history = model.fit(tr_x_tr, tr_y_tr, epochs=10, batch_size=512, validation_data=(val_x, val_y))
history_dict = history.history
pyplot.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
pyplot.plot(range(1, 11), acc, 'bo', label='train acc')
pyplot.plot(range(1, 11), val_acc, 'b', label='validation acc')
pyplot.title('train and validation accuracy')
pyplot.xlabel('epochs')
pyplot.ylabel('accuracy')
pyplot.legend()
pyplot.show()
多分类问题
单标签是指一个样本可以有1个结果,多标签指一个样本可以有多个结果
多分类指结果的全集有几个,如果所有标签或结果只有两类,可以叫二分类
import numpy as np
from tensorflow.keras.datasets import reuters
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import layers
from tensorflow import keras
from matplotlib import pyplot
(tr_data, tr_labels), (te_data, te_labels) = reuters.load_data(num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
return results
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# y_tr = to_one_hot(tr_labels)
# y_te = to_one_hot(te_labels)
x_tr = vectorize_sequences(tr_data)
x_te = vectorize_sequences(te_data)
y_tr = to_categorical(tr_labels)
y_te = to_categorical(te_labels)
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(46, activation='softmax'),
])
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
val_x, tr_x_tr = x_tr[:1000], x_tr[1000:]
val_y, tr_y_tr = y_tr[:1000], y_tr[1000:]
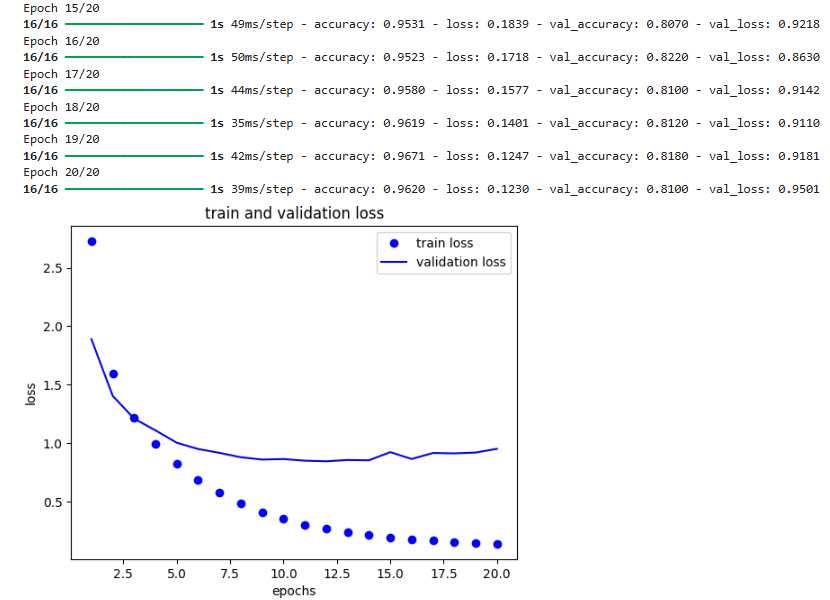
history = model.fit(tr_x_tr, tr_y_tr, epochs=20, batch_size=512, validation_data=(val_x, val_y))
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
pyplot.plot(epochs, loss, 'bo', label='train loss')
pyplot.plot(epochs, val_loss, 'b', label='validation loss')
pyplot.title('train and validation loss')
pyplot.xlabel('epochs')
pyplot.ylabel('loss')
pyplot.legend()
pyplot.show()
标量回归问题
回归问题常用均方误差作为损失函数 而分类问题用交叉熵
可训练数据较少时,可用k折交叉验证,并且模型可以简单点,如减少层数,减少每层神经元数量
import numpy as np
from tensorflow.keras.datasets import boston_housing
from tensorflow import keras
from tensorflow.keras import layers
from matplotlib import pyplot
(tr_data, tr_targets), (te_data, te_targets) = boston_housing.load_data()
mean, std = tr_data.mean(axis=0), tr_data.std(axis=0)
tr_data = (tr_data - mean) / std
te_data = (te_data - mean) / std
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1),
])
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
k = 4
num_val_samples = len(tr_data) // k
num_epochs = 180
all_scores = []
mae_history = []
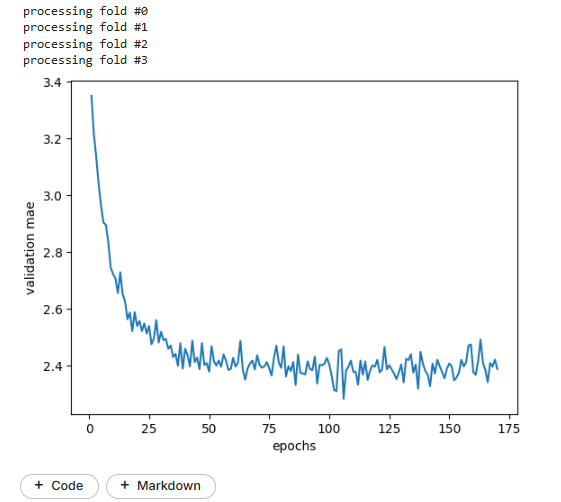
for i in range(k):
print(f'processing fold #{i}')
val_data = tr_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = tr_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_tr_data = np.concatenate([tr_data[:i * num_val_samples], tr_data[(i + 1) * num_val_samples:]], axis=0)
partial_tr_targets = np.concatenate([tr_targets[:i * num_val_samples], tr_targets[(i + 1) * num_val_samples:]], axis=0)
model = build_model()
history = model.fit(partial_tr_data, partial_tr_targets, epochs=num_epochs, batch_size=16, verbose=0, validation_data=(val_data, val_targets))
mae_history.append(history.history['val_mae'])
avg_mae = [np.mean([x[i] for x in mae_history]) for i in range(num_epochs)]
pyplot.plot(range(1, len(avg_mae) - 9), avg_mae[10:])
pyplot.xlabel('epochs')
pyplot.ylabel('validation mae')
pyplot.show()

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









