



安装
用conda创个虚拟环境,直接pip install torch torchvision即可
练习的代码都跑通了 写项目里了 开源项目地址 pytorch/official_tutorial · kimsmith/machine_learning - 码云 - 开源中国 (gitee.com)
pytorch doc链接Quickstart — PyTorch Tutorials 2.5.0+cu124 documentation
quickstart
处理数据
pytorch有两种最原始处理数据的方法:torch.utils.data.dataset和torch.utils.data.dataloader。dataset存储了一些已有的样本和样本对应的label,dataloader封装了dataset
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
def prepare_data():
tr = datasets.FashionMNIST(root='data', train=True, download=True, transform=ToTensor())
te = datasets.FashionMNIST(root='data', train=False, download=True, transform=ToTensor())
batch_size = 64
tr_loader = DataLoader(tr, batch_size=batch_size)
te_loader = DataLoader(te, batch_size=batch_size)
for x, y in te_loader:
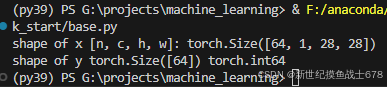
print(f'shape of x [n, c, h, w]: {x.shape}')
print(f'shape of y {y.shape} {y.dtype}')
break
prepare_data()国内如果数据下载速度慢 下载不下来,去kaggle开个notebook下载,在notebook直接拷贝上面面代码下载就行
创建模型
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def create_model():
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'device is {device}')
model = NeuralNetwork().to(device)
print(model)
def main():
# prepare_data()
create_model()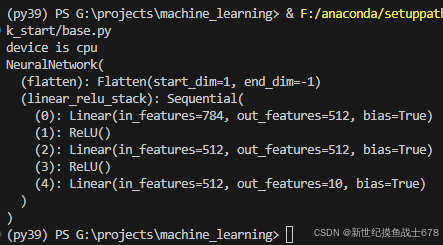
训练和测试
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (x, y) in enumerate(dataloader):
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(x)
print(f'loss: {loss:>7f} {current:>5d}/{size:>5d}')
def test(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model(x)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
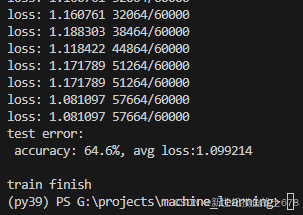
print(f'test error:\n accuracy: {(100*correct):>0.1f}%, avg loss:{test_loss:>8f}\n')
def train_and_test(tr_loader, te_loader, model):
# define loss and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
epochs = 5
for i in range(epochs):
print(f'epoch: {i + 1}')
train(tr_loader, model, loss_fn, optimizer)
test(te_loader, model, loss_fn, optimizer)
print('train finish')
def main():
tr_loader, te_loader = prepare_data()
model = create_model()
train_and_test(tr_loader, te_loader, model)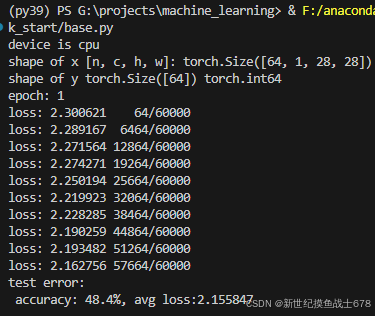
保存与加载模型
def save_model(model):
model_path = "models/fasion_mnist.pth"
torch.save(model.state_dict(), model_path)
print(f'save model {model_path} success')
def load_model_and_test_one(model_path, sample):
# load model
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load(model_path, weights_only=True))
print('load model success')
# predict one sample
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
model.eval()
x, y = sample[0], sample[1]
with torch.no_grad():
x = x.to(device)
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'predicted: {predicted}, actual: {actual}')
def main():
tr_loader, te_loader = prepare_data()
model = create_model()
train_and_test(tr_loader, te_loader, model)
save_model(model)
model_path = "models/fasion_mnist.pth"
load_model_and_test_one(model_path, te_loader.dataset[0])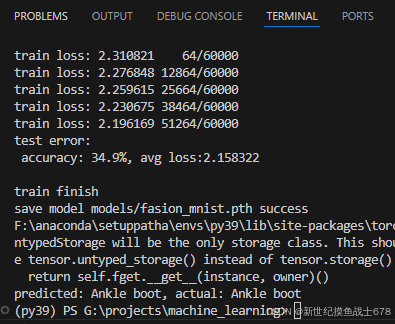
张量
初始化张量
import torch
import numpy as np
def main():
# directly from list
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
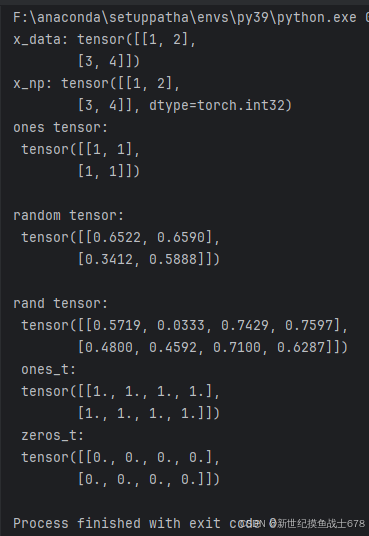
print(f'x_data: {x_data}')
# from np array
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
print(f'x_np: {x_np}')
# from other tensors
x_ones = torch.ones_like(x_data)
print(f'ones tensor:\n {x_ones} \n')
x_rand = torch.rand_like(x_data, dtype=torch.float)
print(f'random tensor:\n {x_rand} \n')
# create tensor by specify shape
shape = (2, 4)
rand_t = torch.rand(shape)
ones_t = torch.ones(shape)
zeros_t = torch.zeros(shape)
print(f'rand tensor:\n {rand_t}\n ones_t:\n {ones_t}\n zeros_t:\n {zeros_t}')
if __name__ == '__main__':
main()


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









