



0 绪论
本系列机器学习笔记源于 python机器学习基础教程 Andreas C.Müller Sarah Guido,有兴趣可看原书
1 能干啥
识别人脸,图像,等自动化行为,根据已有特征与结果进行学习,对未知的特征进行判断
2 概念
2.1 监督学习和非监督学习
监督学习有输入输出,非监督学习只有输入没有输出
比如有很多花朵特征(颜色,叶子大小等)和花朵种类,目标是根据花朵特征判断花朵种类,这种情况既有输入(花朵特征)也有输出(花朵种类),就是监督学习。非监督学习是只有花朵特征,没有输出信息
2.2 训练集与测试集
对监督学习来说,有输入和输出,用来训练模型的数据叫训练集,用训练好的模型对未知数据做出预测,未知数据的输入与未知数据预测的结果称为测试集,故名思意,用来测试模型的数据叫测试集
3 机器学习用什么语言
有python, matlab, r等,python因易用性与大量库,使用量不少
4 机器学习需要的库(都是python库)
4.1 scikit-learn
开源项目,也是机器学习的主要功能库
用anaconda,安装的话,先到自己创的conda环境下,然后conda install scikit-learn等会就装好了
4.2 其他工具库
机器学习需要绘图,特征运算等其他辅助功能,有些库可以帮我们快速便捷进行这些运算,主要看下绘图
4.2.1 matplotlib
主要能画图,各种图,来个例子
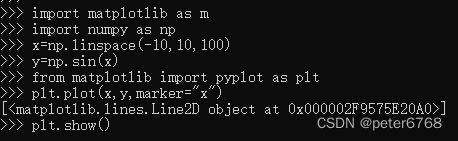
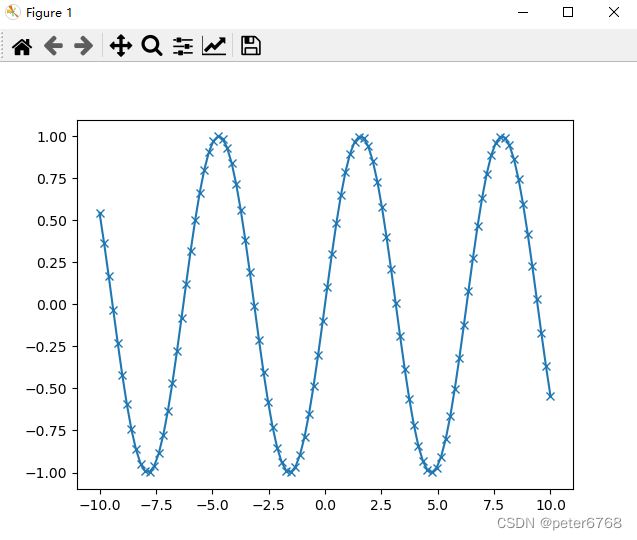
4.2.2 pandas
主要可处理,分析数据,主要数据结构是DataFrame,模仿了R语言的DataFrame,一个DataFrame可理解为一个excel,所以可以很好对接excel
来个例子

4.2.3 mglearn
也可用来绘图,看最后段落的例子
5 实例:鸢尾花分类
即根据鸢尾花的外形数据判断花种类,如花瓣长宽,花萼长宽,根据这些信息,判断这花是哪种鸢尾花
5.1 导入数据

5.2 区分训练数据和测试数据
训练数据是用来训练模型的,测试数据是用来测试模型的
所有鸢尾花特征数据和花种类都在iris['data']中,可以手动将iris.data中数据分为训练数据和测试数据,也可以调现有接口sklearn.model_selection.train_test_split
可按25%:75%比例来分配测试数据和训练数据
为每次获取一样的数据,可给train_test_split传入数据时传相同随机数种子
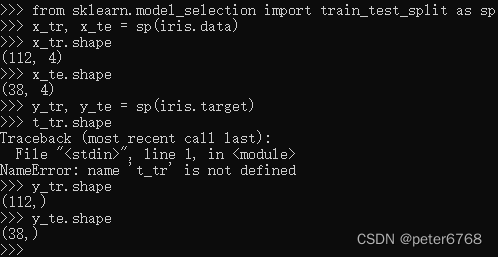
搞错了,都没设置random_state,可以直接这样
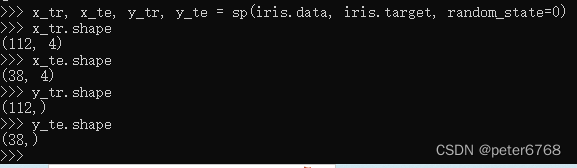
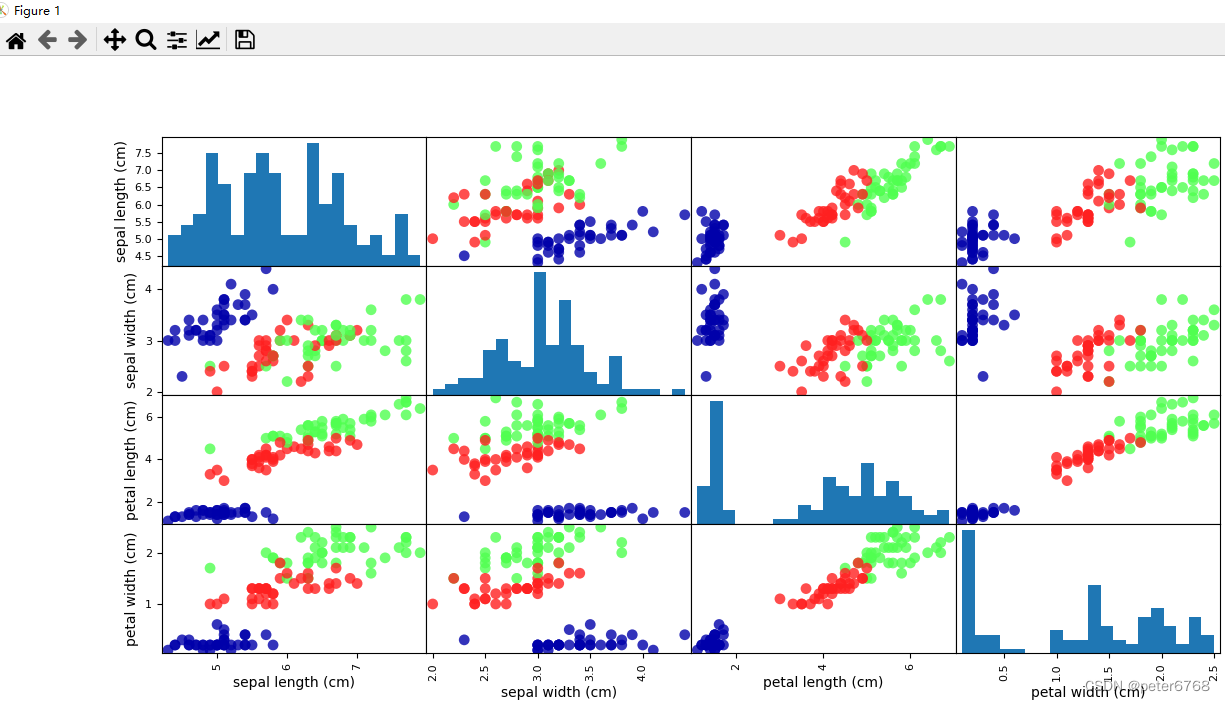
5.3 看数据散点图矩阵
iris_df=pd.DataFrame(xte, columns=iris.feature_names)
import matplotlib.pyplot as plt # 好像jupyter不用导这个就能出图,cmd的话得导这个出图
import mglearn as mg
grr = pd.plotting.scatter_matrix(iris_df, c=ytr, figsize=(15,15), marker='o', hist_kwds={'bin': 20}, s=60, alpha=.8, cmap=mg.cm3)
plt.show()
反对角线的应该是分布图
5.4 构建模型:k临近算法
当给定一个输入时,在训练集中查找与输入最接近的k个输入对应的输出(鸢尾花种类),输出中哪个结果最多,最终结果就是哪个
5.4.1 构造模型
先构造一个k临近算法模型,k可在创建模型时作为参数传入
from sklearn.neighbors import KNeighborsClassifier as KN
knn = KN(n_neighbors=1)
5.4.2 训练模型
训练模型可通过模型对象fit方法实现,传入数据为训练集
knn.fit(xtr, ytr)
5.4.3 用模型做预测
先随便构造一个输入,尝试对其预测
输入可为二维列表,也可为numpy的二维数组(numpy.array)
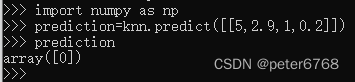
预测结果表示这种花是id为0的种类(setosa),问题是结果是否准确
5.4.4 评估模型
用测试集进行评估
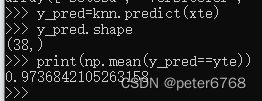
也就是说对测试集预测后,准确度约为97.3%


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









