




问题导读
1.你认为spark该如何入门?
2.你认为spark入门编程需要哪些步骤?
3.本文介绍了spark哪些编程知识?![]()

spark学习一般都具有hadoop基础,所以学习起来更容易多了。如果没有基础,可以参考零基础学习hadoop到上手工作线路指导(初级篇)。具有基础之后,一般都是按照官网或则视频、或则文档,比如搭建spark,运行spark例子。后面就不知道做什么了。这里整体梳理一下。希望对大家有所帮助。
1.spark场景
在入门spark之前,首先对spark有些基本的了解。比如spark场景,spark概念等。推荐参考
Spark简介:适用场景、核心概念、创建RDD、支持语言等介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9389
2.spark部署
首先还是说些基础性的内容,非零基础的同学,可以跳过。
首先还是spark环境的搭建。
about云日志分析项目准备6:Hadoop、Spark集群搭建
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20620
spark环境搭建完毕,例子运行完毕。后面就不知道干啥了。
这时候我们就需要了解spark。
从不同角度,可以有多种不同的方式:如果我们从实战工作的角度,下面我们就需要了解开发方面的知识
如果我们从知识、理论的角度,我们就需要了解spark生态系统
下面我们从不同角度来介绍
3.spark实战
3.1spark开发环境
比如我们从实战的角度,当我们部署完毕,下面我们就可以接触开发方面的知识。
对于开发,当然是首先是开发工具,比如eclipse,IDEA。对于eclipse和IDEA两个都有选择的,看你使用那个更顺手些。
下面是个人总结希望对大家有帮助[二次修改新增内容]
spark开发环境详细教程1:IntelliJ IDEA使用详细说明
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22320
spark开发环境详细教程2:window下sbt库的设置
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22409
spark开发环境详细教程3:IntelliJ IDEA创建项目
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22410
spark开发环境详细教程4:创建spark streaming应用程序
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22465
更多了解即可:
Spark集成开发环境搭建-eclipse
http://www.aboutyun.com/forum.php?mod=viewthread&tid=6772
用IDEA开发spark,源码提交任务到YARN
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20316
Spark1.0.0 开发环境快速搭建
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8403
spark开发环境中,如何将源码打包提交到集群
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20979
田毅-Spark开发及本地环境搭建指南
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20313
Spark 开发环境IntelliJ IDEA图文教程、视频系统教程
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10122
3.2spark开发基础
开发环境中写代码,或则写代码的时候,遇到个严重的问题,Scala还不会。这时候我们就需要补Scala的知识。如果是会Java或则其它语言,可能会阅读C,.net,甚至Python,但是Scala,你可能会遇到困难,因为里面各种符号和关键字,所以我们需要真正的学习下Scala。下面内容,是个人的总结,仅供参考
#######################
about云spark开发基础之Scala快餐
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20303
spark开发基础之从Scala符号入门Scala
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20159
spark开发基础之从关键字入门Scala
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20223
更多内容:
spark开发基础之Scala快餐:开发环境Intellij IDEA 快捷键整理【收藏备查】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20380
学习Scala的过程中,参考了以下资料
《快学Scala》完整版书籍分享
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8713
scala入门视频【限时下载】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12434
更多可以搜索Scala
http://so.aboutyun.com/
#######################
相信上面的资料,足以让你搞懂Scala。Scala会了,开发环境、代码都写好了,下面我们就需要打包了。该如何打包。这里打包的方式有两种:
1.maven
2.sbt
有的同学要问,哪种方式更好。其实两种都可以,你熟悉那个就使用那个即可。
下面提供一些资料
scala eclipse sbt( Simple Build Tool) 应用程序开发
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9340
使用maven编译Spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=11746
更多资料
Spark大师之路:使用maven编译Spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10842
用SBT编译Spark的WordCount程序
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8587
如何用maven构建spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12261
3.3spark开发知识
spark 开发包括spark core的相关组件及运算,还有spark streaming,spark sql,spark mlib,GraphX.
###########################
下面的知识是关于spark1.x的,关于1.x其实有了基础,那么spark2.x学习来是非常快的。那么他们之间的区别在什么地方?最大的区别在编程方面是spark context,sqlcontext,hivecontext,都使用一个类即可,那就是SparkSession。他的编程是非常方便的。比如
通过SparkSession如何创建rdd,通过下面即可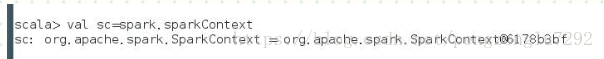
再比如如何执行spark sql
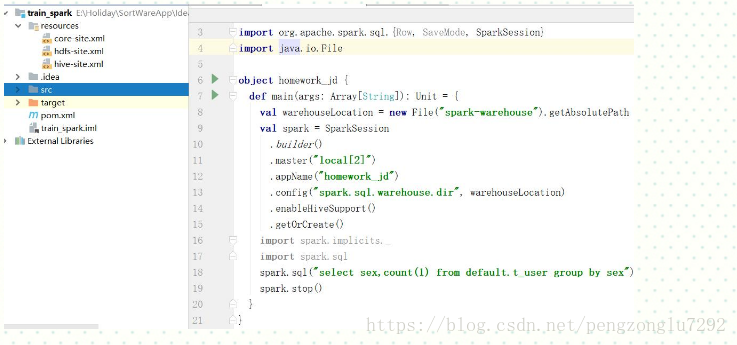
更多参考:
spark2:SparkSession思考与总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23381
SparkSession使用方法介绍【spark2.0】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=19632
spark2使用遇到问题总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=24050
spark2.0文档【2016英文】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=18970
spark2 sql读取数据源编程学习样例1:程序入口、功能等知识详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23484
spark2 sql读取数据源编程学习样例2:函数实现详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23489
使用spark2 sql的方式有哪些
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23541
spark2之DataFrame如何保存【持久化】为表
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23523
spark2 sql编程样例:sql操作
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23501
spark2 sql读取json文件的格式要求
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23478
spark2 sql读取json文件的格式要求续:如何查询数据
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23483
spark2的SparkSession思考与总结2:SparkSession包含哪些函数及功能介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23407
spark2.2以后版本任务调度将增加黑名单机制
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23346
##########################
3.3.1spark 编程
说到spark编程,有一个不能绕过的SparkContext,相信如果你接触过spark程序,都会见到SparkContext。那么他的作用是什么?
SparkContext其实是连接集群以及获取spark配置文件信息,然后运行在集群中。如下面程序可供参考
[Scala] 纯文本查看 复制代码
| 1 2 3 4 5 6 7 |
|
下面图示为SparkContext作用
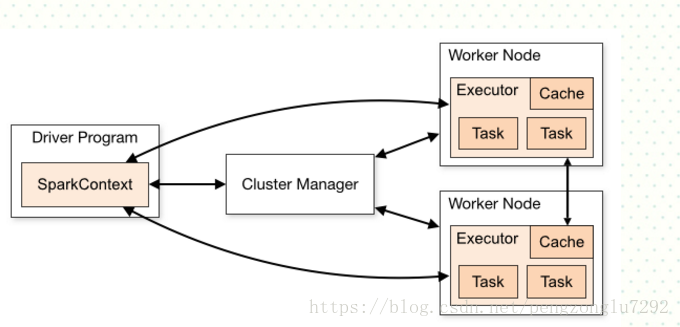
当然还有 SQLContext 和HiveContext作用是类似的,同理还有hadoop的Context,它们的作用一般都是全局的。除了SparkContext,还有Master、worker、DAGScheduler、TaskScheduler、Executor、Shuffle、BlockManager等,留到后面理论部分。这里的入门更注重实战操作
我们通过代码连接上集群,下面就该各种内存运算了。
比如rdd,dataframe,DataSet。如果你接触过spark,相信rdd是经常看到的,DataFrame是后来加上的。但是他们具体是什么。可以详细参考spark core组件:RDD、DataFrame和DataSet介绍、场景与比较
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20902
看到上面我们其实可能对它们还没有认识到本质,其实他们就是内存的数据结构。那么数据结构相信我们应该都了解过,最简单、我们经常接触的就是数组了。而rdd,跟数组有一个相同的地方,都是用来装数据的,只不过复杂度不太一样而已。对于已经了解过人来说,这是理所当然的。这对于初学者来说,认识到这个程度,rdd就已经不再神秘了。那么DataFrame同样也是,DataFrame是一种以RDD为基础的分布式数据集.
rdd和DataFrame在spark编程中是经常用到的,那么该如何得到rdd,该如何创建DataFrame,他们之间该如何转换。
创建rdd有三种方式,
1.从scala集合中创建RDD
2.从本地文件系统创建RDD
3.从HDFS创建RDD
详细参考
spark小知识总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20920
如何创建dataframe
df<-data.frame(A=c(NA),B=c(NA))
当然还可以通过rdd转换而来,通过toDF()函数实现
rdd.toDF()
dataframe同样也可以转换为rdd,通过.rdd即可实现
如下面
val rdd = df.toJSON.rdd
为了更好的理解,在看下面例子
[Scala] 纯文本查看 复制代码
| 1 2 3 4 |
|
即为rdd转换为dataframe.
RDD和DataFrame各种操作
上面只是简单的操作,更多还有rdd的action和TransformationActions操作如:reduce,collect,count,foreach等
Transformation如,map,filter等
更多参考
Spark RDD详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7214
DataFrame同理
DataFrame 的函数
collect,collectAsList等
dataframe的基本操作
如cache,columns 等
更多参考
spark DataFrame 的函数|基本操作|集成查询记录
http://www.aboutyun.com/blog-1330-3165.html
spark数据库操作
很多初级入门的同学,想在spark中操作数据库,比如讲rdd或则dataframe数据导出到mysql或则oracle中。但是让他们比较困惑的是,该如何在spark中将他们导出到关系数据库中,spark中是否有这样的类。这是因为对编程的理解不够造成的误解。在spark程序中,如果操作数据库,spark是不会提供这样的类的,直接引入操作mysql的库即可,比如jdbc,odbc等。
比如下面Spark通过JdbcRDD整合 Mysql(JdbcRDD)开发
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9826
更多可百度。
经常遇到的问题
在操作数据中,很多同学遇到不能序列化的问题。因为类本身没有序列化.所以变量的定义与使用最好在同一个地方。
想了解更详细,可参考
不能序列化解决方法 org.apache.spark.sparkException:Task not serializable
http://www.aboutyun.com/home.php?mod=space&uid=29&do=blog&id=3362
小总结
如果上面已经都会了,那么spark基本编程和做spark相关项目外加一些个人经验相信应该没有问题。
3.3.2spark sql编程
spark sql为何会产生。原因很多,比如用spark编程完成比较繁琐,需要多行代码来完成,spark sql写一句sql就能搞定了。那么spark sql该如何使用。
1.初始化spark sql
为了开始spark sql,我们需要添加一些imports 到我们程序。如下面例子1
例子1Scala SQL imports
[Scala] 纯文本查看 复制代码
| 1 2 3 4 |
|
下面引用一个例子
首先在maven项目的pom.xml中添加Spark SQL的依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.2</version>
</dependency>[Scala] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
package[url=http://www.aboutyun.com]www.aboutyun.com[/url]
importorg.apache.spark.{SparkConf, SparkContext}
importorg.apache.spark.sql.SQLContext
objectInferringSchema {
defmain(args:Array[String]) {
//创建SparkConf()并设置App名称
valconf=newSparkConf().setAppName("aboutyun")
//SQLContext要依赖SparkContext
valsc=newSparkContext(conf)
//创建SQLContext
valsqlContext=newSQLContext(sc)
//从指定的地址创建RDD
vallineRDD=sc.textFile(args(0)).map(_.split(" "))
//创建case class
//将RDD和case class关联
valpersonRDD=lineRDD.map(x=> Person(x(0).toInt, x(1), x(2).toInt))
//导入隐式转换,如果不到人无法将RDD转换成DataFrame
//将RDD转换成DataFrame
importsqlContext.implicits._
valpersonDF=personRDD.toDF
//注册表
personDF.registerTempTable("person")
//传入SQL
valdf=sqlContext.sql("select * from person order by age desc ")
//将结果以JSON的方式存储到指定位置
df.write.json(args(1))
//停止Spark Context
sc.stop()
}
}
//case class一定要放到外面
caseclassPerson(id:Int, name:String, age:Int)
参考:csdn 绛门人,更多例子大家也可网上搜索
我们看到上面例子中 sqlContext.sql可以将sql语句放入到函数中。
关于spark sql的更多内容推荐Spark Sql系统入门1:什么是spark sql及包含哪些组件
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20910
Spark Sql系统入门2:spark sql精简总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21002
Spark Sql系统入门3:spark sql运行计划精简
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21032
about云日志分析项目准备6-5-2:spark应用程序中如何嵌入spark sql
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21078
spark sql完毕,后面我们继续spark streaming。
3.3.3spark streaming编程
我么知道spark具有实时性,那么spark的实时性就是通过spark streaming来实现的。spark streaming可以实时跟踪页面统计,训练机器学习模型或则自动检测异常等.
如何使用spark streaming
大数据编程很多都是类似的,我们还是需要看下StreamingContext.
为了初始化Spark Streaming程序,一个StreamingContext对象必需被创建,它是Spark Streaming所有流操作的主要入口。一个StreamingContext 对象可以用SparkConf对象创建。StreamingContext这里可能不理解,其实跟SparkContext也差不多的。(可参考让你真正理解什么是SparkContext, SQLContext 和HiveContext)。同理也有hadoop Context,它们都是全文对象,并且会获取配置文件信息。那么配置文件有哪些?比如hadoop的core-site.xml,hdfs-site.xml等,spark如spark-defaults.conf等。这时候我们可能对StreamingContext有了一定的认识。下面一个例子
为了初始化Spark Streaming程序,一个StreamingContext对象必需被创建,它是Spark Streaming所有流操作的主要入口。
一个StreamingContext 对象可以用SparkConf对象创建。
[Scala] 纯文本查看 复制代码
| 1 2 3 4 |
|
appName表示你的应用程序显示在集群UI上的名字,master 是一个Spark、Mesos、YARN集群URL 或者一个特殊字符串“local”,它表示程序用本地模式运行。当程序运行在集群中时,你并不希望在程序中硬编码 master ,而是希望用 sparksubmit启动应用程序,并从 spark-submit 中得到 master 的值。对于本地测试或者单元测试,你可以传递“local”字符串在同
一个进程内运行Spark Streaming。需要注意的是,它在内部创建了一个SparkContext对象,你可以通过 ssc.sparkContext访问这个SparkContext对象。
批时间片需要根据你的程序的潜在需求以及集群的可用资源来设定,你可以在性能调优那一节获取详细的信息.可以利用已经存在的 SparkContext 对象创建 StreamingContext 对象。
[Scala] 纯文本查看 复制代码
| 1 2 3 |
|
当一个上下文(context)定义之后,你必须按照以下几步进行操作
- 定义输入源;
- 准备好流计算指令;
- 利用 streamingContext.start() 方法接收和处理数据;
- 处理过程将一直持续,直到 streamingContext.stop() 方法被调用。
StreamingContext了解了,还有个重要的概念需要了解DStream.
Spark Streaming支持一个高层的抽象,叫做离散流( discretized stream )或者 DStream ,它代表连续的数据流。DStream既可以利用从Kafka, Flume和Kinesis等源获取的输入数据流创建,也可以 在其他DStream的基础上通过高阶函数获得。在内部,DStream是由一系列RDDs组成。
举例:
一个简单的基于Streaming的workCount代码如下:
[Scala] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 |
|
这段代码实现了当指定的路径有新文件生成时,就会对这些文件执行wordcount,并把结果print。具体流程如下:
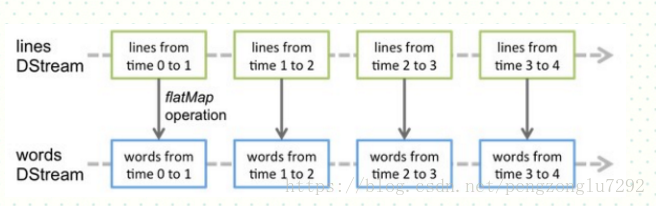
代码诠释:
使用Spark Streaming就需要创建StreamingContext对象(类似SparkContext)。创建StreamingContext对象所需的参数与SparkContext基本一致,包括设定Master节点(setMaster),设定应用名称(setAppName)。第二个参数Seconds(30),指定了Spark Streaming处理数据的时间间隔为30秒。需要根据具体应用需要和集群处理能力进行设置。
val lines = ssc.textFileStream("file:///home/spark/data")为创建lines Dstream
val words = lines.flatMap(_.split(" "))为通过flatMap转换为words Dstream
我们在引一例,比如创建Twitter
val tweets=ssc.twitterStream()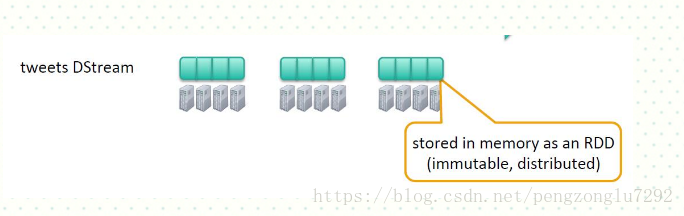
其中为tweets为DStream上面内容来自
让你真正明白spark streaming
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21141
DStream的transformation
DStream与RDD,DataFrame类似的,也有自己的transformation。如下
| Transformation | Meaning |
| map(func) | 对 DStream 中的各个元素进行 func 函数操作, 然后返回一个新的 DStream. |
| flatMap(func) | 与 map 方法类似, 只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数 func 返回值为 true 的 DStream 元素并返回一个新的 DStream |
| repartition(numPartitions) | 增加或减少 DStream 中的分区数, 从而改变 DStream 的并行度 |
| union(otherStream) | 将源 DStream 和输入参数为 otherDStream 的元素合并, |
| count() | 通过对 DStreaim 中的各个 RDD 中的元素进行计数, 然后返回只有一个元素 |
| reduce(func) | 对源 DStream 中的各个 RDD 中的元素利用 func 进行聚合操作, |
| countByValue() | 对于元素类型为 K 的 DStream, 返回一个元素为( K,Long) 键值对形式的 |
| reduceByKey(func, | 利用 func 函数对源 DStream 中的 key 进行聚合操作, 然后返回新的( K, V) 对 |
| join(otherStream, | 输入为( K,V)、 ( K,W) 类型的 DStream, 返回一个新的( K, ( V, W) 类型的 |
| cogroup(otherStream, | 输入为( K,V)、 ( K,W) 类型的 DStream, 返回一个新的 (K, Seq[V], Seq[W]) |
| transform(func) | 通过 RDD-to-RDD 函数作用于源码 DStream 中的各个 RDD,可以是任意的 RDD 操作, 从而返回一个新的 RDD |
| updateStateByKey(func) | 根据于 key 的前置状态和 key 的新值, 对 key 进行更新, |
| window | 对滑动窗口数据执行操作 |
除了DStream,还有个重要的概念,需要了解
windows滑动窗体
我们知道spark streaming的数据流是Dstream,而Dstream由RDD组成,但是我们将这些RDD进行有规则的组合,比如我们以3个RDD进行组合,那么组合起来,我们需要给它起一个名字,就是windows滑动窗体
更多内容可参考
spark streaming知识总结2
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21173
上面对spark streaming有了一定的了解,更多编程知识可参考下面内容
SparkStreaming运行三种方式
http://www.aboutyun.com/forum.php?mod=viewthread&tid=18892
spark streaming知识总结1
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21307
sparkstreaming数据通过Scala实现存储到数据库
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20753
Spark Streaming日志分析思考、选择方案及部分代码实现
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21593
透过WordCount案例快速理解SparkStreaming工作原理分享
http://www.aboutyun.com/forum.php?mod=viewthread&tid=19688
刘永平-Spark-streaming在京东的项目实践
http://www.aboutyun.com/forum.php?mod=viewthread&tid=18924
Spark-Streaming编程指南
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21257
上面具备spark streaming知识后,下面是关于about云日志分析使用到的spark streaming大家可参考
使用Spark Streaming + Kafka 实现有容错性的实时统计程序
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20427
about云日志分析项目准备10:使用Intellij Idea搭建Spark Streaming开发环境(SBT版本)
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20855
about云日志分析项目准备10-4:将Spark Streaming程序运行在Spark集群上
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21034
about云日志分析项目准备11:spark streaming 接收 flume 监控目录的日志文件
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21229
about云日志分析项目准备11-1:spark streaming+spark sql 实现业务
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21599
下面就是spark MLlib和GraphX编程,对于初级入门来说用到的不多,也可以不用看。MLlib 是Spark的可以扩展的机器学习库,由以下部分组成:通用的学习算法和工具类,包括分类,回归,聚类,协同过滤,降维。GraphX是spark的一个新组件用于图和并行图计算.下面给大家推荐一些资料
3.4.spark MLlib编程
使用Spark MLlib给豆瓣用户推荐电影
http://www.aboutyun.com/forum.php?mod=viewthread&tid=16430
MLlib回归算法(线性回归、决策树)实战演练--Spark学习(机器学习)
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17183
Spark_Mllib_实践与优化_雷宗雄
http://www.aboutyun.com/forum.php?mod=viewthread&tid=18739
Spark MLlib系列——程序框架
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8552
Spark MLlib算法之KMeans应用实例讲解【附代码下载】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21436
Spark MLlib Statistics统计
http://www.aboutyun.com/forum.php?mod=viewthread&tid=13054
Spark MLlib之 KMeans聚类算法详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=19745
MLlib分类算法实战演练--Spark学习(机器学习)
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17184
about云系列spark入门5:MLlib 介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=14183
Spark0.9分布式运行MLlib的线性回归算法
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10793
求一spark mllib视频
http://www.aboutyun.com/forum.php?mod=viewthread&tid=19061
ALS 在 Spark MLlib 中的实现--孟祥瑞
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12988
3.5.spark GraphX
Spark GraphX详细介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=13783
Spark GraphX在淘宝的实践
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12970
Spark中文手册8:spark GraphX编程指南(1)
http://www.aboutyun.com/forum.php?mod=viewthread&tid=11589
Spark中文手册9:spark GraphX编程指南(2)
http://www.aboutyun.com/forum.php?mod=viewthread&tid=11601
Apache Spark源码走读之14 -- Graphx实现剖析
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10957
spark图感知及图数据挖掘:图流合壁,基于Spark Streaming和GraphX的动态图计算
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12277
图流合璧——基于Spark Streaming和GraphX的动态图计算
http://www.aboutyun.com/forum.php?mod=viewthread&tid=13799
用Apache Spark进行大数据处理 -用Spark GraphX进行图数据分析
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21913
about云系列spark入门6:GraphX 介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=14220
最新100份开源大数据架构论文之45:spark graphx
http://www.aboutyun.com/forum.php?mod=viewthread&tid=14239
上面介绍了从实战学习的角度去入门学习,后面有时间从理论角度来入门spark。
更多资料推荐
Spark1.0.0 学习路线指导
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8421
Spark学习总结---入门
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20710
spark个人学习总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=14584
spark入门教程及经验总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=11128
本文链接:http://www.aboutyun.com/forum.php?mod=viewthread&tid=21959
pdf下载
链接:http://pan.baidu.com/s/1eROBzrW 密码:5n7a

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









