




 本文详细介绍了Spark的定义、生态系统模块、使用模式,重点解析了Spark的最核心数据结构——RDD,包括其分区机制和容错机制。讨论了RDD的操作类型,如Transformation和Action,并详细阐述了Spark的DAG、Stage划分、任务调度和shuffle机制,深入理解Spark的计算过程和优化策略。
本文详细介绍了Spark的定义、生态系统模块、使用模式,重点解析了Spark的最核心数据结构——RDD,包括其分区机制和容错机制。讨论了RDD的操作类型,如Transformation和Action,并详细阐述了Spark的DAG、Stage划分、任务调度和shuffle机制,深入理解Spark的计算过程和优化策略。
一.定义
Spark是一种分布式,快速的,通用 的,可靠的,免费的计算框架。
二.Spark的生态系统模块
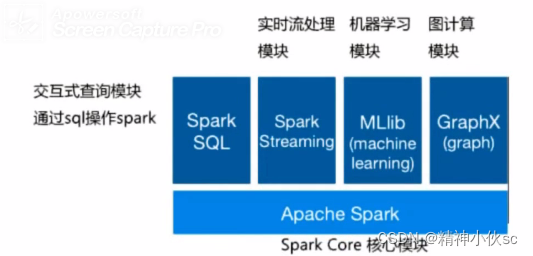
三.Spark的使用模式:
1.Local 本地单机模式:一般用于测试和练习
2.Standalone Spark集群模式:Spark集群的资源管理由spark自己来负责
3.On Yarn Spark集群模式:Spark集群的资源由Yarn来管理
四 .Spark最核心的数据结构——RDD弹性分布式数据集
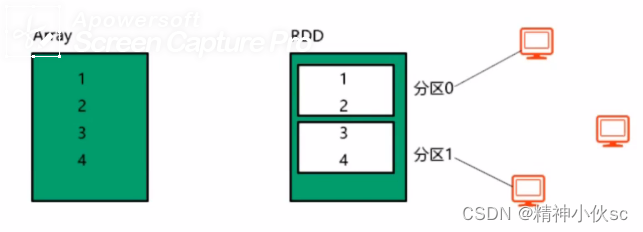
RDD与普通集合的区别:
1.RDD有分区机制,可以分布式,并行的处理同一个RDD数据集,从而极大提高处理效率。分区数量由程序而定
2.RDD有容错机制,即数据丢失后,可以进行恢复
读取外部存储文件系统,把文件数据读取为一个RDD
//spark环境参数对象
val conf = new SparkConf(),setMaster(“local”).setAppName(“wordcount”)
//spark上下文对象
val sc =new SparkContext(conf)
//读取linux本地文件:
val rdd= sc.textFile(“file://home/1.txt”,2)
//读取hdfs:
val rdd= sc.textFile(“hdfs://hadoop01:9000/1.txt”,2)
五.RDD操作类型
1.Transformation变化操作:懒操作,调用后不是马上执行,比如textFile方法
2.Action操作:触发执行,比如collect
3.Controller控制操作
1.1常用的Transformation操作
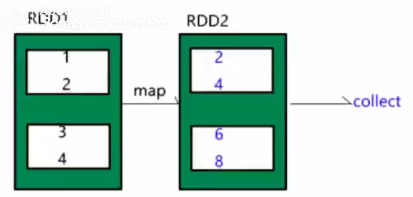
map(func)
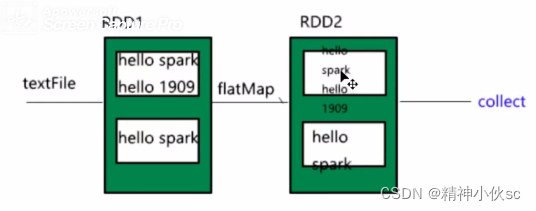
flatmap(func)
常用的懒方法
①map
②flatMap
③filter
④sortBy
⑤sortByKey
⑥groupByKey
⑦groupBy
⑧ReduceByKey
⑨intersection
⑩union
⑪subtractf
⑫dist
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









