









如何计算 离散变量 的相关系数
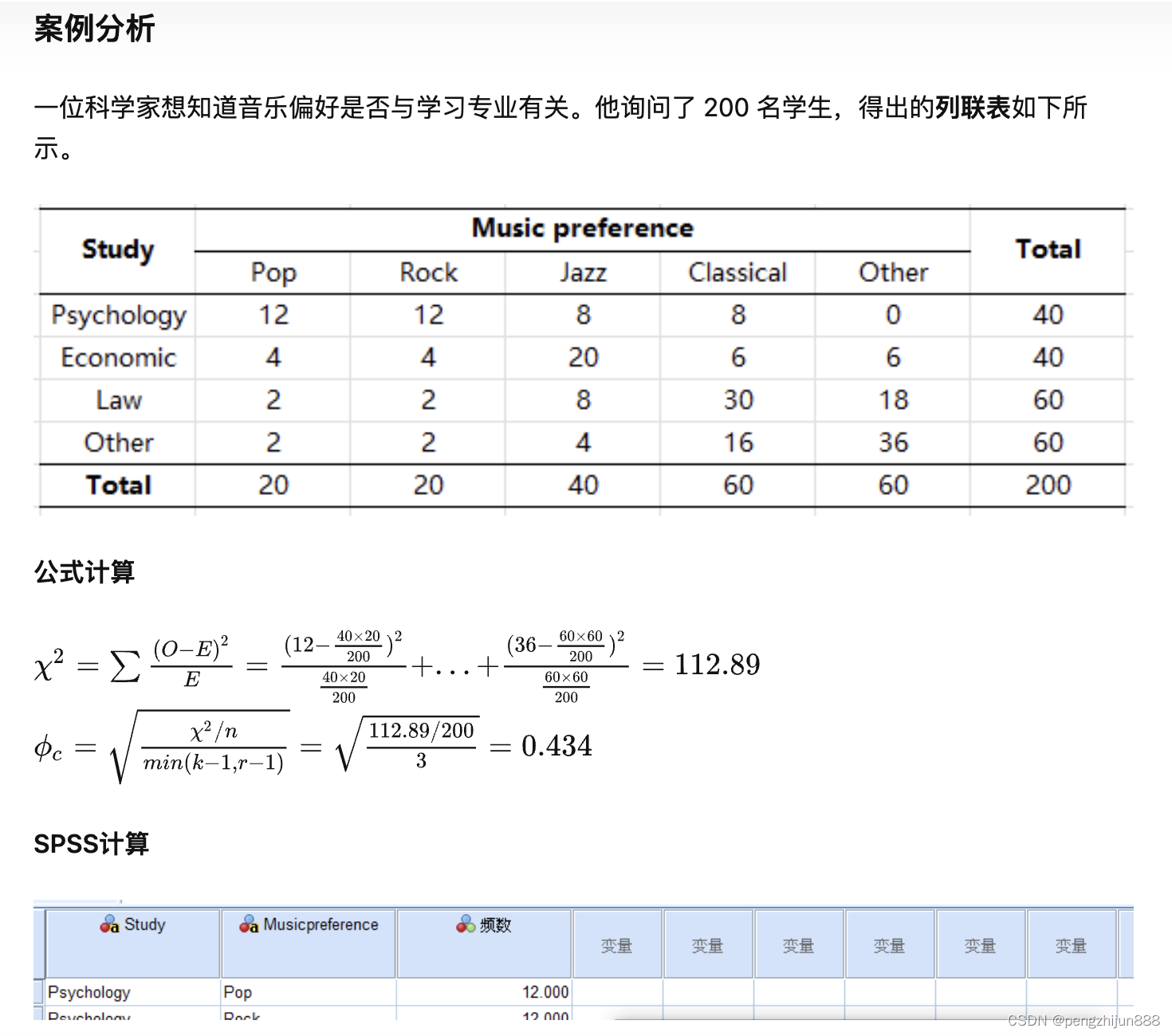
1 离散变量与离散变量的相关系数(克莱姆Cramer’ s V系数)
参考文章:
文章内容预览

Python实现
- 示例数据
import pandas as pd
df = pd.DataFrame([
[12,12,8,8,0],
[4,4,20,6,6],
[2,2,8,30,18],
[2,2,4,16,36],
], index=['Psychology','Econominc','Law','Other'], columns=['Pop','Rock','jazz','classical','other'])
df
| index | Pop | Rock | jazz | classical | other |
|---|---|---|---|---|---|
| Psychology | 12 | 12 | 8 | 8 | 0 |
| Econominc | 4 | 4 | 20 | 6 | 6 |
| Law | 2 | 2 | 8 | 30 | 18 |
| Other | 2 | 2 | 4 | 16 | 36 |
# 数据格式转换,及公式计算
df = df.stack().to_frame().reset_index()
df.columns = ['study','music_preferenct', 'cnts']
def cramer_corr(df:pd.DataFrame, colname1:str, colname2:str, value:str) -> float:
df = df[[colname1,colname2,value]]
df.columns = ['col1','col2','cnts']
df['E-col1'] = df['col1'].map(df.groupby(['col1'])['cnts'].sum())
df['E-col2'] = df['col2'].map(df.groupby(['col2'])['cnts'].sum())
df['E'] = df['E-col1'] * df['E-col2'] / df['cnts'].sum()
x2 = (pow(df['E']-df['cnts'],2) / df['E']).sum()
corr = pow( x2 / df['cnts'].sum() / (min(df['col1'].nunique(),df['col2'].nunique())-1), 0.5)
return corr
cramer_corr(df, 'study', 'music_preferenct','cnts')
结果:0.4337604732431808
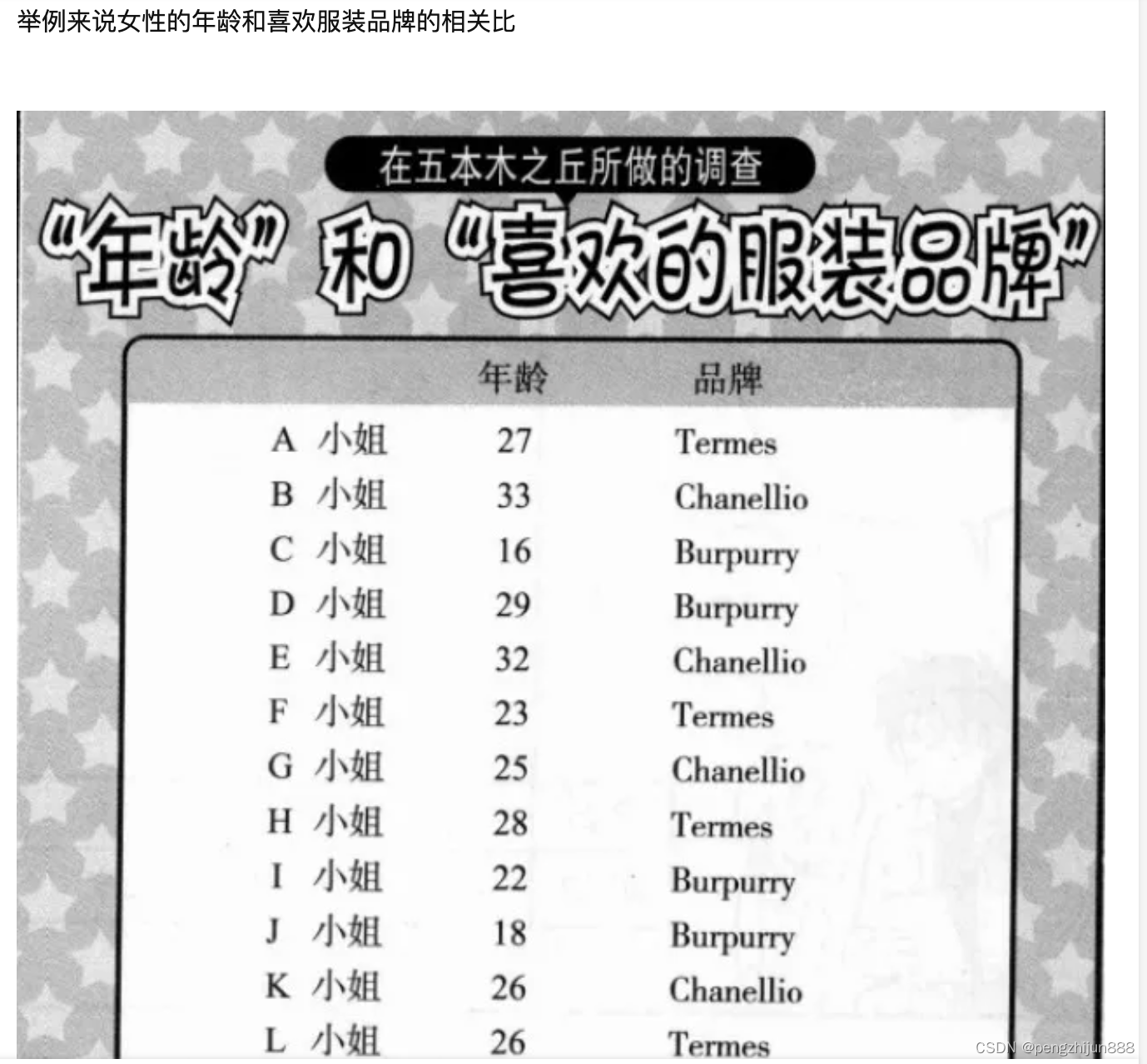
2 离散变量与连续变量的相关系数
参考文章:
文章内容预览

Python实现
import pandas as pd
df = pd.DataFrame([
[27,33,16,29,32,23,25,28,22,18,26,26,15,29,26],
'tcbbctctbbctbcb',
]).T
df.columns = ['age','brand']
df
| index | age | brand |
|---|---|---|
| 0 | 27 | t |
| 1 | 33 | c |
| 2 | 16 | b |
| 3 | 29 | b |
| 4 | 32 | c |
| 5 | 23 | t |
| 6 | 25 | c |
| 7 | 28 | t |
| 8 | 22 | b |
| 9 | 18 | b |
| 10 | 26 | c |
| 11 | 26 | t |
| 12 | 15 | b |
| 13 | 29 | c |
| 14 | 26 | b |
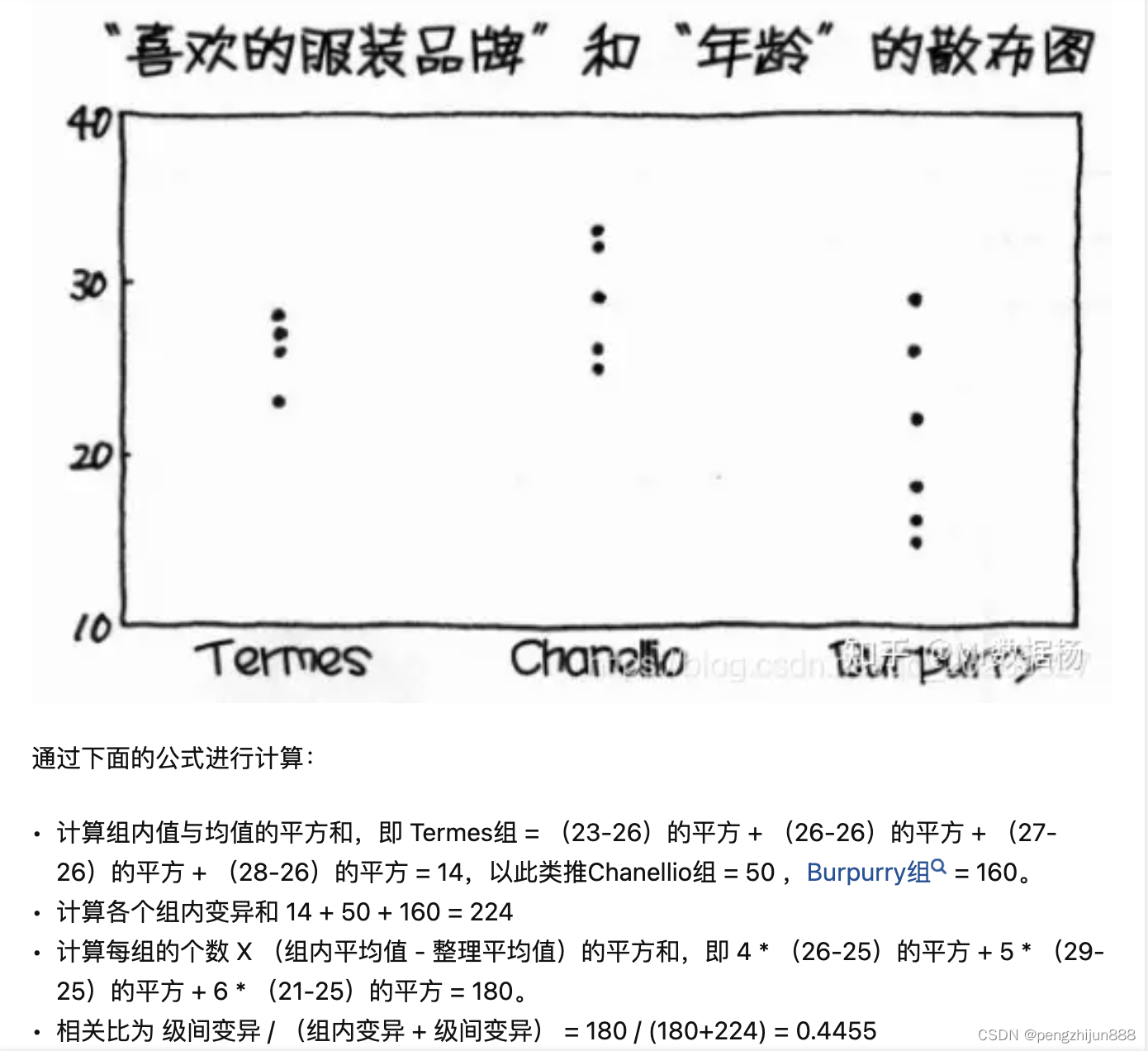
def corr_ratio(df:pd.DataFrame, str_colname, value_colname)->float:
std = df.groupby([str_colname])[value_colname].std()
var = df.groupby([str_colname])[value_colname].var(0)
cnt = df.groupby([str_colname])[value_colname].count()
mean = df.groupby([str_colname])[value_colname].mean()
delta_mean = df.groupby([str_colname])[value_colname].mean() - df[value_colname].mean()
corr = (pow(delta_mean,2)*cnt).sum() / ( (var * cnt).sum() + (pow(delta_mean,2)*cnt).sum() )
return corr
corr_ratio(df, 'brand', 'age')
结果:0.44554455445544555


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









