






 在部署Flink之前,需要完成一系列准备工作,包括设置hostname,更新hosts文件,进行虚拟机克隆,安装SSH,以及安装Java。确保在所有节点上创建用户并赋予相应权限,通过SSH实现无密码登录。接着,安装JDK,将其上传并解压到指定目录,配置环境变量,并使用scp命令将JDK和环境变量配置文件复制到其他节点。
在部署Flink之前,需要完成一系列准备工作,包括设置hostname,更新hosts文件,进行虚拟机克隆,安装SSH,以及安装Java。确保在所有节点上创建用户并赋予相应权限,通过SSH实现无密码登录。接着,安装JDK,将其上传并解压到指定目录,配置环境变量,并使用scp命令将JDK和环境变量配置文件复制到其他节点。
部署Flink前,先要做hostname,hosts,虚拟机克隆,ssh安装,Java安装等
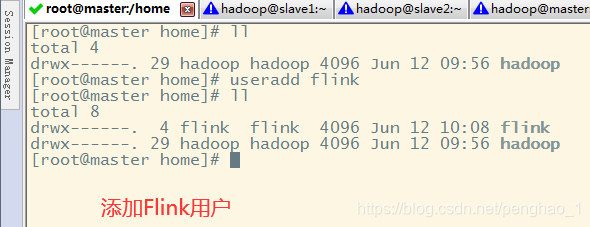
然后cat /etc/passwd 可以看到你新建的用户在面显示
![]()

保存退出
也可以直接给cat /etc/passwd添加用户的方法进行添加用户名用户组
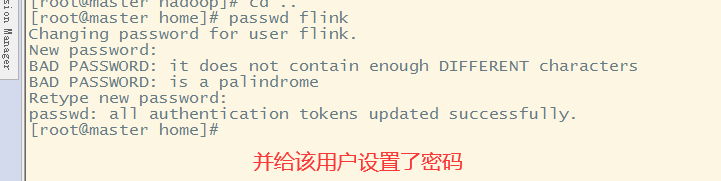
其他节点也是一样,添加用户,赋予密码,赋予权限
===============================================================
接着就是设置免密,先看看有没有对应的文件夹

其他的节点也是一样创建
然后就是创建免密了
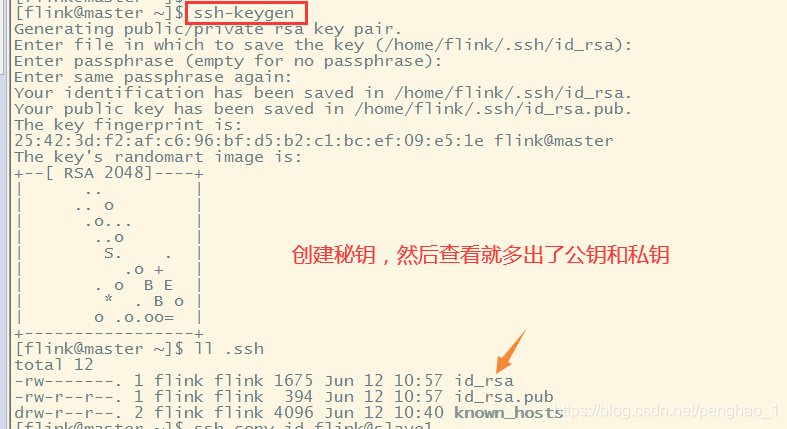
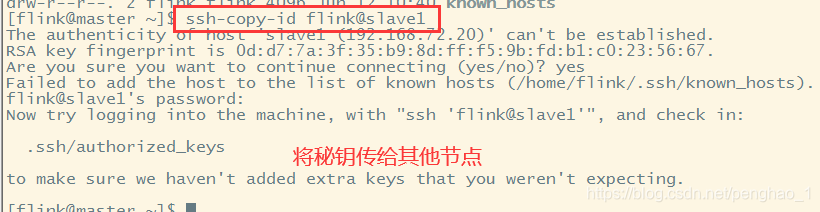
同时也要传给自己的哦
同理,在其他节点也要创建秘钥,然后传给其他节点,及自己
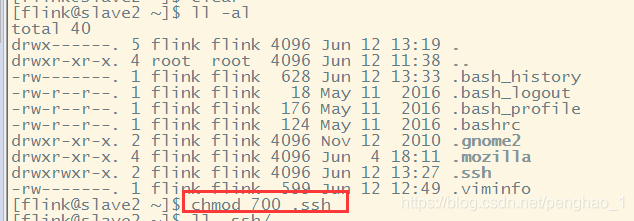
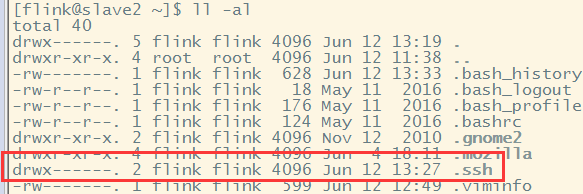
还要最重要一步,给每个.ssh文件设置权限,否则无法进行免密登录
chmod 700 .ssh #这个权限很重要
然后进行免密登录进行验证
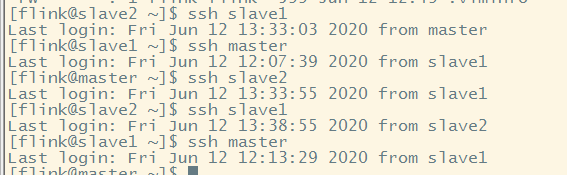
到此,免密成功
接下来就是可以安装jdk
1、上传jdk、并解压到指定目录下

2、进入文件进行配置java的环境变量
vi .bash_profile

3、然后用scp -r将jdk的解压包传给其他节点。同时.bash_profile记得要刷新一下让其生效
scp -r local flink@slave1:~/
scp -r local flink@slave2:~/

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









