








1. Flink的部署模式
1.1 本地模式
1.1.1 介绍
1)包含:
linux环境
windows环境或mac os环境
2)适用场景:
开发阶段,通过本地模式验证程序的正确性
1.1.2 效果演示
1.1.2.1 配置flink_home
[robin@node01 module]$ sudo vi /etc/profile
export FLINK_HOME=/opt/module/flink
export PATH=$PATH:$FLINK_HOME/bin
[robin@node01 module]$ source /etc/profile
1.1.2.2 启动local版的flink集群
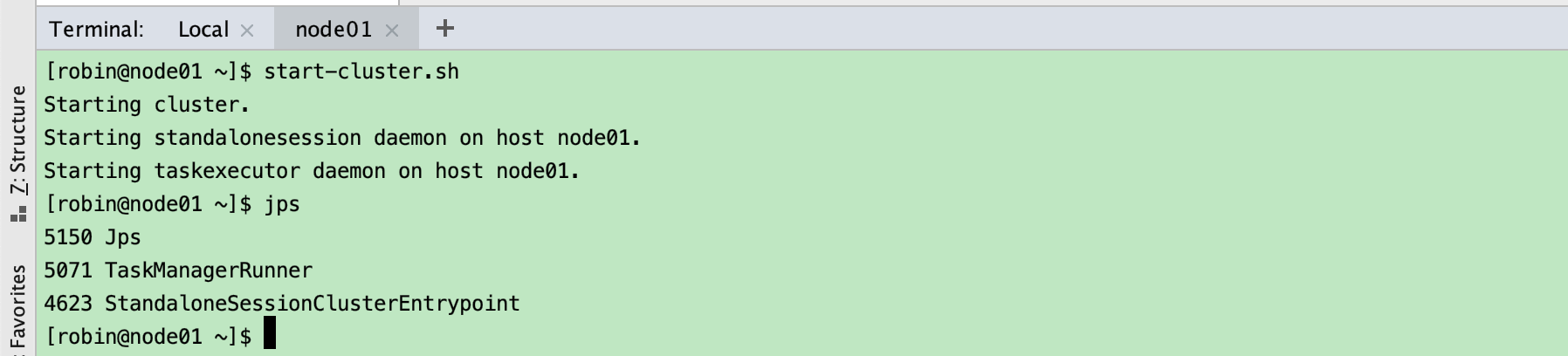
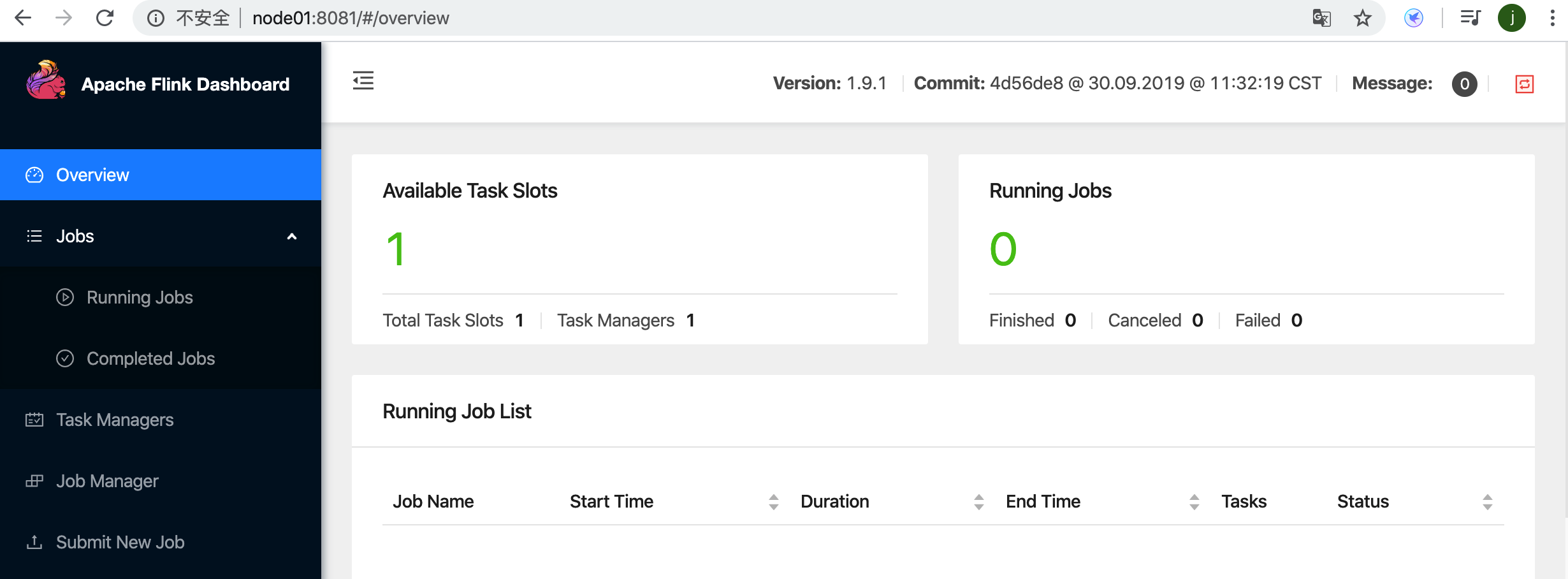
1.1.2.3 查看任务管理器页面
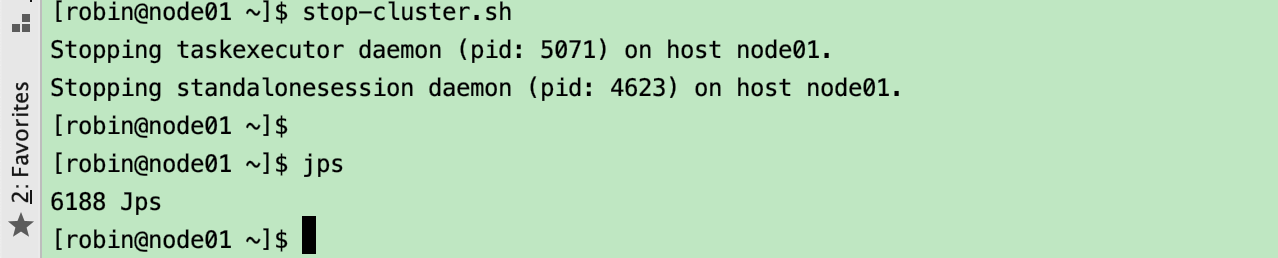
1.1.2.4 停止本地的集群
1.2 standalone模式
1.2.1 非HA模式 (没有配置JobManager HA的情形)
1.2.1.1 配置方式
步骤:
1) 在node01上进行如下的配置
1. 编辑conf目录下的配置文件masters
2. 编辑conf目录下的配置文件slaves
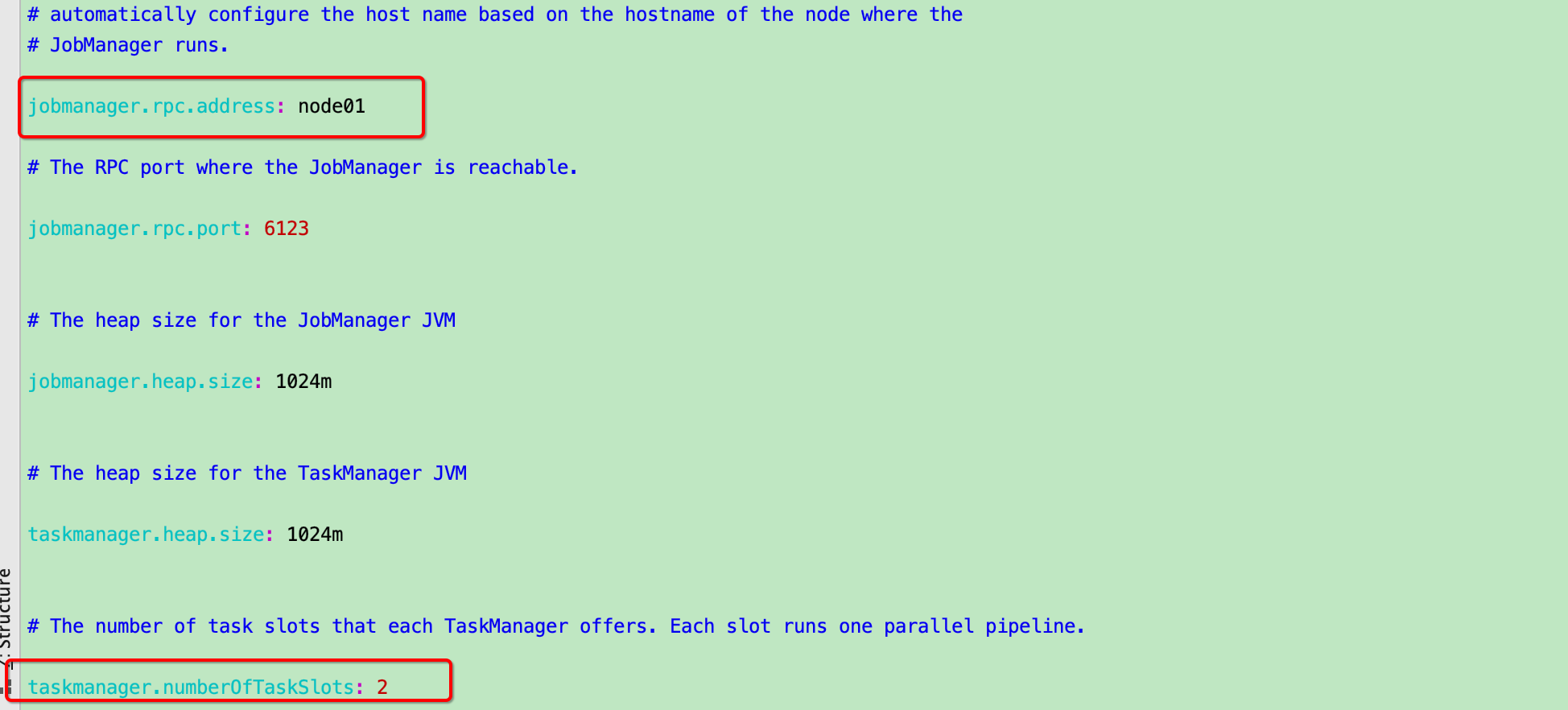
3. 编辑conf目录下的配置文件flink-conf.yaml
2) 将node01上配置好的flink分发到别的节点上(node02,node03)
3) 通过start-cluster.sh脚本启动flink分布式集群
4) 通过任务管理器界面进行确认
第一步: 在node01上进行如下配置
conf/masters

conf/slaves

conf/flink-conf.yaml
[robin@node01 ~]$ cat /opt/module/flink/conf/flink-conf.yaml
第二步:将node01上配置好的flink分发到别的节点上
同步脚本
[robin@node01 ~]$ cat bin/xsync
#! /bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
NODE_IPS=("node02" "node03")
for node_ip in ${NODE_IPS[@]}
do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- ${node_ip} ----------------
rsync -rvl $pdir/$fname $user@${node_ip}:$pdir
done
[robin@node01 module]$ xsync flink
第三步:通过start-cluster.sh脚本启动flink分布式集群
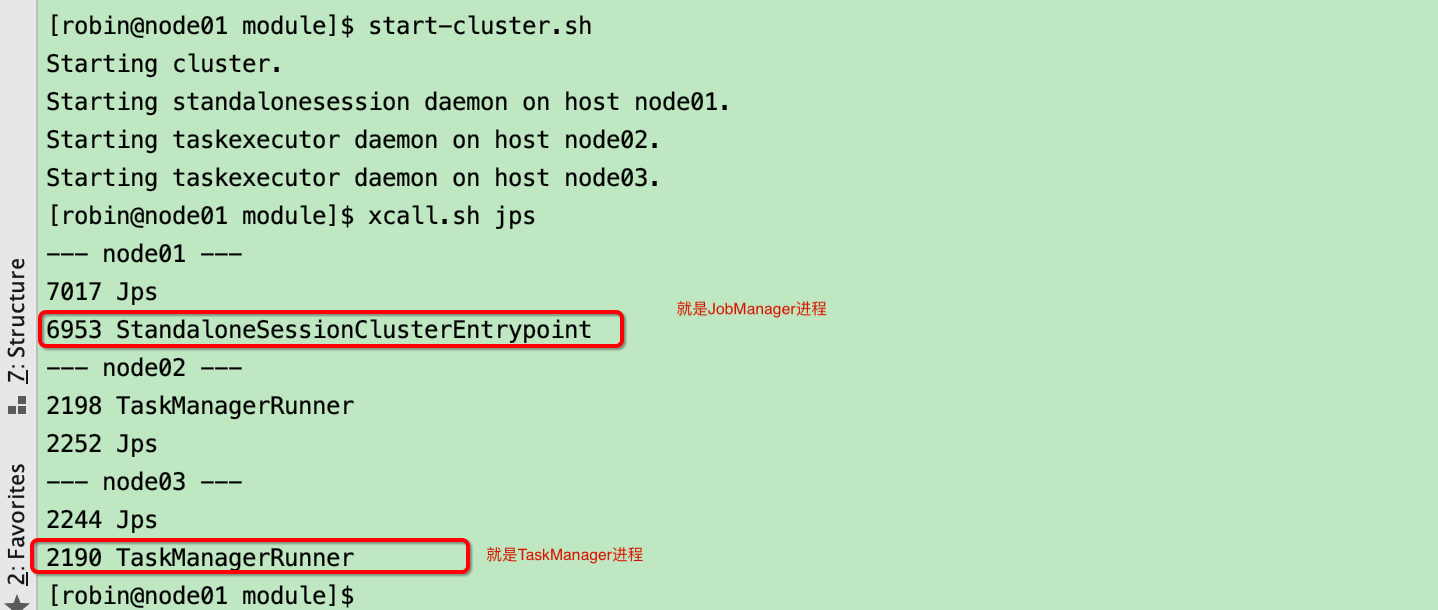
第四步:通过任务管理器界面进行确认
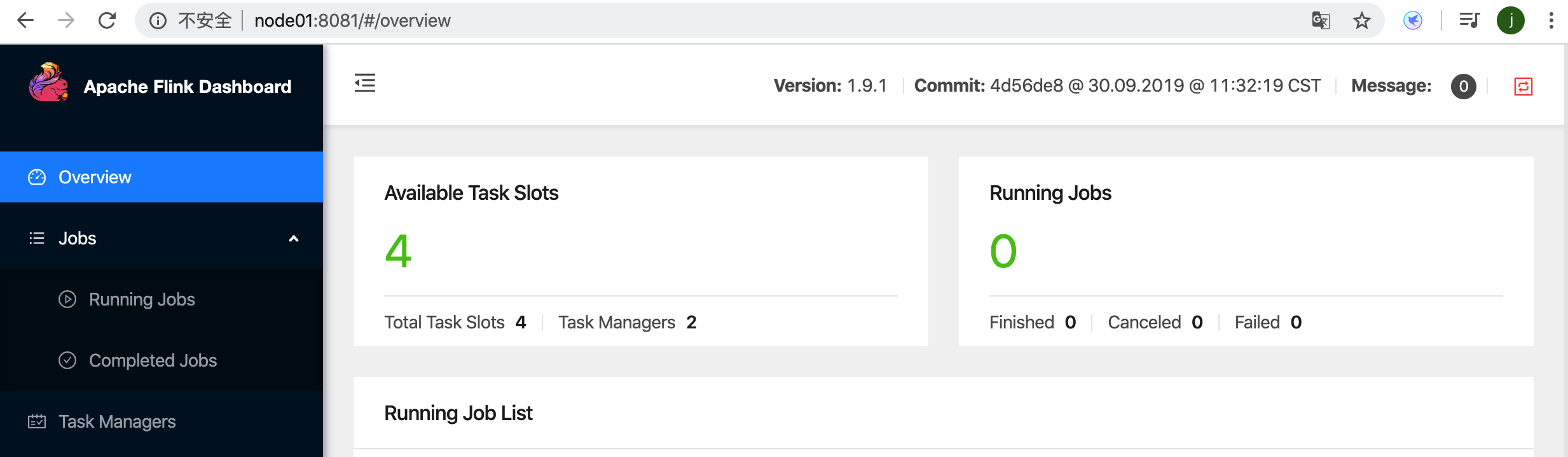
1.2.1.2 测试standalone 非HA模式的可用性
测试可用性步骤:
1.将项目打包成jar包
2.上传到linux
3.提交,执行
4.验证结果的正确性
实施
第一步:将项目打包成jar包

第二步:上传到linux
[robin@node01 ~]$ mkdir flink-learn

第三步:提交,执行
提交方式有:
1.命令行方式
2.通过任务管理器的方式
方式1: 命令行方式
[robin@node01 flink-learn]$ vim standalone-deploy.sh
flink run -c com.jd.bounded.hdfs3.BoundedFlowTest4 \
./flink-learning-1.0-SNAPSHOT.jar \
--input hdfs://node01:9000/flink/input \
--output hdfs://node01:9000/flink/output \
注意点: 运行时报错
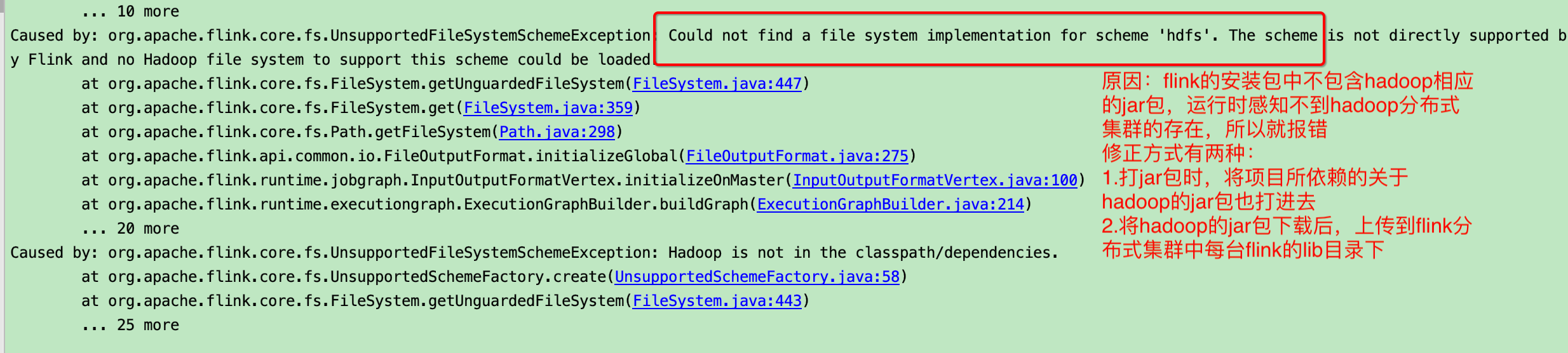
解决方法
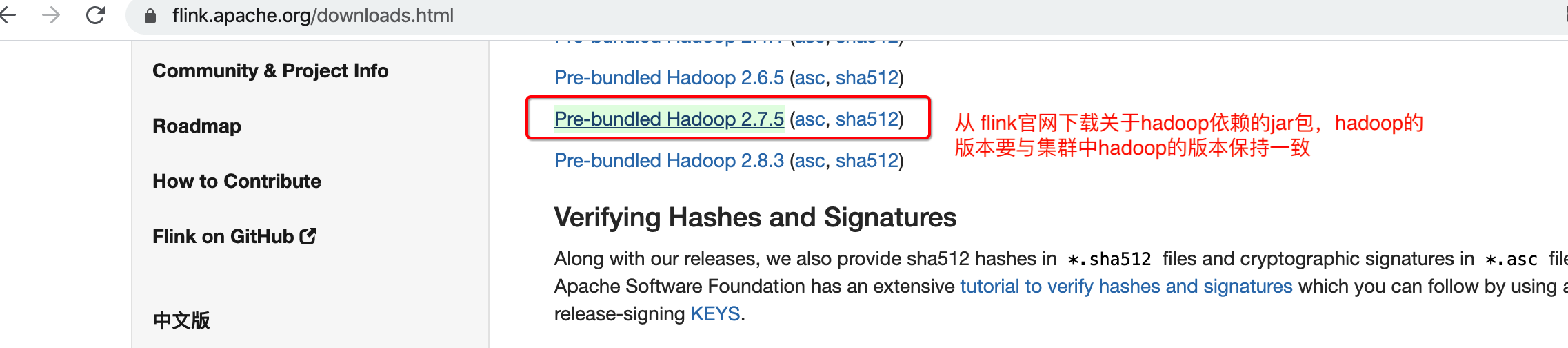
将下载的jar包上传到fllink/lib目录下
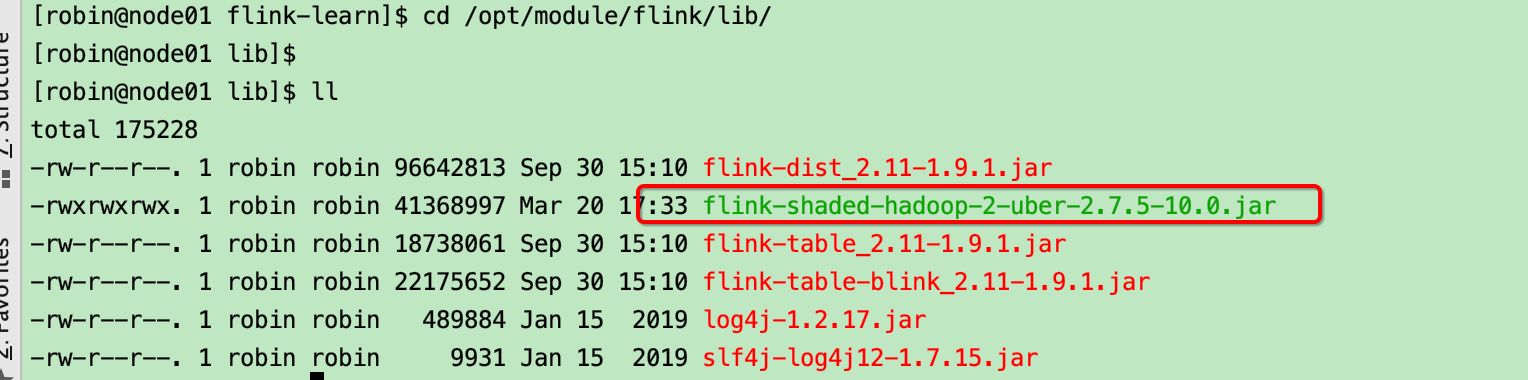
同步到其它机器上
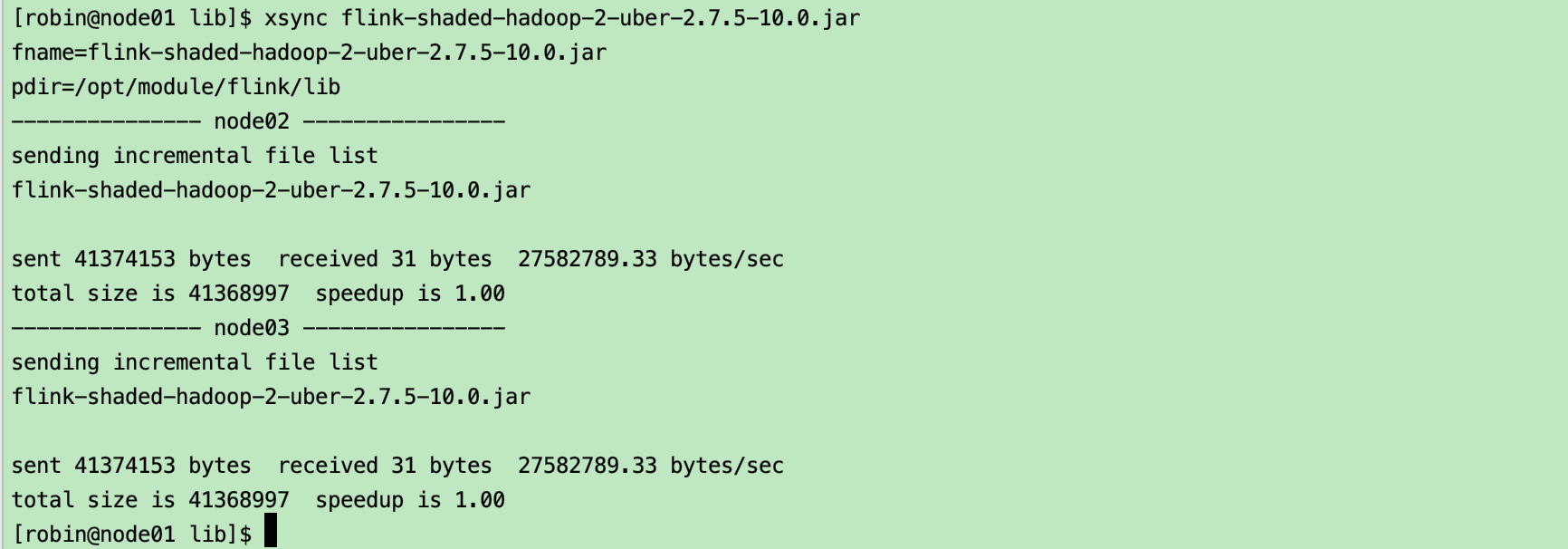
注意: 先停止flink分布式集群然后进行jar包同步,然后再重启flink集群
运行脚本的效果

修正之后运行的效果
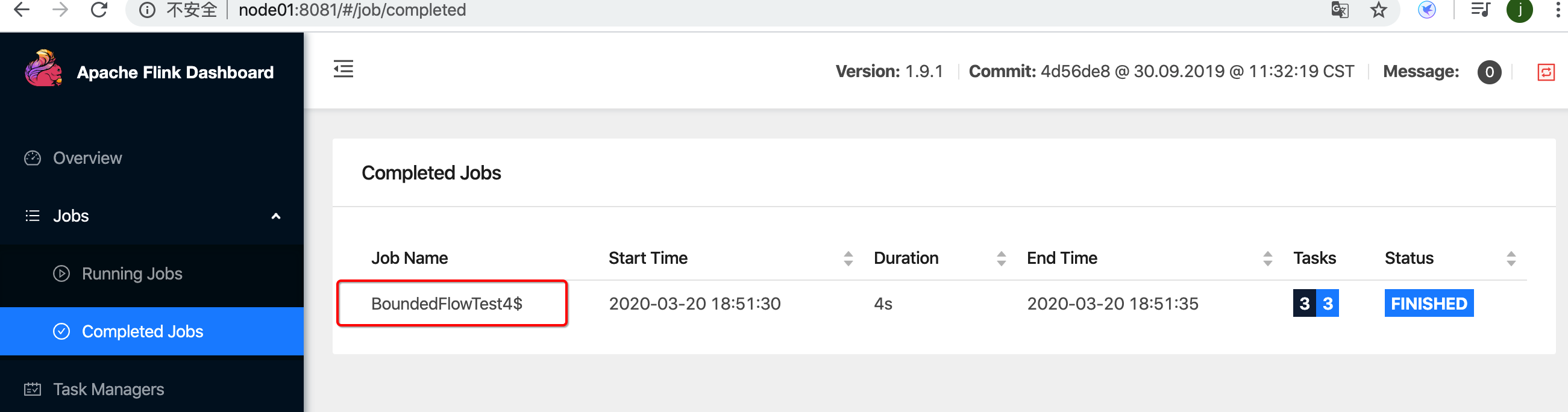

方式2: 通过任务管理器的方式
上传
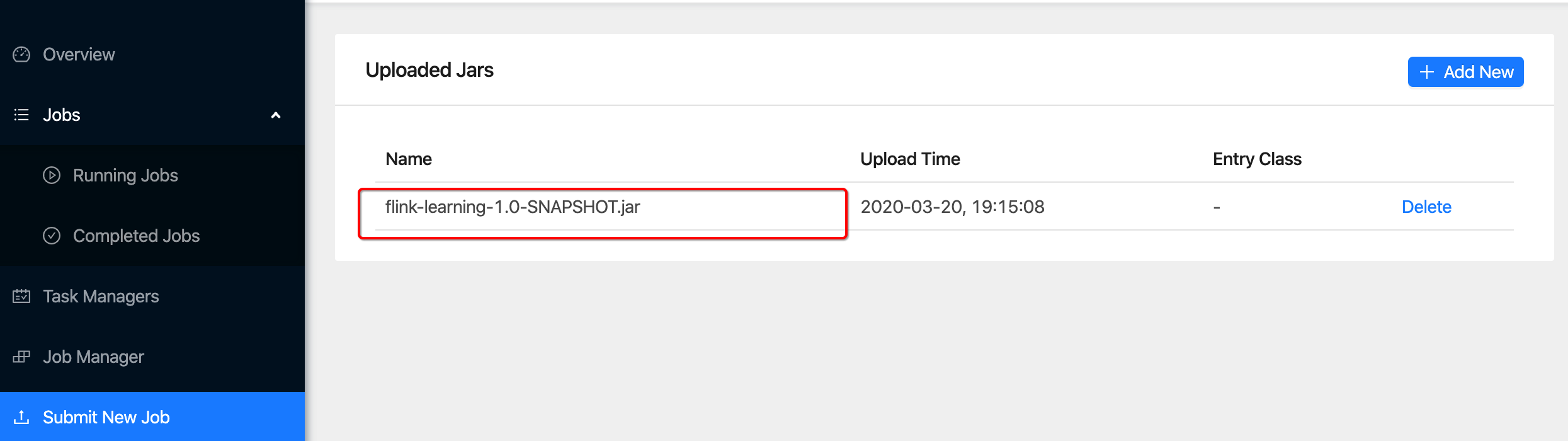
目的地查看
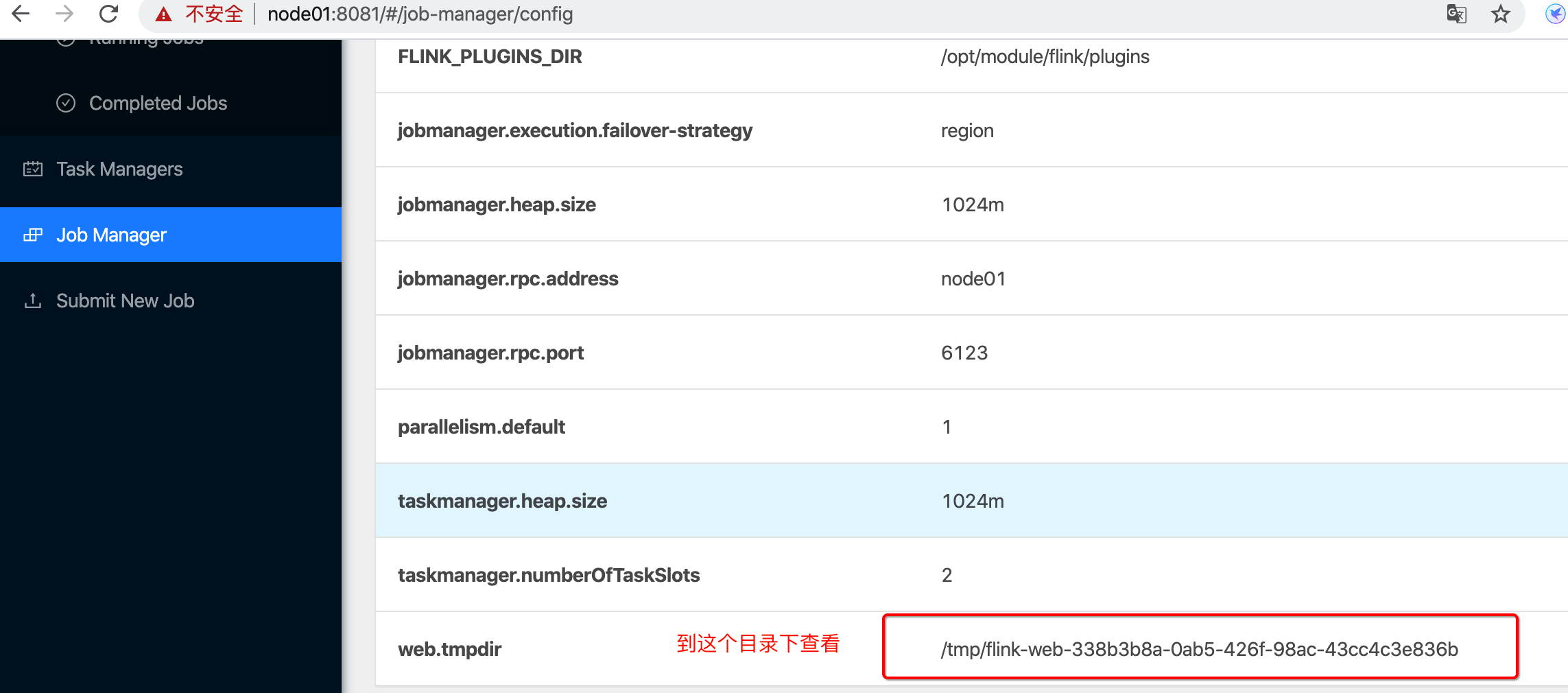

1.2.2 HA模式 (配置JobManager HA的情形)
1.2.2.1 介绍
步骤:
1.集群的规划:
node01 --> JobManager (master角色)
node02 --> JobManager (slave角色), TaskManager
node03 --> TaskManager
2.实施思路:
a.修改配置文件flink-conf.yaml,masters,slaves
b.将node01上的flink同步到别的节点上(node02,node03)
c.启动flink分布式集群
d.验证flink standalone ha模式是否生效
1.2.2.2 实施
第1步: 修改配置文件flink-conf.yaml,masters,slaves
[robin@node01 conf]$ vim masters
node01:8081
node02:8081
[robin@node01 conf]$ vim flink-conf.yaml
jobmanager.rpc.address: node01
jobmanager.rpc.port: 6123
high-availability: zookeeper
high-availability.storageDir: hdfs://node01:9000/flink/ha/
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_one
high-availability.zookeeper.client.acl: open
slaves跟之前一样不用修改
第2步: 将node01上的flink同步到别的节点上
第3步: 启动flink分布式集群
[robin@node01 module]$ start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host node01.
Starting standalonesession daemon on host node02.
Starting taskexecutor daemon on host node02.
Starting taskexecutor daemon on host node03.
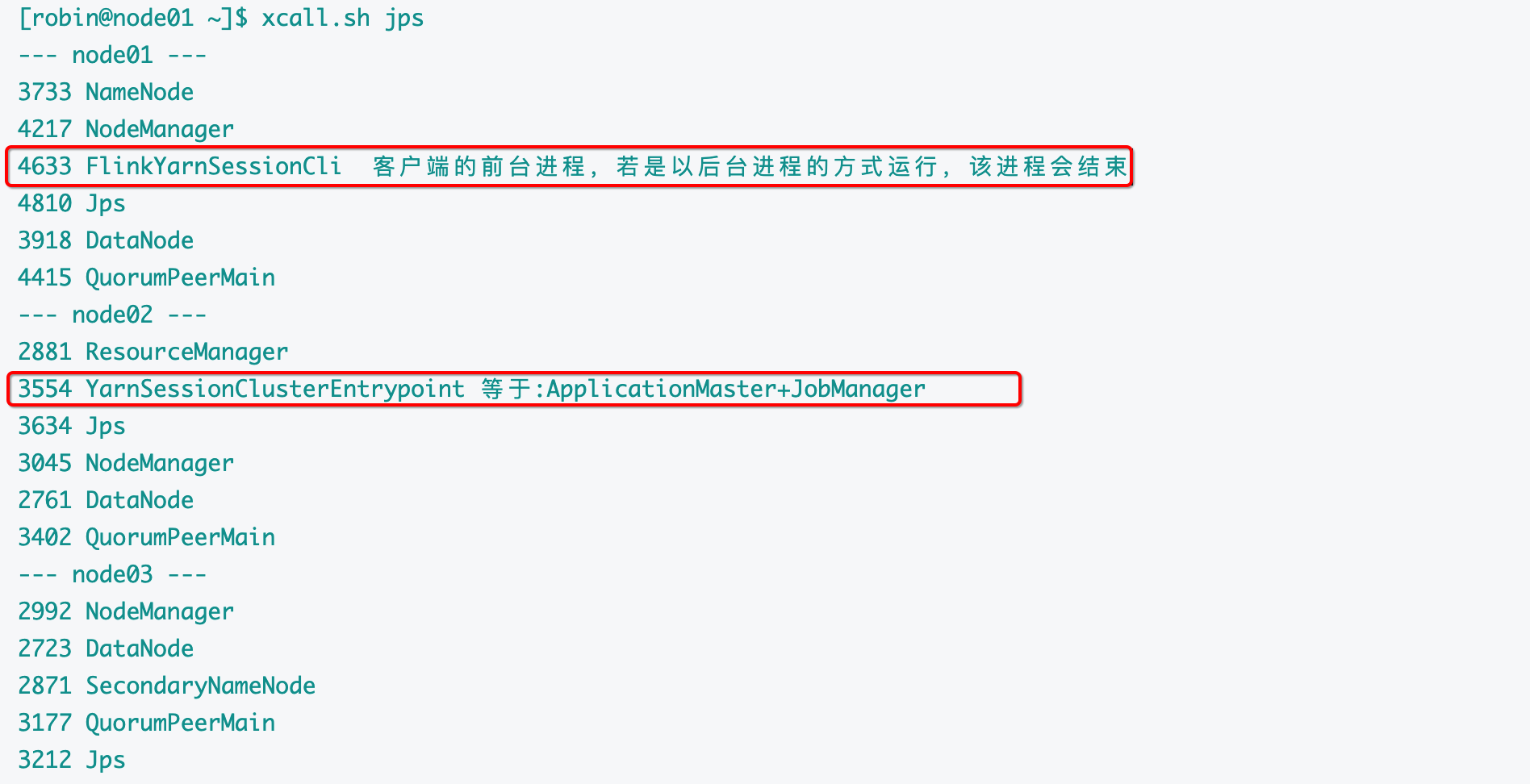
[robin@node01 module]$ xcall.sh jps
--- node01 ---
1825 DataNode
1639 NameNode
2729 QuorumPeerMain
3579 Jps
3500 StandaloneSessionClusterEntrypoint
2127 NodeManager
--- node02 ---
3651 Jps
1670 ResourceManager
1463 DataNode
3546 TaskManagerRunner
2476 QuorumPeerMain
1821 NodeManager
3006 StandaloneSessionClusterEntrypoint
--- node03 ---
1701 NodeManager
2773 TaskManagerRunner
2837 Jps
1430 DataNode
1580 SecondaryNameNode
2222 QuorumPeerMain
第4步: 验证flink standalone ha模式是否生效
1.zookeeper相应的zNode查看
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0] ls /
[flink, cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, services, latest_producer_id_block, config]
[zk: localhost:2181(CONNECTED) 1] ls /flink/cluster_one
[jobgraphs, leader, leaderlatch]
[zk: localhost:2181(CONNECTED) 2]
2.验证JobManager进程的HA
2.1方式1: 查看日志文件
2.1.1查看node01上的Leader角色的JobManager进程
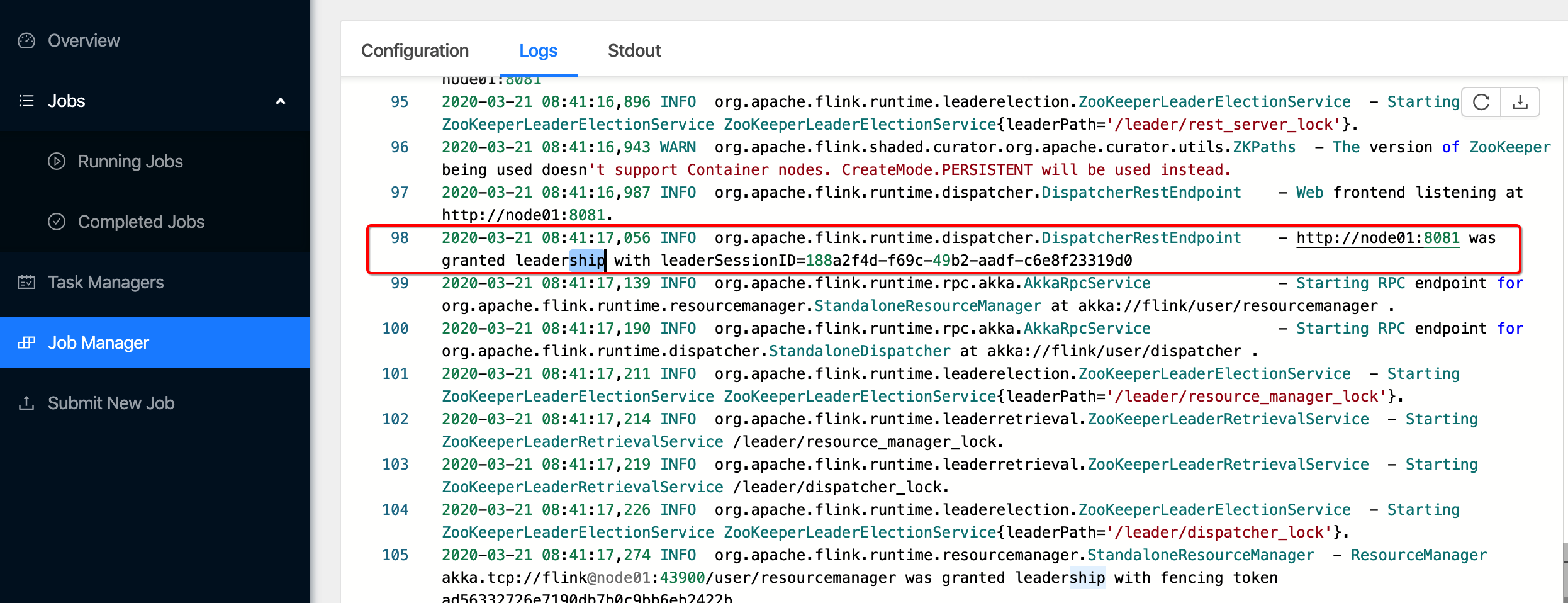
2.1.2查看node02上的standBy状态的JobManager进程
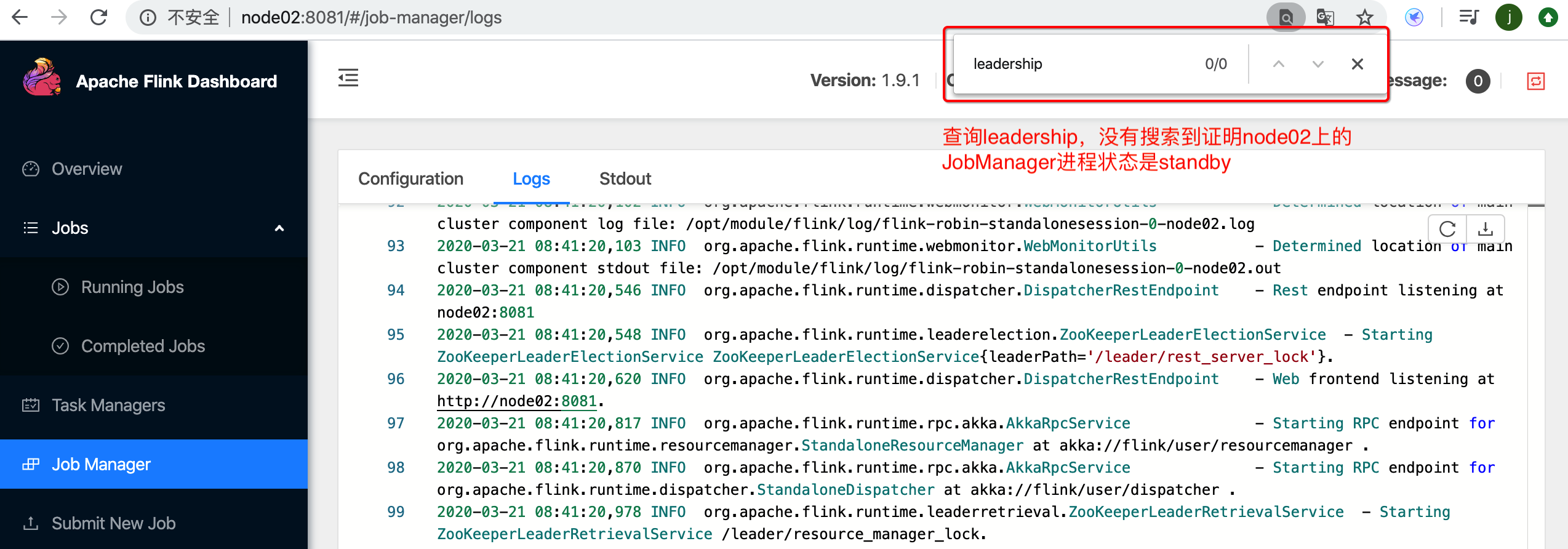
2.2方式2: 进程状态切换
2.2.1 介绍
步骤:
1. 先将node01上的JobManager手动kill掉
2. 去观察node02是否自动被选举为Leader,状态为Active
3. 重启node01上的JobManager,观察其状态是否为StandBy
2.2.2 实施
1.先将node01上的JobManager手动kill掉
[robin@node01 module]$ jps
1825 DataNode
3826 Jps
1639 NameNode
2729 QuorumPeerMain
3674 ZooKeeperMain
3500 StandaloneSessionClusterEntrypoint
2127 NodeManager
[robin@node01 module]$ jobmanager.sh stop
Stopping standalonesession daemon (pid: 3500) on host node01.
[robin@node01 module]$ jps
1825 DataNode
1639 NameNode
2729 QuorumPeerMain
3674 ZooKeeperMain
2127 NodeManager
4239 Jps
- 去观察node02是否自动被选举为Leader,状态为Active
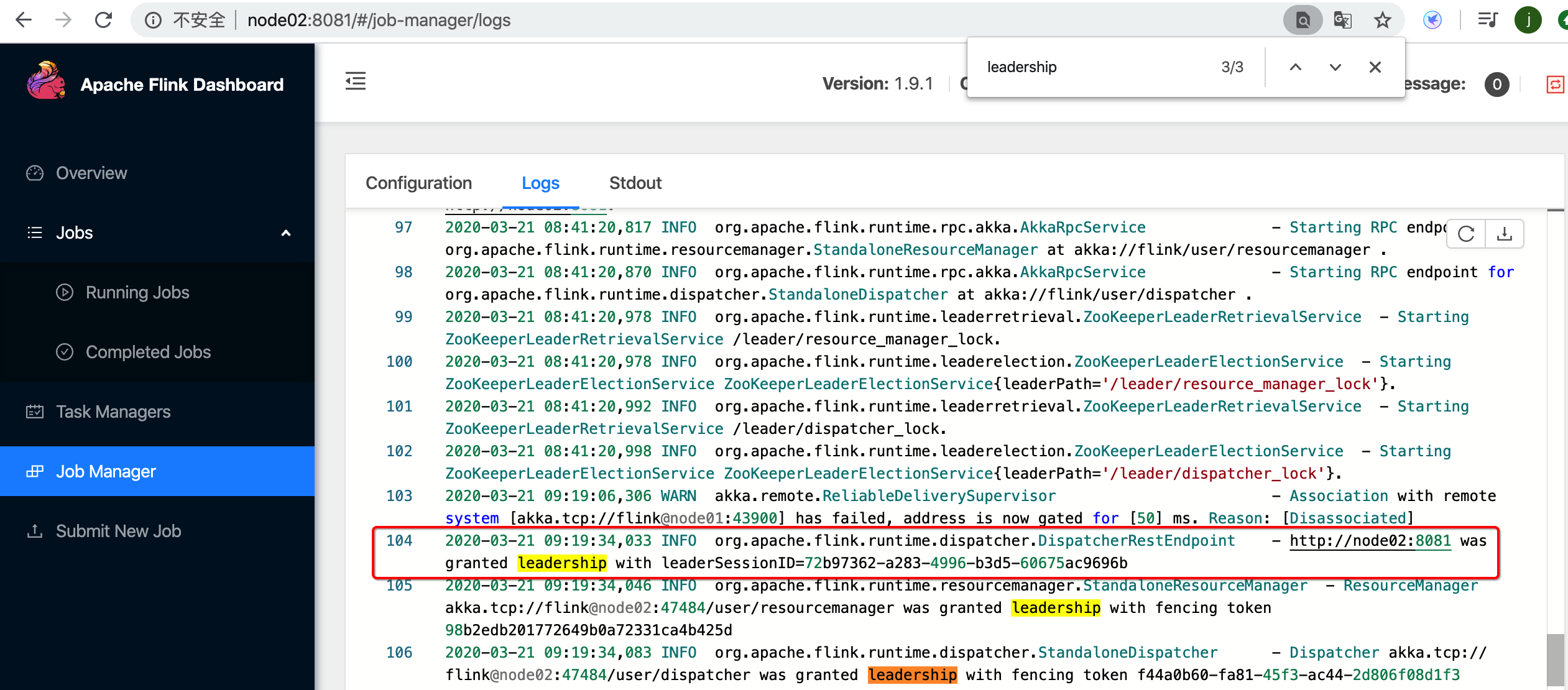
- 重启node01上的JobManager,观察其状态是否为StandBy
[robin@node01 module]$ jps
1825 DataNode
1639 NameNode
2729 QuorumPeerMain
3674 ZooKeeperMain
4254 Jps
2127 NodeManager
[robin@node01 module]$ jobmanager.sh start
Starting standalonesession daemon on host node01.
[robin@node01 module]$ jps
1825 DataNode
4739 Jps
1639 NameNode
4680 StandaloneSessionClusterEntrypoint
2729 QuorumPeerMain
3674 ZooKeeperMain
2127 NodeManager
[robin@node01 module]$
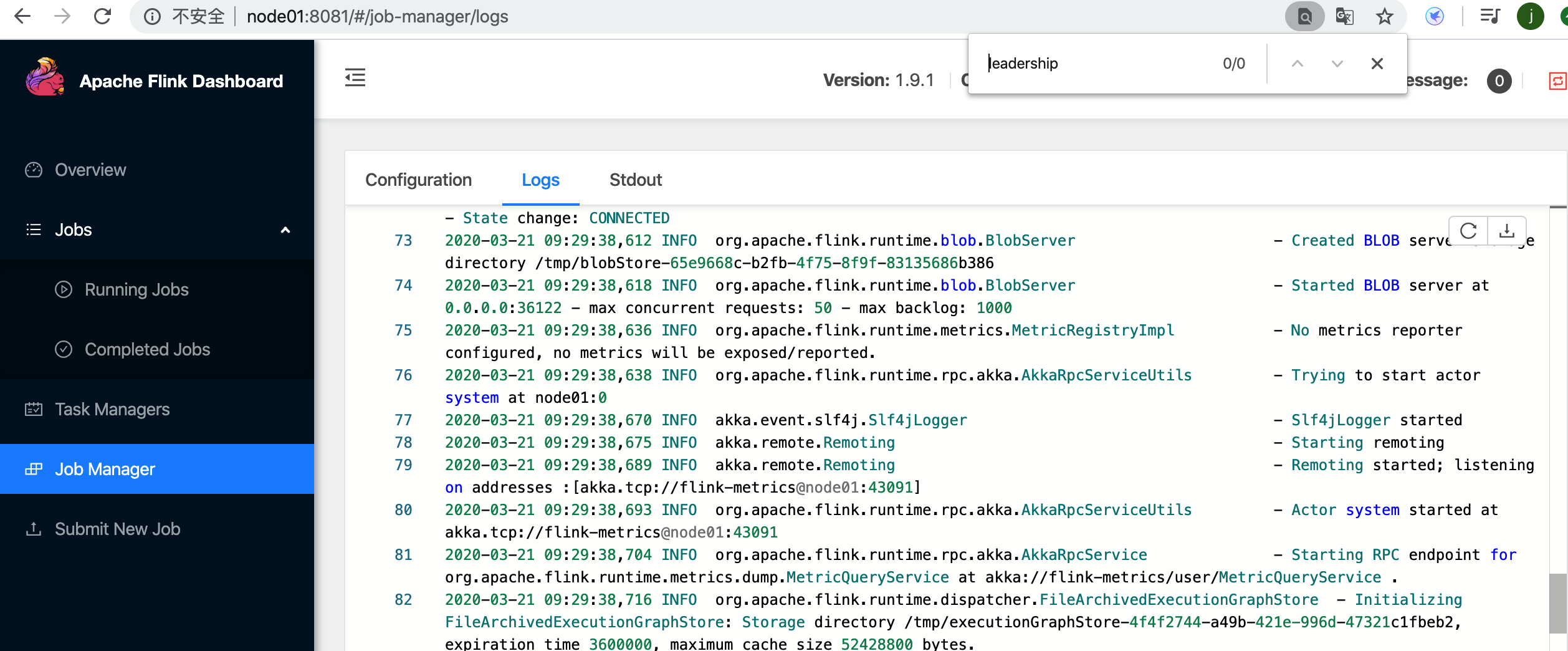
搜索不到leadership相关字样
1.3 Yarn模式
1.3.1 介绍
细分成两种部署方式:
方式1: 在Yarn上启动长久运行着的(long running) flink集群
方式2: 在Yarn上运行单个flink job
共性:
CliFrontend是所有job的入口类,通过解析传递的参数(jar包,mainClass等)读取flink的环境,配置信息等,封装成PackageProgram,最终通过clusterClient提交给Flink集群
1.3.2 分别演示
1.3.2.1 yarn session
特点
在Yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在Yarn集群中,除非手动停止。
YarnSessionClusterEntrypoint即为Flink在Yarn上的ApplicationMaster,同时也是JobManager,AM启动类是YarnJobClusterEntrypoint,也就是:
YarnSessionClusterEntrypoint = ApplicationMaster + JobManager
YarnJobClusterEntrypoint = ApplicationMaster进程的启动类
YarnTaskExecutorRunner 负责接收subTask,并运行就是TaskManager
实操
第1步:启动flink集群,让其常驻在yarn中
前提:先启动hadoop分布式集群
启动yarn-session,也就是创建一个yarn模式的flink集群
yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
-n(--container):TaskManager的数量
-s(--slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余
-jm: JobManager的内存(单位MB)
-tm: 每个taskmanager的内存(单位MB)
-nm: yarn的appName(现在yarn的ui上名字)
-d: 后台执行
效果:
[robin@node01 hadoop-2.7.2]$ yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test
2020-03-21 13:30:28,082 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, node01
2020-03-21 13:30:28,084 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123
2020-03-21 13:30:28,084 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
2020-03-21 13:30:28,084 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m
2020-03-21 13:30:28,084 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 2
2020-03-21 13:30:28,084 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1
2020-03-21 13:30:28,085 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability, zookeeper
2020-03-21 13:30:28,085 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.storageDir, hdfs://node01:9000/flink/ha/
2020-03-21 13:30:28,085 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.zookeeper.quorum, node01:2181,node02:2181,node03:2181
2020-03-21 13:30:28,085 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.zookeeper.path.root, /flink
2020-03-21 13:30:28,085 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.cluster-id, /cluster_one
2020-03-21 13:30:28,086 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.zookeeper.client.acl, open
2020-03-21 13:30:28,086 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.execution.failover-strategy, region
2020-03-21 13:30:28,574 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2020-03-21 13:30:28,707 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to robin (auth:SIMPLE)
2020-03-21 13:30:28,770 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node02/192.168.56.103:8032
2020-03-21 13:30:28,881 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument n is deprecated in will be ignored.
2020-03-21 13:30:29,017 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-03-21 13:30:29,063 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=2, slotsPerTaskManager=2}
2020-03-21 13:30:29,516 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/module/flink/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
2020-03-21 13:30:32,867 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1584768585865_0001
2020-03-21 13:30:33,027 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1584768585865_0001
2020-03-21 13:30:33,027 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2020-03-21 13:30:33,031 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2020-03-21 13:30:39,926 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
2020-03-21 13:30:39,961 INFO org.apache.flink.runtime.blob.FileSystemBlobStore - Creating highly available BLOB storage directory at hdfs://node01:9000/flink/ha///cluster_one/blob
2020-03-21 13:30:40,025 INFO org.apache.flink.shaded.curator.org.apache.curator.framework.imps.CuratorFrameworkImpl - Starting
2020-03-21 13:30:40,031 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:zookeeper.version=3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
2020-03-21 13:30:40,031 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:host.name=node01
2020-03-21 13:30:40,031 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.version=1.8.0_144
2020-03-21 13:30:40,031 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.vendor=Oracle Corporation
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.home=/opt/module/jdk1.8.0_144/jre
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.class.path=/opt/module/flink/lib/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar:/opt/module/flink/lib/flink-table_2.11-1.9.1.jar:/opt/module/flink/lib/flink-table-blink_2.11-1.9.1.jar:/opt/module/flink/lib/log4j-1.2.17.jar:/opt/module/flink/lib/slf4j-log4j12-1.7.15.jar:/opt/module/flink/lib/flink-dist_2.11-1.9.1.jar::/opt/module/hadoop-2.7.2/etc/hadoop:
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.io.tmpdir=/tmp
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:java.compiler=<NA>
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:os.name=Linux
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:os.arch=amd64
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:os.version=2.6.32-642.el6.x86_64
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:user.name=robin
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:user.home=/home/robin
2020-03-21 13:30:40,032 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Client environment:user.dir=/opt/module/hadoop-2.7.2
2020-03-21 13:30:40,033 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ZooKeeper - Initiating client connection, connectString=node01:2181,node02:2181,node03:2181 sessionTimeout=60000 watcher=org.apache.flink.shaded.curator.org.apache.curator.ConnectionState@f9b7332
2020-03-21 13:30:40,047 WARN org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - SASL configuration failed: javax.security.auth.login.LoginException: No JAAS configuration section named 'Client' was found in specified JAAS configuration file: '/tmp/jaas-9089771528471195129.conf'. Will continue connection to Zookeeper server without SASL authentication, if Zookeeper server allows it.
2020-03-21 13:30:40,049 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Opening socket connection to server node03/192.168.56.104:2181
2020-03-21 13:30:40,050 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Socket connection established to node03/192.168.56.104:2181, initiating session
2020-03-21 13:30:40,057 ERROR org.apache.flink.shaded.curator.org.apache.curator.ConnectionState - Authentication failed
2020-03-21 13:30:40,064 INFO org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Session establishment complete on server node03/192.168.56.104:2181, sessionid = 0x370fb91feeb0001, negotiated timeout = 40000
2020-03-21 13:30:40,067 INFO org.apache.flink.shaded.curator.org.apache.curator.framework.state.ConnectionStateManager - State change: CONNECTED
2020-03-21 13:30:40,413 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on node02:60724 with leader id 30e10b8a-f6c0-4500-99fe-5bc0b54c9080.
JobManager Web Interface: http://node02:43947
查看进程
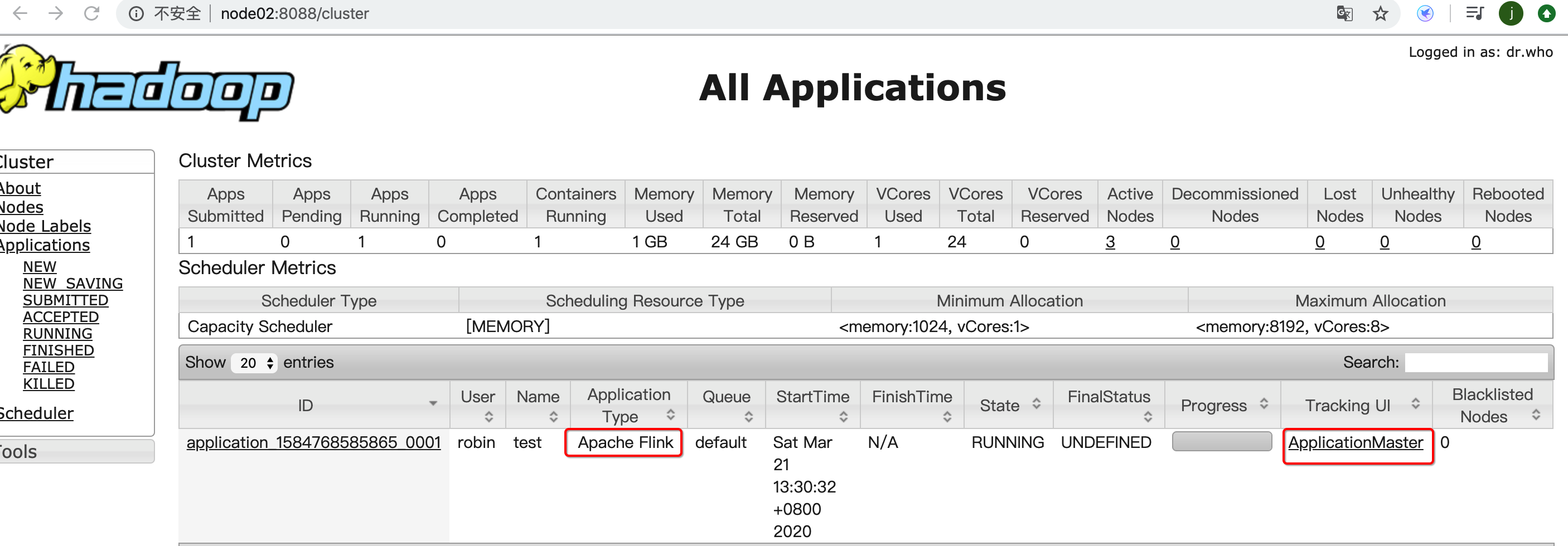
第2步:将flink job部署到yarn中,运行并确认结果
部署并启动运行
flink run -c com.jd.bounded.hdfs_hdfs.BoundedFlowTest \
-d ./flink-learning-1.0-SNAPSHOT.jar \
--input hdfs://node01:9000/flink/input \
--output hdfs://node01:9000/flink/output3/result.txt
启动之后,flink job共享yarn session开辟的空间运行在flink分布式集群中
[robin@node01 flink-learn]$ ./yarn-cluster-deploy.sh
2020-03-21 15:22:11,787 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-robin.
2020-03-21 15:22:11,787 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-robin.
2020-03-21 15:22:12,166 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 4
2020-03-21 15:22:12,166 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 4
YARN properties set default parallelism to 4
2020-03-21 15:22:12,205 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node02/192.168.56.103:8032
2020-03-21 15:22:12,342 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-21 15:22:12,342 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-21 15:22:12,345 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-03-21 15:22:12,412 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'node02' and port '45906' from supplied application id 'application_1584775089663_0001'
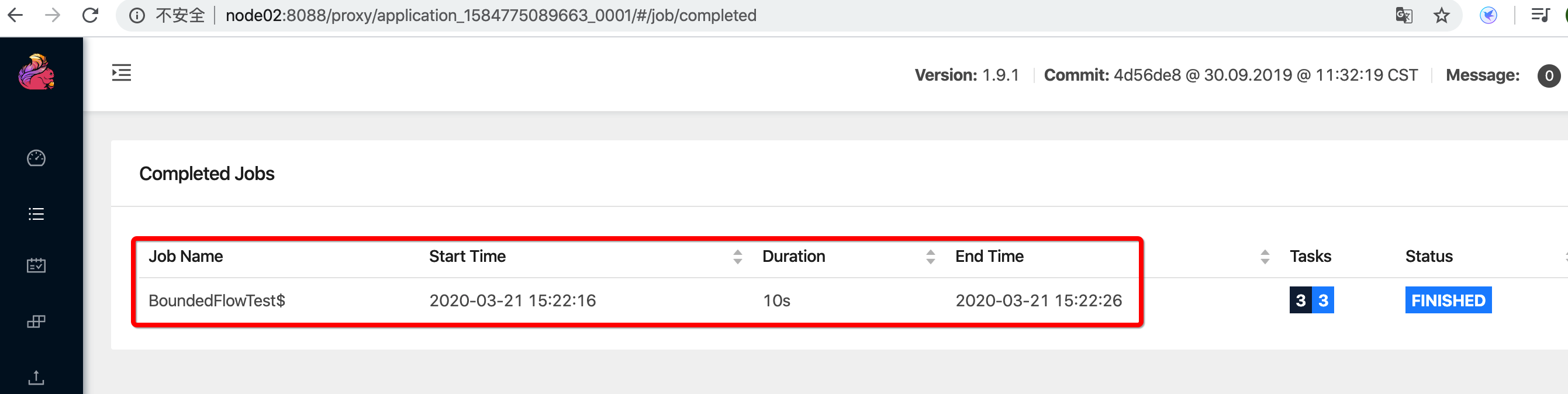
Starting execution of program
Job has been submitted with JobID 2ac1cf69095c62373bea23f9ce6561c7
运行的结果
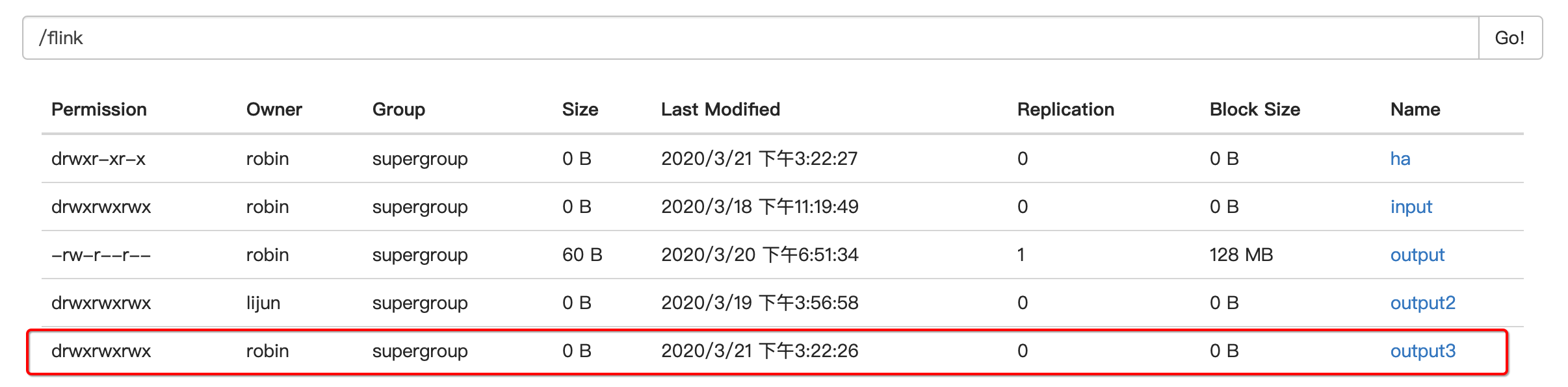
1.3.2.2 独立的 flink job
- 特点
每次提交都会创建一个新flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
YarnJobClusterEntrypoint = ApplicationMaster进程的启动类
YarnTaskExecutorRunner 负责接收subTask,并运行就是TaskManager
- 说明
在YARN 上运行单个flink job
启动命令:
flink run -m yarn-cluster -yn 2 -c com.jd.bounded.hdfs_hdfs.BoundedFlowTest \
-d ./flink-learning-1.0-SNAPSHOT.jar \
--input hdfs://node01:9000/flink/input \
--output hdfs://node01:9000/flink/output4/result.txt
常用的配置有:
-yn, --yarncontainer Number of Task Managers
-yqu, --yarnqueue Specify YARN queue
-ys, --yarnslots Number of slots per TaskManager
步骤:
1.启动hadoop分布式集群
2.运行提交任务的shell脚本
3.观察进程的情况,以及确认hdfs上的结果
- 实操
编写提交应用的shell脚本
flink run -m yarn-cluster -yn 2 -c com.jd.bounded.hdfs_hdfs.BoundedFlowTest \
-d ./flink-learning-1.0-SNAPSHOT.jar \
--input hdfs://node01:9000/flink/input \
--output hdfs://node01:9000/flink/output4/result.txt
在客户端执行shell脚本
[robin@node01 flink-learn]$ ./yarn-cluster-per-job-deploy.sh
2020-03-21 16:13:54,299 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-robin.
2020-03-21 16:13:54,299 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-robin.
2020-03-21 16:13:54,675 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node02/192.168.56.103:8032
2020-03-21 16:13:54,800 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-21 16:13:54,800 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-21 16:13:57,291 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored.
2020-03-21 16:13:57,291 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored.
2020-03-21 16:13:57,382 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-03-21 16:13:57,429 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=2, slotsPerTaskManager=2}
2020-03-21 16:13:57,435 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/module/flink/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
2020-03-21 16:13:59,326 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1584778326281_0001
2020-03-21 16:13:59,584 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1584778326281_0001
2020-03-21 16:13:59,586 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2020-03-21 16:13:59,590 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2020-03-21 16:14:06,435 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
2020-03-21 16:14:06,435 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - The Flink YARN client has been started in detached mode. In order to stop Flink on YARN, use the following command or a YARN web interface to stop it:
yarn application -kill application_1584778326281_0001
Please also note that the temporary files of the YARN session in the home directory will not be removed.
Job has been submitted with JobID e0d7f27ef42d7472466b14b13099dc93
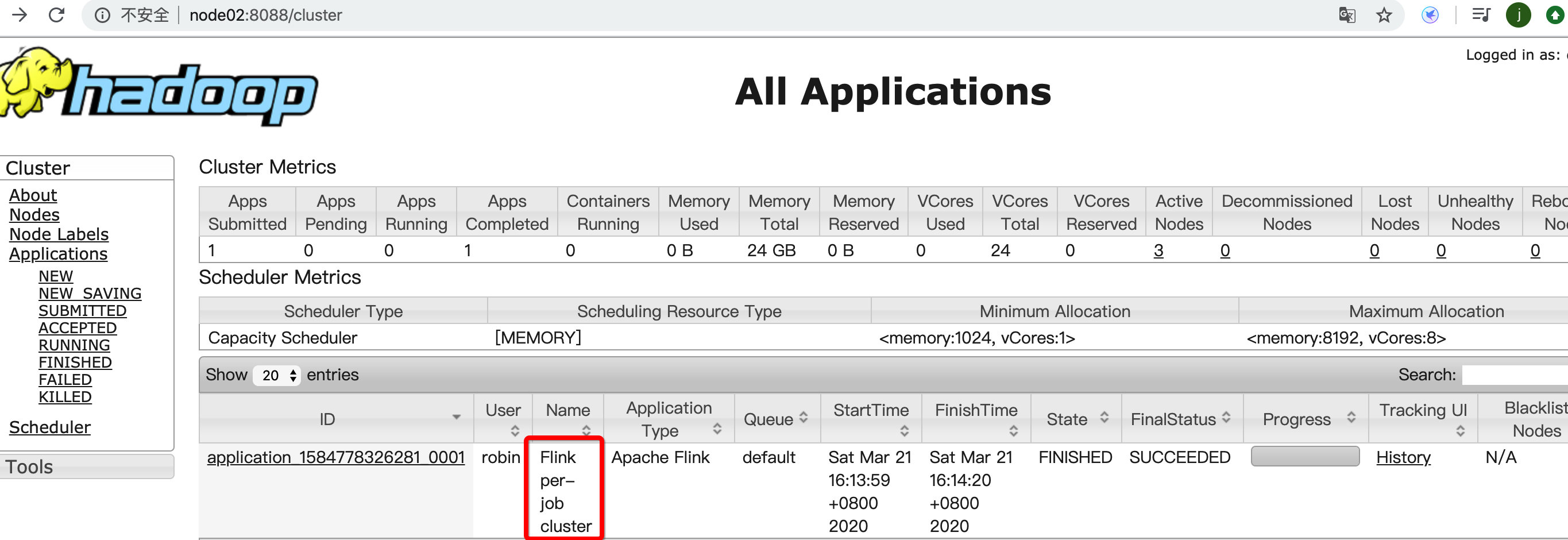
- 确认结果
yarn的后台管理界面查看
hdfs上结果查看
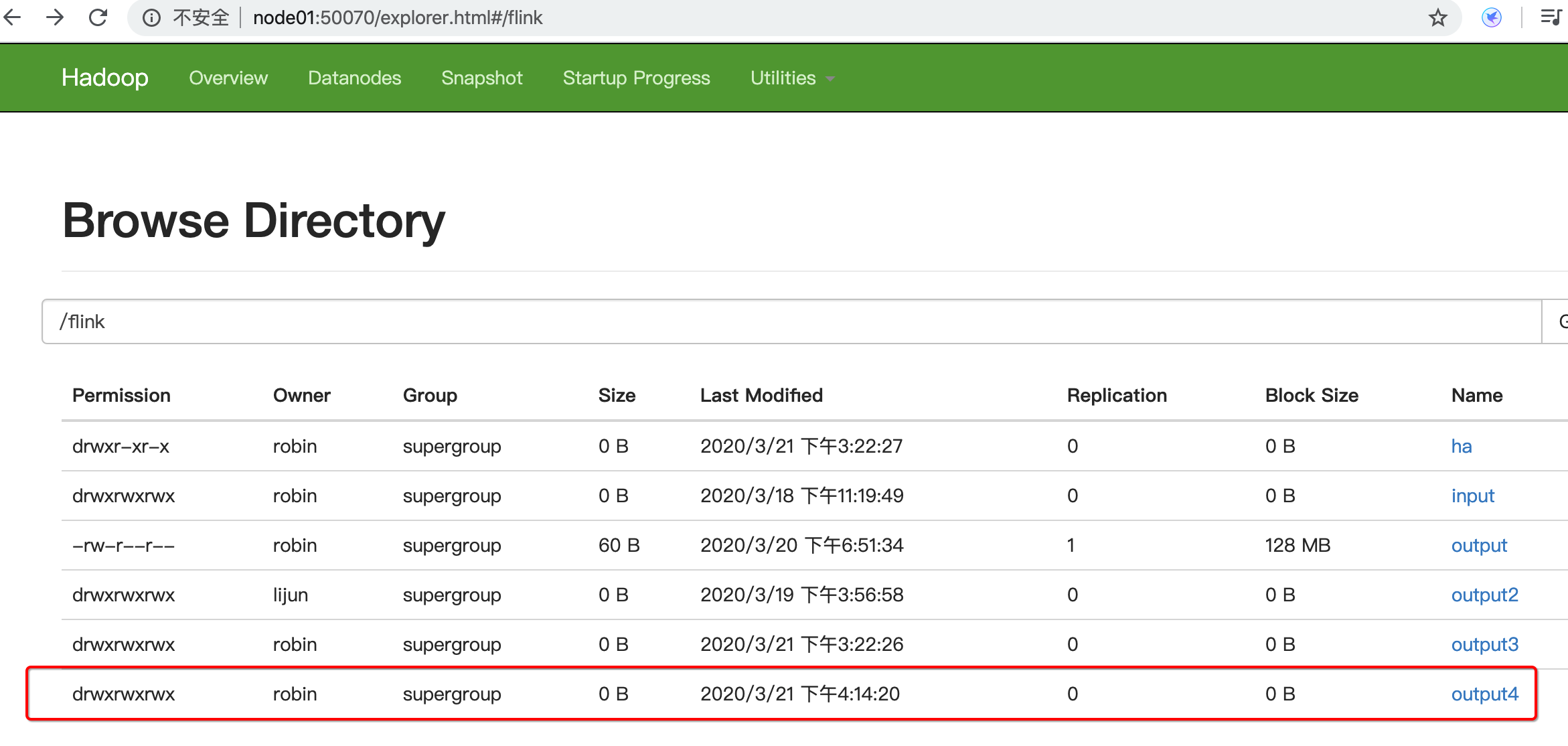
hdfs上结果内容查看


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









