






我们首先建立一个文件夹,在里面放入任意图片,就可以通过程序创建这些图片的特征库,然后使用摄像头实时识别和文件内相似的物体 不需要很多图片进行的机器训练,供初学者参考
例子 我首先建立一个文件夹,名字为 ImagesQuery,里面的图片如下图,图片任意 名字任意

然后创建我们的主程序:
import cv2
import numpy as np
import os
from PIL import Image, ImageDraw, ImageFont
import time
orb=cv2.ORB_create(nfeatures=1000)
def imread2(imagePathName): # 读取中文路径图片
retImg = cv2.imdecode(np.fromfile(imagePathName, dtype=np.uint8), -1)
return retImg
def putText2(img,text,pos,size=36,color=(255,0,0)):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype(font=r'simsun.ttc', size=size)
draw = ImageDraw.Draw(img_pil)
draw.text(pos, text, font=font, fill=color) # PIL中RGB=(255,0,0)表示红色
img_cv = np.array(img_pil) # PIL图片转换为numpy
img = cv2.cvtColor(img_cv, cv2.COLOR_RGB2BGR) # PIL格式转换为OpenCV的BGR格式
return img
#处理查找图片部分 创建使用该目录下的图片创建特征点 并用其名字作为分类
pathQuery="ImagesQuery"
imagesQuery=[]
classNamesQuery=[]
myList=os.listdir(pathQuery)
# print(myList)
# print("总共的分类数量:",len(myList))
for className in myList:
imgCurrent=imread2(f'{pathQuery}/{className}')
imgCurrent=cv2.cvtColor(imgCurrent,cv2.COLOR_BGR2GRAY)
imagesQuery.append(imgCurrent)
# print(className)
#提取文件名字部分 不包括扩展名
classNamesQuery.append(os.path.splitext(className)[0])
print(classNamesQuery)
#创建图片的描述符,传入需要创建描述符的图片名字列表
def findDescriptor(images):
#将所有模板图片的特征点及描述符计算出来,将描述符保存在一个列表中,作为以后的对比库
descriptorList=[]
for img in images:
keyPoint,descriptor=orb.detectAndCompute(img,None)
descriptorList.append(descriptor)
return descriptorList
def findID(img,descriptorList,thres=50):
#计算将要查找的图片(img)的特征点及描述符descriptor2
keyPoints2,descriptorToFind=orb.detectAndCompute(img,None)
#创建比较器
bf=cv2.BFMatcher()
#保存和查找图片的描述符与库中描述符匹配的结果 是符合的特征点数量
matchList=[]
finalValue=-1
#将查找的图片的描述符与已有的描述符库比较 找出匹配度高的描述符 并把匹配的描述符前面的特征点数量存入匹配列表中
try:
for descriptorInLibrary in descriptorList:
matches = bf.knnMatch(descriptorInLibrary, descriptorToFind, k=2)
goodMatchPoints = []
#遍历比较orb创建器中预设1000个特征点
for queryMatch,templateMatch in matches:
#距离误差度小于0.75的点保存起来 属于比较符合要求的点
if queryMatch.distance < 0.75 * templateMatch.distance:
goodMatchPoints.append([queryMatch])
#索引就是查找库中对应图片的位置
matchList.append(len(goodMatchPoints))
except:
pass
# print(matchList)
#找出匹配点最高的特征描述符
if len(matchList)!=0:
#如果比较处的特征点数量超过预设数量,则属于符合要求的描述符
if max(matchList) > thres:
finalValue=matchList.index(max(matchList))
return finalValue
#获取图片特征描述 获取所有图片的特征点 保存在一个列表中
descriptorsList=findDescriptor(imagesQuery)
# print(len(descriptorsList))
cap=cv2.VideoCapture(0)
pTime=0
while True:
success,img2=cap.read()
imgOriginal=img2.copy()
img2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
ids=findID(img2,descriptorsList)
if ids!=-1:
# cv2.putText(imgOriginal,classNamesQuery[ids],(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),5)
imgOriginal=putText2(imgOriginal,classNamesQuery[ids],(50,50),25,(0,255,0))
cTime=time.time()
fps=1/(cTime-pTime)
pTime=cTime
cv2.putText(imgOriginal, f"{int(fps)}", (20, 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
cv2.imshow("img",imgOriginal)
cv2.waitKey(1)
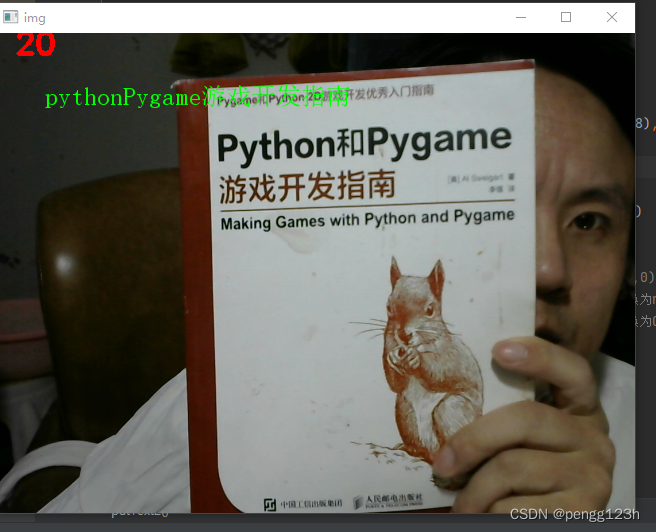
运行识别效果如下



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









