| 点击此处返回总目录 |----data | |---- cifar10 | |----get_cifar10.sh //下载数据集的脚本 | |----batches.meta.txt、data_batch_1~5.bin、test_batch.bin、readme.html //下载的数据集解压后的文件 | | |---CIFAR-10 |----create_cifar10.sh //将数据集转换为lmdb文件 |----cifar10_train_lmdb、cifar10_test_lmdb //lmdb文件 |----train_test.prototxt //网络结构文件 |----solver.prototxt //超参数文件 |----train_full.sh //训练脚本 |----cifar10_iter_10000.caffemodel、cifar10_iter_10000.solverstate等 //生成的model |----finetune.prototxt //用于微调的网络结构文件 |----finetune_solver.prototxt //用于微调的超参数文件 |----finetune.sh //对微调模型进行训练的脚本 |----extract_code.sh //暂时不知道干嘛的。 1. 下载数据集 caffe自带了下载cifar10的脚本,在data/cifar10下。//get_cifar10.sh 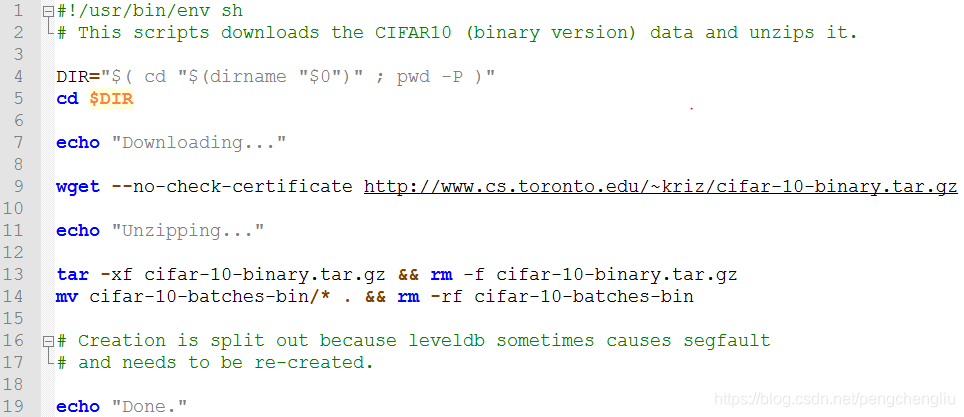
sh data/cifar10/get_cifar10.sh 执行后,在data/cifar10下可以看到解压好的数据集。 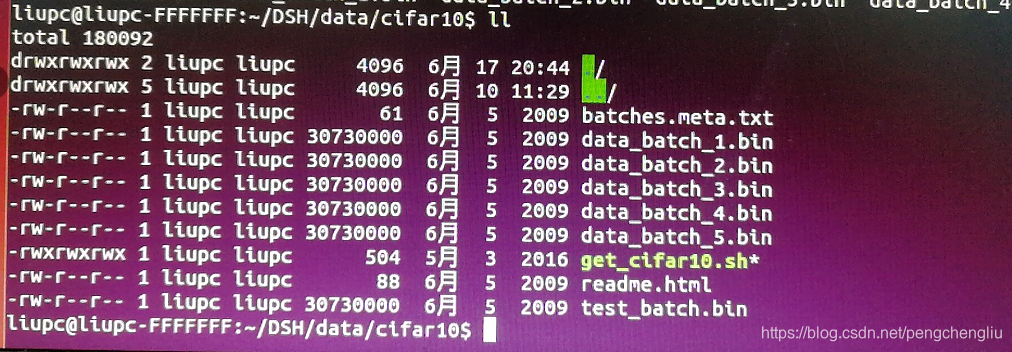
2. 将数据转换为lmdb格式 编写脚本CIFAR-10/create_cifar10.sh //create_cifar10.sh 
执行,可以看到在当前目录下有lmdb文件。 
3. 编写网络结构文件 CIFAR-10/train_test.prototxt
| name: "CIFAR10_full"
#layer {
# name: "cifar"
# type: "HashingImageData"
# top: "data"
# top: "label"
# image_data_param {
# source: "CIFAR-10/train.txt"
# root_folder: "/home/data/liuhaomiao/CIFAR-10/Train/"
# batch_size: 200
# cat_per_iter: 10
# }
# transform_param {
# mirror: true
# }
# include: { phase: TRAIN }
#}
#layer {
# name: "cifar"
# type: "ImageData"
# top: "data"
# top: "label"
# image_data_param {
# source: "CIFAR-10/test.txt"
# root_folder: "/home/data/liuhaomiao/CIFAR-10/Test/"
# batch_size: 100
# shuffle: false
# label_num: 1
# }
# transform_param {
# mirror: false
# }
# include: { phase: TEST }
#}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
data_param {
source: "CIFAR-10/cifar10_train_lmdb"
backend: LMDB
batch_size: 200
}
transform_param {
mirror: true
}
include: { phase: TRAIN }
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
data_param {
source: "CIFAR-10/cifar10_test_lmdb"
backend: LMDB
batch_size: 100
}
transform_param {
mirror: false
}
include: { phase: TEST }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
norm_region: WITHIN_CHANNEL
local_size: 3
alpha: 5e-05
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "pool2"
top: "pool2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
norm_region: WITHIN_CHANNEL
local_size: 3
alpha: 5e-05
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "pool3"
top: "ip2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu_ip2"
type: "ReLU"
bottom: "ip2"
top: "ip2"
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "ip2"
top: "ip1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 12
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "HashingLoss"
hashing_loss_param {
bi_margin: 24.0
tradeoff: 0.01
}
bottom: "ip1"
bottom: "label"
top: "loss"
} |
4. 编写超参数文件 CIFAR-10/solver.prototxt
net: "CIFAR-10/train_test.prototxt"
test_iter: 100
test_interval: 2000
test_initialization: false
base_lr: 0.001
momentum: 0.9
weight_decay: 0.004
lr_policy: "step"
gamma: 0.6
stepsize: 20000
display: 100
average_loss: 100
max_iter: 150000
snapshot: 10000
snapshot_prefix: "CIFAR-10/cifar10"
solver_mode: GPU |
5. 编写脚本进行训练 CIFAR-10/train_full.sh 
执行,开始训练。 训练结束后,会形成生成的模型。 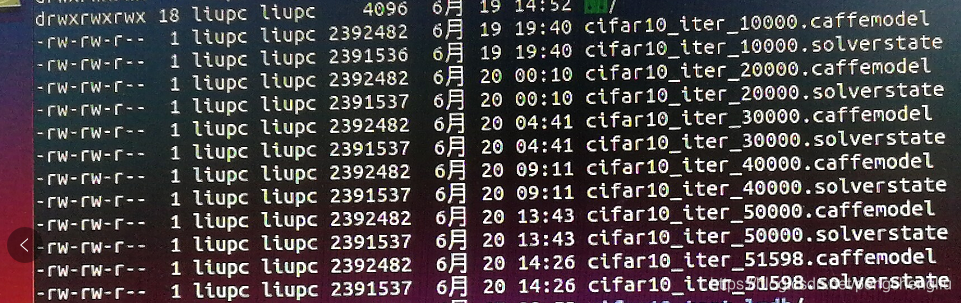
6.编写用于微调的网络结构文件 将train_test.prototxt拷贝一份为finetune.prototxt 修改以下内容: (1) 
(2) 
7. 编写用于微调的超参数文件 finetune_solver.prototxt
net: "CIFAR-10/finetune.prototxt"
#test_iter: 100
#test_interval: 1000
base_lr: 0.0001
momentum: 0.9
weight_decay: 0.004
lr_policy: "step"
gamma: 0.6
stepsize: 4000
display: 200
average_loss: 200
max_iter: 30000
snapshot: 10000
snapshot_prefix: "CIFAR-10/cifar10"
solver_mode: GPU |
8. 编写对微调的模型进行训练的脚本 finetune.sh 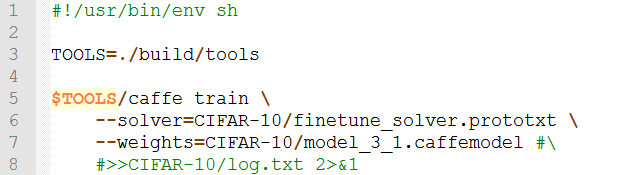
9. 执行提取二进制码的脚本(暂时不确定) extract_code.sh
| #!/usr/bin/env sh rm CIFAR-10/code.dat
rm CIFAR-10/label.dat build/tools/extract_features_binary CIFAR-10/cifar10_iter_150000.caffemodel CIFAR-10/train_test.prototxt ip1 CIFAR-10/code.dat 100 0
build/tools/extract_features_binary CIFAR-10/cifar10_iter_150000.caffemodel CIFAR-10/train_test.prototxt label CIFAR-10/label.dat 100 0 |
| 
























 5116
5116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









